Platform Engineering
- Latest Dynatrace
- 24-min read
Gartner1 predicts that by 2026, 80% of large software engineering organizations will establish platform engineering teams as internal providers of reusable services, components, and tools for application delivery, up from 45% in 2022.
What is platform engineering?
Platform engineering is a modern, core engineering discipline that has emerged to accelerate the development and deployment of software that is resilient and effective at scale.
The goal is to operationalize DevSecOps and SRE practices by providing an internal self-service platform with development workspace templates to reduce the cognitive load on engineering teams and provide fast development feedback cycles out of the box.
An internal developer platform (IDP) encompasses a set of tools, services, and infrastructure that enables developers to build, test, and deploy software applications. These platforms are tailored specifically to an organization's needs, demands, and goals.
Through the development, deployment, and maintenance of these IDPs, platform engineering teams deliver:
- Increased innovation and development speed
- Better developer experience
- Higher developer productivity
- Reduced infrastructure costs
- And more
IDPs allow teams to shift more of their time and effort to delivering best-in-class products to their end customers.
Effective IDPs
The majority of IDPs are containerized and built on top of Kubernetes-centric infrastructure with a core set of technologies. The diagram below maps out what a basic IDP should include.
Features of a strong and effective IDP:
Crucial capabilities of an IDP are provided as self-service to development teams. Some of these self-service capabilities might include:
- Platform services (service mesh, data storage, security vaults, policy agents)
- Delivery services (continuous integration, continuous delivery, Git, GitOps)
- Observability services for monitoring, automation, and security
- Templates for development workspaces including all the above
Platform engineering also offers the ability to:
- Automate key workflows like validation
- Achieve optimal performance and security
- Ensure the platform is working as expected and resources are being used in an optimal manner
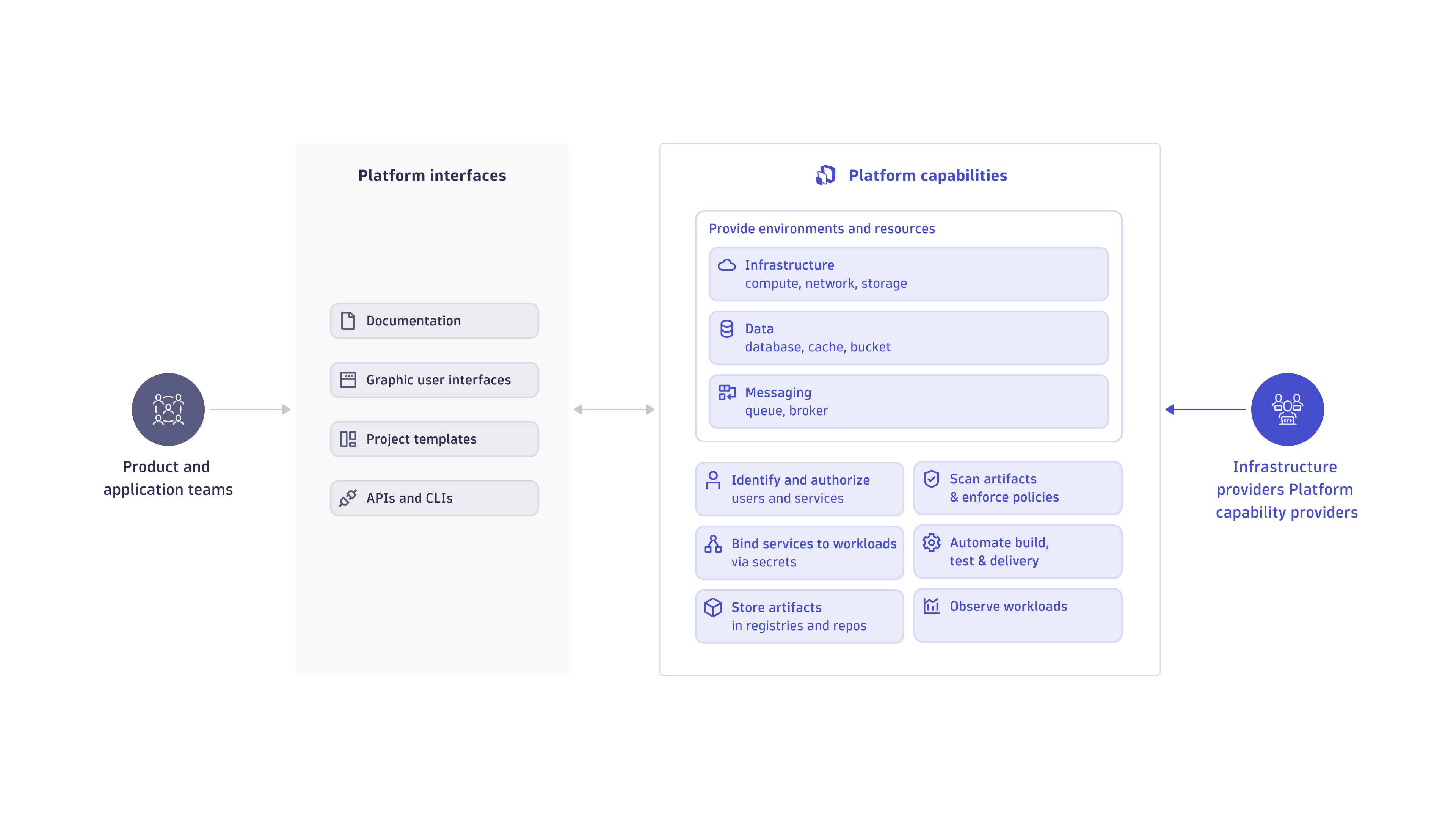
Source: https://tag-app-delivery.cncf.io/whitepapers/platforms/
Treat your platform as a product
A key aspect of platform engineering is approaching your platform with a product management mentality. Every aspect should be meticulously designed and optimized for the benefit of the user: the developer.
