Variables in segments
- Latest Dynatrace
- Explanation
- 3-min read
Segments support variables to form dynamic conditions of include blocks. This allows deduplication of segments, covering similar instances in one single segment.
Key terms
- One-off segment
Segment configured with static conditions for a one-off scenario.
- Dynamic segment
Segment configured with dynamic conditions using variables.
- Variable query
DQL query used to populate variable values.
Variable usage
In the following example, the variable $bucket is set to default_logs, so the include statement that follows it resolves to dt.system.bucket = "default_logs".
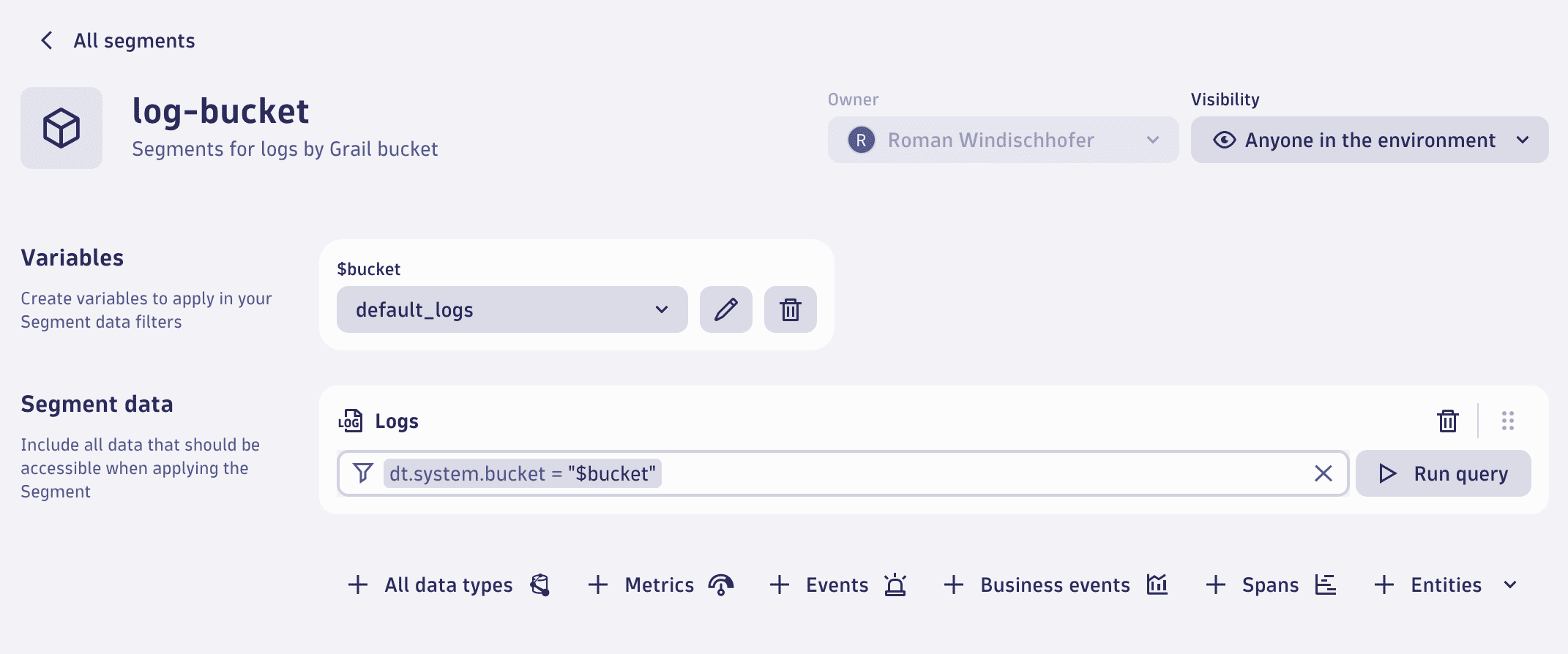
Variable configuration
Variable values can be configured dynamically or statically. The following example uses a DQL query to fetch a dynamic list of Grail buckets containing logs.
