Include data in segments
- Latest Dynatrace
- Explanation
- 5-min read
Segments can logically structure and serve as convenient filters when analyzing data in different apps. Segments are constructed based on rules, called Includes. Learn how data of different types can be included in segments.
Key terms
- Include
Single rule, referencing data to be included in segment. Querying for data not explicitly referenced by any include of the selected segment, will lead to empty results.
- Signal
Observed data point, emmitted by a monitored entity. Available signal types in Dynatrace are
logs,metrics,events,spans, and others.- Monitored entity
Logical component monitored by Dynatrace, persisted as Smartscape node and/or classic entity.
- Smartscape node
Node topology objects, similar to entities on the Dynatrace cluster. Nodes are a collection of all kinds of entities, regardless of their type.
- Classic entity
Application, service, process, host, or data center entity stored on the Dynatrace cluster (such as
dt.entity.host,dt.entity.service,dt.entity.kubernetes_cluster). Classic entities are bound to a type.
Includes
Segments are constructed incrementally through includes, step by step, extending the scope of the segment. Includes reference a certain data type and are defined by a filter condition for data of that type.
In its initial state, logically speaking, a segment can be considered empty. To use a segment for filtering, data needs to be included.
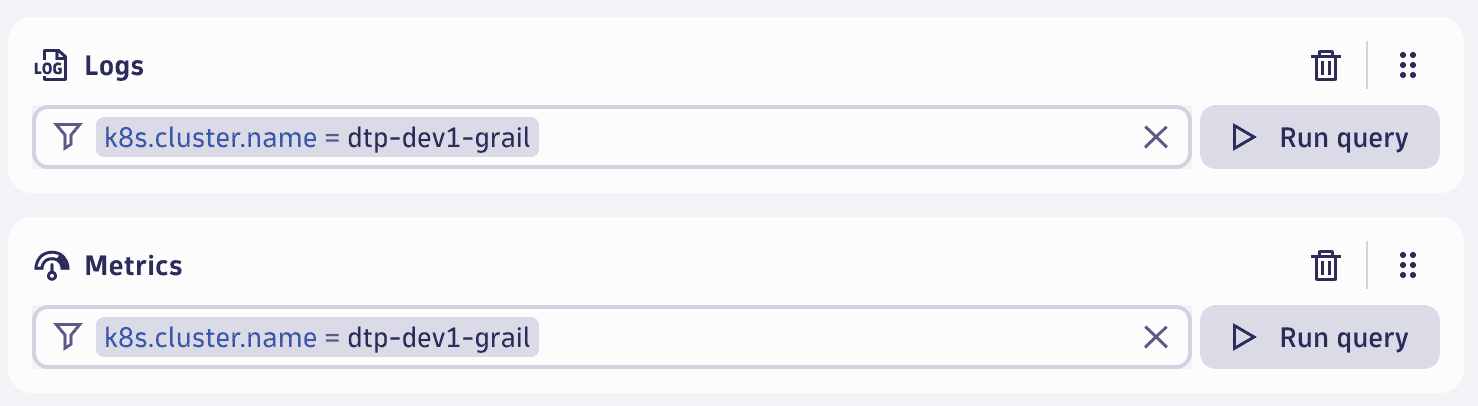
In the following example, two include blocks were added to include logs and metrics by the given conditions. This illustrates how includes incrementally extend the scope of a segment.
Include blocks are ORed together.
You can drag include blocks up and down in the web UI, but this affects only the order in which they are displayed in the UI, and does not influence which data is included in the segment.
Logical conditions within a single include can of course be more complex than simple equals-matches conditions as shown above.

Conditions of segment includes are evaluated at query time, directly impacting query performance. Make sure to consider  OpenPipeline to process fields and simplify complex conditions.
OpenPipeline to process fields and simplify complex conditions.
Data types
Signals
Collecting observability signals is at the core of Dynatrace, so you need to understand their schema and build segments around how those signals are shaped.
Signals can be included in segments in a number of ways. For the better efficiency of resulting filter expressions, always try to reference them directly.
