Ingest Snyk vulnerability findings, scans, and audit logs
- Latest Dynatrace
- Extension
Prioritize Snyk vulnerabilities with runtime context from production.
Get started
Overview
Dynatrace integration with Snyk allows you to unify and contextualize vulnerability findings across DevSecOps tools and products, enabling central prioritization, visualization, and automation of security findings.
Snyk products (Snyk Code, Snyk Open Source, Snyk Container, Snyk IaC) generate vulnerability findings on development artifacts, such as code and containers. The Dynatrace platform observes the corresponding runtime entities associated with those artifacts. Ingesting and enriching vulnerability findings help users to better focus on the top risks that affect their production applications.
Use cases
With the ingested data, you can accomplish various use cases, such as
- Visualize and analyze security findings
- Discover coverage gaps in security findings
- Automate and orchestrate security findings
- Analyze and detect anomalous user activity Coming soon
Requirements
See below for the Snyk and Dynatrace requirements.
Snyk requirements
Generate an API token–based service account with the required organization-level permissions on each organization. This can be achieved by creating a custom role (recommended) or assigning the Organization Admin or Group Admin predefined role to the service account.
Required permissions: View organization, View audit logs, View container image, View project, View project history, View scans.
Dynatrace requirements
-
ActiveGate version 1.299+
-
Permissions:
- To run
 Extensions: Go to Hub, select Extensions, and display Technical information.
Extensions: Go to Hub, select Extensions, and display Technical information. - To query ingested data:
storage:security.events:read.
- To run
-
Tokens:
- Generate an access token with the
openpipeline.events_securityscope and save it for later. For details, see Dynatrace API - Tokens and authentication.
- Generate an access token with the
Activation and setup
-
In Dynatrace, search for Snyk and select Install.
-
Follow the on-screen instructions to configure the extension.
-
Verify configuration by running the following queries in
 Notebooks:
Notebooks:-
For audit logs:
fetch logs| filter log.source=="Snyk" -
For finding events:
fetch security.events| filter dt.system.bucket == "default_securityevents"| filter event.provider=="Snyk"AND event.type=="VULNERABILITY_FINDING" -
For scan events:
fetch security.events| filter dt.system.bucket == "default_securityevents"| filter event.provider=="Snyk"AND event.type=="VULNERABILITY_SCAN"
-
-
Once the extension is installed and working, you can access and manage it in Dynatrace via
Extensions. For details, see About Extensions.
Details
How it works
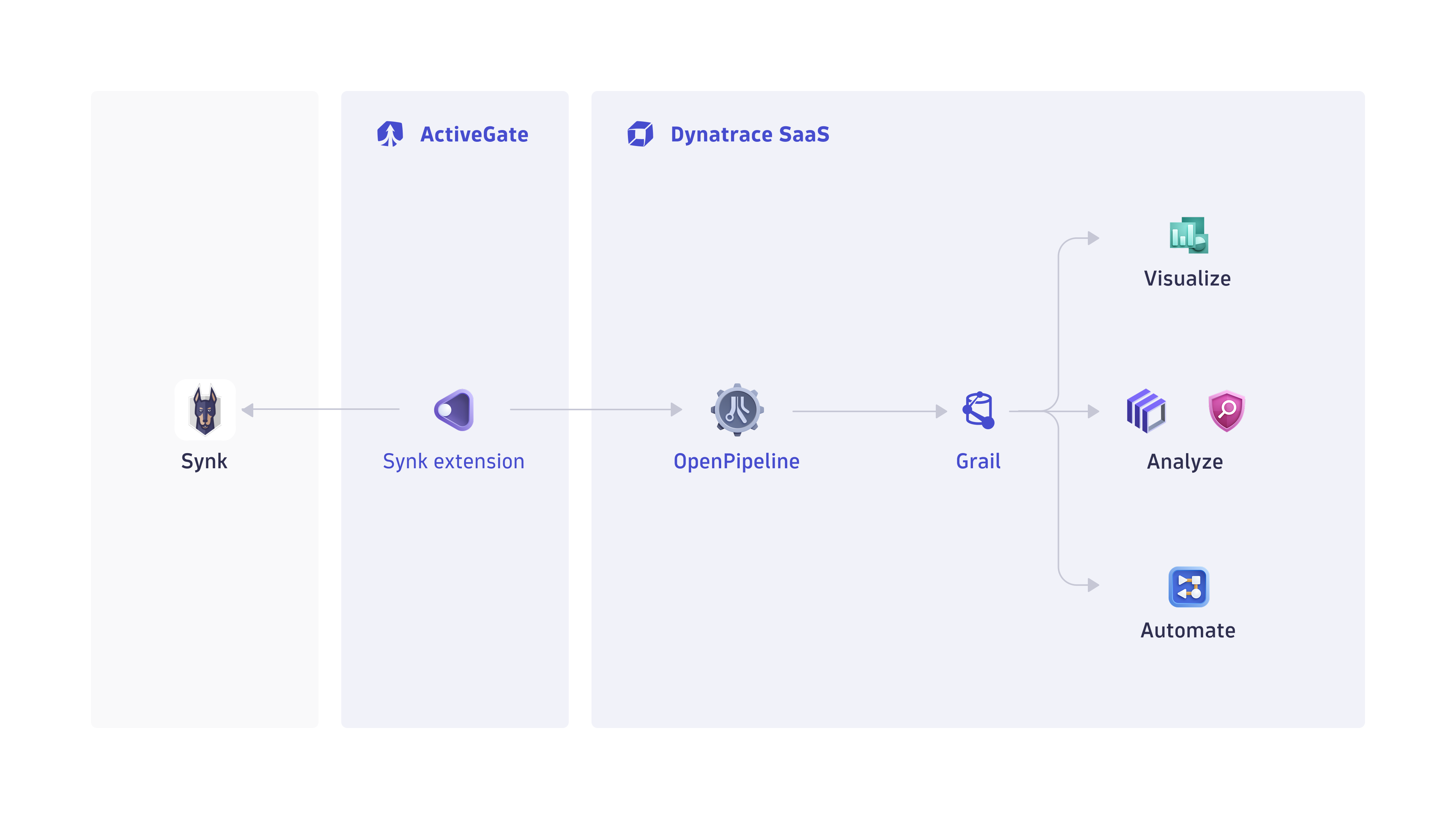
Dynatrace integration with Snyk is an extension running on Dynatrace ActiveGate. Once you enable and configure the Dynatrace Snyk extension
-
It periodically reaches out to Snyk products and fetches the new vulnerability findings, scans, and audit logs.