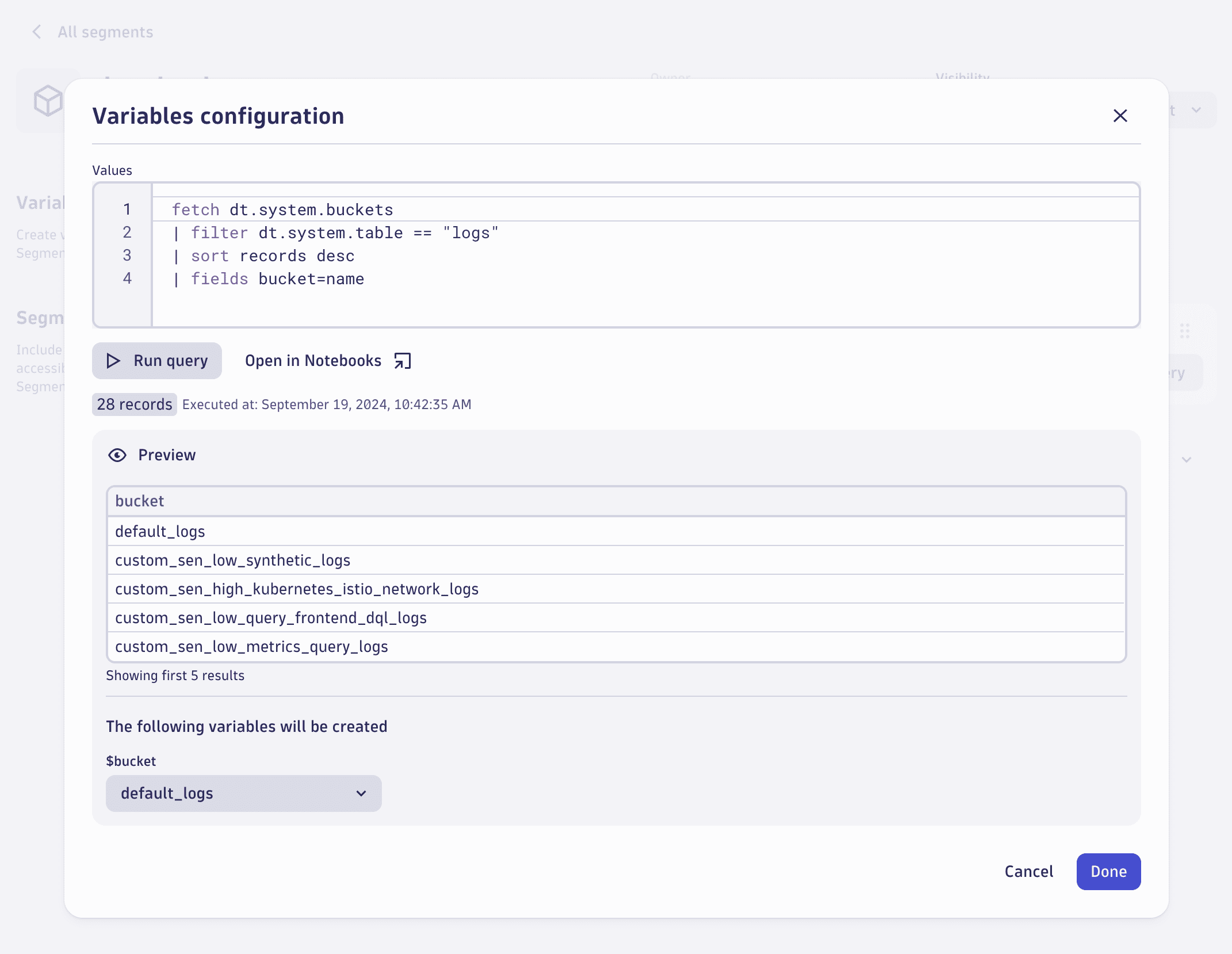
A similar result can be achieved by using DQL's data command to form a static list of values as shown below.
datarecord(bucket="custom_sen_high_kubernetes_istio_network_logs"),record(bucket="custom_sen_low_logs_platform_service_shared"),record(bucket="custom_sen_low_query_frontend_dql_logs")
Whether to configure variables to form dynamic or static lists of values depends on preference and specific requirements.
Avoid replicating entity lookups through segment variables filtering on entity IDs. Variables should be used to list values of a dimension that the segment is modeled around, for example, aws-region.