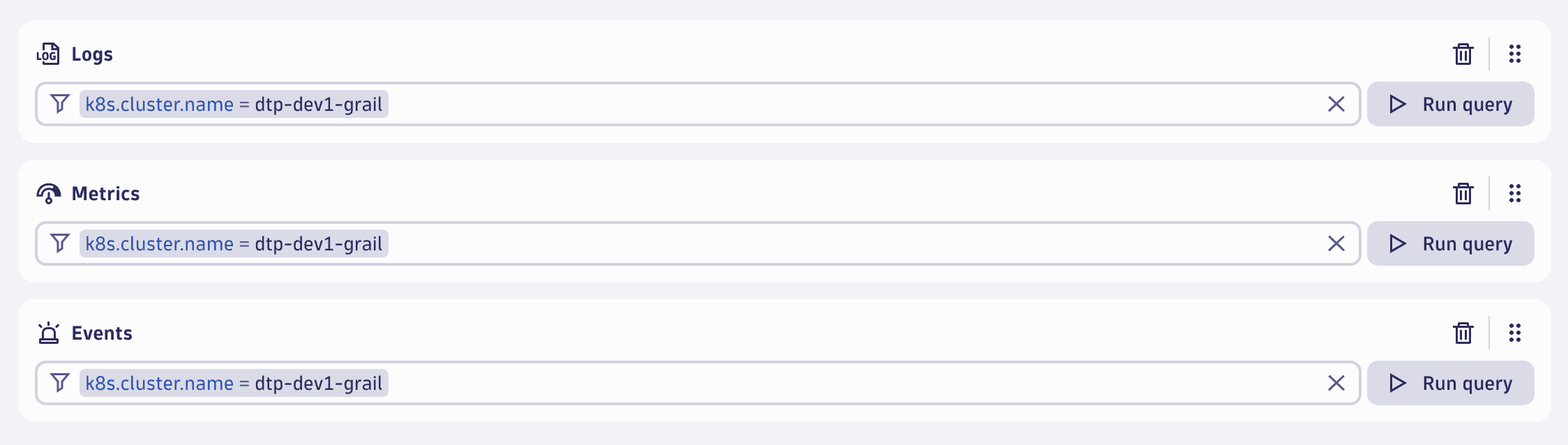
Configurations like the one above can also be expressed more elegantly using the All data types option:

Since context matters, and the unique monitored entity model in Dynatrace provides an alternative way to work with observability signals, there is a second option to include signals through entity-to-signal relationships.
Entity-to-entity relationships
Entity relationships in segments are only supported for backward compatibility with classic entities.
A further benefit of segments in regards to monitored entities is being able to leverage relationships between them.
While working with entities stored as Smartscape nodes in Grail has multiple benefits, it's sometimes necessary to construct segments for classic entities. For instance, this enables having segments that include Kubernetes workloads or other monitored entities of higher cardinality, filtered by their related Kubernetes clusters.
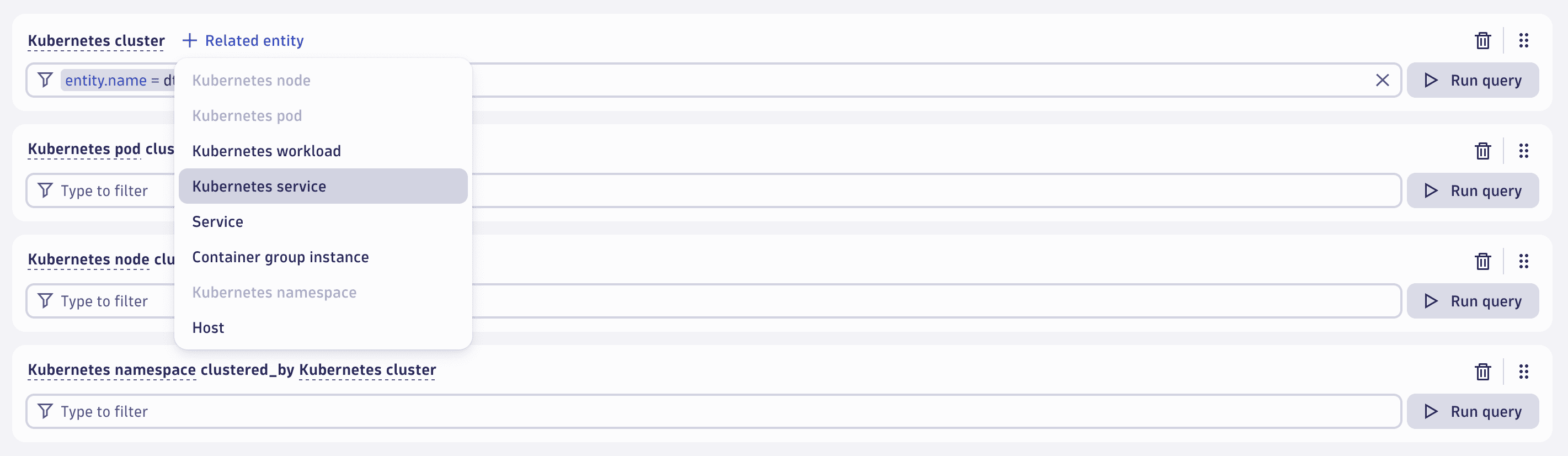
Segments allow a single relationship traversal step only. However, multiple parallel relationships of the same originating entity can be configured.