-
The fetched data is ingested into Dynatrace and mapped to the Dynatrace Semantic Dictionary.
-
Data is stored in a bucket called
default_securityevents(for details, see Built-in Grail buckets).
Licensing and costs
For billing information, see Events powered by Grail.
Feature sets
When activating your extension using a monitoring configuration, you can limit monitoring to one of the feature sets. To work properly, the extension has to collect at least one metric after the activation.
In highly segmented networks, feature sets can reflect the segments of your environment. Then, when you create a monitoring configuration, you can select a feature set and a corresponding ActiveGate group that can connect to this particular segment.
All metrics that aren't categorized into any feature set are considered to be the default and are always reported.
A metric inherits the feature set of a subgroup, which in turn inherits the feature set of a group. Also, the feature set defined on the metric level overrides the feature set defined on the subgroup level, which in turn overrides the feature set defined on the group level.
FAQ
Which data model is used for the security logs and events coming from Snyk?
-
Vulnerability finding events store the individual vulnerability findings reported by various Snyk products per affected artifacts and components.
-
Vulnerability scan events indicate coverage of scans for individual artifacts.
-
Audit logs represent user activity logs in Snyk products.
Which extension fields are added to the core fields of the events ingested from Snyk?
-
The
container_imagenamespace is added for container findings and scans to store all the container image-related information. -
The
snyknamespace is added to extract several Snyk-specific attributes on top of the original JSON, which is stored in theevent.original_contentfield.Examples:
snyk.org.name,snyk.project.name,snyk.project.tags,snyk.target.name,snyk.target.reference, and others.
Which Snyk issues are imported into Dynatrace?
-
If the extension is configured to ingest data at an interval of
nhours, then whenever the extension runs an ingest, all open issues belonging to projects that had a snapshot taken of them in the lastnhours will be ingested (on the first ingest, Dynatrace considers all the issues in the previousmhours, wheremis the first ingest interval configured in the monitoring configuration). -
If during the last
nhours, multiple snapshots were taken for the same project, one set of findings will be ingested for each snapshot. -
If no snapshots were taken for a project, no findings will be ingested, even if the project has open issues.
Why doesn't the number of vulnerability findings in Dynatrace match the number of issues in Snyk?
As explained above, issues are ingested each time a project snapshot runs, meaning that if an issue wasn't marked as resolved between snapshot runs, Dynatrace will ingest it twice.
To comply with the Dynatrace Semantic Dictionary, some Snyk issues are split into multiple vulnerability findings when ingested into Dynatrace.
To count the number of Snyk issues from the data in Dynatrace, you can use a | dedup snyk.issue.id command.
What Snyk asset types are supported by Dynatrace for runtime contextualization?
CONTAINER_IMAGE: All the findings from Snyk Container coming from the assessment of container images are mapped with the CONTAINER_IMAGE value in the object.type field, and the container_image namespace is added with the corresponding fields:
-
container_image.digestis set to the container image digest. This value can be used to match the runtime containers.For some containers, for example, containers import into Snyk from CLI, the digest is not available.
-
container_image.repositoryrepresents the container repository name. -
container_image.registryrepresents the container registry name. -
container_image.tagsrepresents the tags set on the container image. -
container_image.idrepresents the ID of the container image.
For some of the images, for example, those imported from CLI, Snyk doesn’t report the container image digest. By default, container_image.digest is used for runtime contextualization, but for these cases, container_image.id might need to be used.
How is the risk score for Snyk findings normalized?
Dynatrace normalizes severity and risk scores for all findings ingested through the current integration. This helps you to prioritize findings consistently, regardless of their source. For details on how normalization works, see Severity and score normalization.
The Dynatrace risk levels and scores are mapped from the original Snyk severity and score.
-
dt.security.risk.levelis taken from the Snyk severity level and mapped from the original values infinding.severity. -
dt.security.risk.scoreis taken from the Snyk severity level and mapped to static scores. The CVSS score (CVSS v3 or v4, for vulnerabilities reported after 2024) reported by Snyk is available infinding.score; however, this may not always match the reported severity.
dt.security.risk.level (mapped from finding.severity) | dt.security.risk.score (mapped from dt.security.risk.level) |
|---|---|
critical -> CRITICAL | 10.0 |
high -> HIGH | 8.9 |
medium -> MEDIUM | 6.9 |
low -> LOW | 3.9 |