Primary and secondary variables
Variables can be used to model a segment along a single dimension. That single dimension will be the primary variable and is identified by the first column of the variable query's result set. Primary variables will account for the list of suggested values when using the segment to analyze data.
On top of that, secondary variables can be used to account for variance of required conditions in segment includes. Think of secondary variables as further columns in the result set of a variable query. Secondary variables are strictly tied to the selection of the primary variable value when using the segment to analyze data. Think of it as selecting a full row with all its columns.
The following example will result in a primary variable $name and a secondary variable $key.
datarecord(name = "istio_network", key="custom_sen_high_kubernetes_istio_network_logs"),record(name = "platform_service", key="custom_sen_low_logs_platform_service_shared"),record(name = "dql_query_frontend", key="custom_sen_low_query_frontend_dql_logs")
Variables and wildcards
Neither variable names nor variable values are allowed to contain the wildcard character *. In conditions of segment includes, however, the wildcard character can follow a variable name to form a starts-with condition, such as k8s.cluster.name = $cluster*.
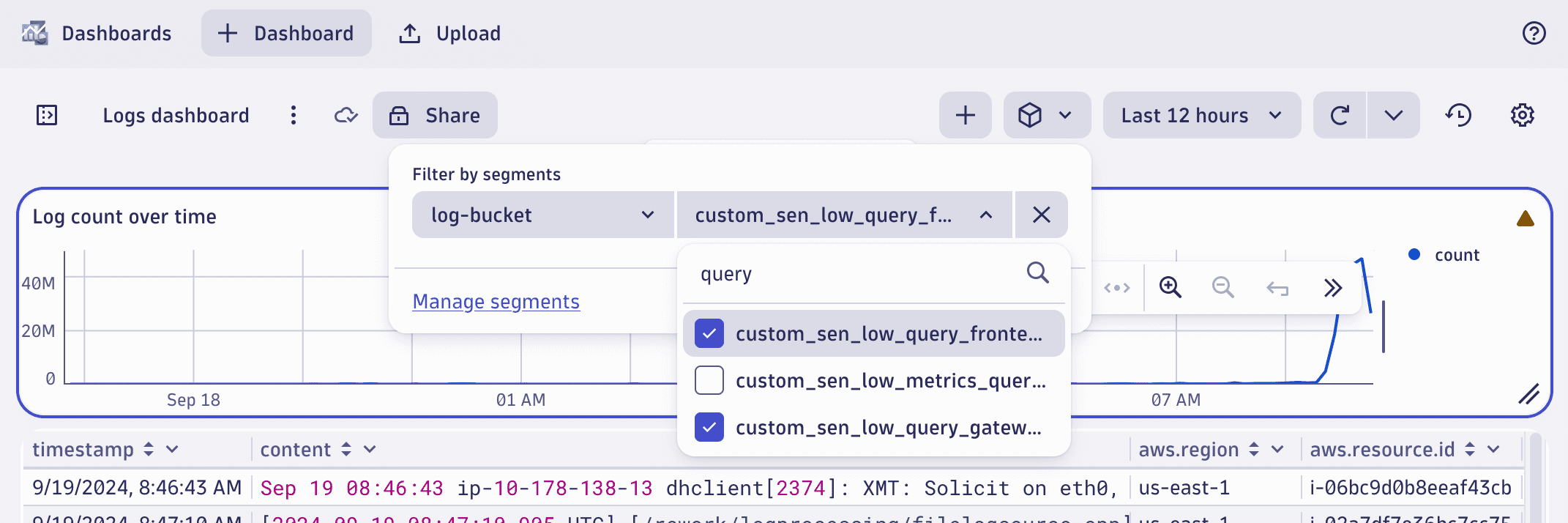
Analyzing data using dynamic segments
Segments configured to use variables present a second selection step when being used to analyze data in apps. In our example, that second selection allows analyzing logs by selecting one or more buckets from the list.
Variable query execution
When dynamic segments are used to analyze data, the variable query is executed in the context of the effective user. Users of this segment will therefore need appropriate permissions to access data queried to populate the list of values. If users lack required permissions, the list of values to select from would be empty.
Since variable queries are executed on explicit user interaction, they won't have a significant impact on license consumption. It's still advisable to avoid querying high-volume data types, such as logs.