Looking at an IDP with a product management lens
-
The product: An internal development platform (IDP) built to provide self-service for infrastructure, services, and support for the development teams as they build, test, and deploy applications at scale
-
The customer: Development teams who want to accelerate the production of high-quality, resilient apps — with low effort for onboarding for new applications and new developers
Maturing DevOps with platform engineering
You build it, you run it doesn’t scale anymore.
DevOps alone doesn’t meet the demands of cloud-native software development. Platform engineering is DevOps applied at cloud-native scale.
Effective DevOps supports cross-functional cooperation and boosts efficiency. Platform engineering builds on traditional DevOps practices but goes a step further.
By providing a framework and techstack to apply DevOps principles at scale with Kubernetes-centric infrastructure, platform engineering allows organizations to realize many of the benefits DevOps promised to deliver.
In practice, maturing DevOps into platform engineering involves providing centrally maintained development tooling, templates for CI/CD toolchains, processes, and application lifecycle orchestration solutions via a unified platform that development teams can use for greater efficiency. It enables a frictionless developer experience with minimum overhead, reducing cognitive load and providing fast feedback out of the box.
Platform engineering’s standardized processes and technologies across development and operations teams lead to significant gains in developer productivity and improvements in developer experience.
Additionally, the platform engineering approach allows organizations to take advantage of economies of scale, consolidating sprawling tech stacks to:
- Manage cost
- Optimize resource usage
- Improve governance
Cloud-native platforms require a new approach to observability
To be broadly adopted by internal development teams and deliver on its promise of unlocking DevSecOps at scale, a Kubernetes-centric IDP requires other services and components to tackle challenges related to:
- Visibility
- Resource utilization
- Security
- Orchestration
- Collaboration
Top engineering teams unlock faster deployments and fewer errors by empowering developers to manage their own deployments. Enabling self-service requires developers to be able to debug code quickly, which isn’t easy in complex environments. Observability makes all the difference.
Observability isn’t just about the user-facing application. Effective platform engineering—as DevOps at cloud-native scale—enables self-service for developers or development teams, and that self-service often requires automation in the background. To provide guard rails and make the system governable, it must be observable.
When implemented properly, platform engineering brings end-to-end observability to the full software development lifecycle, from development to release, to operation, and eventually to retirement.
Implementation
Fortunately, organizations don’t have to replace every tool, vendor, and practice to implement platform engineering. DevOps and cloud-native processes often continue managing systems and pipelines and working on automation and self-service.
Benefits
Accelerate development and support developer productivity
More than two-thirds of all organizations (68%) implementing platform engineering have already realized an increase in development velocity.
Organizations with platform engineering teams see various benefits to their speed and efficiency. They report a variety of benefits, notably:
- Improved system reliability
- Improved efficiency and productivity of work
- Faster delivery time
Improve developer experience
A best-in-class developer experience gives your organization a strategic advantage.
- Reduces the cognitive load of the developer
- Reduces overall burden on the operations team
- Improves quality of services from internal IT operations resources, processes, and practices
- Provides a more efficient path for product delivery
- Provides fast feedback cycles to developers
Optimize resources and mitigate cost
With a shared pool of resources for all projects, standardized practices, and the power of AI, platform engineering optimizes resource usage, leverages economies of scales, and mitigates cost.
Standardize tech stack to minimize risk and increase governance
Effective platform engineering enables teams to keep complexity low, standardize delivery, and still allow for autonomy and freedom.
- Security and compliance are built in by design of the platform components and services.
- Golden Path templates standardize delivery – providing governance.
- Identification and remediation of issues or misconfigurations across templatized and standardized services becomes quick and easy.
The minimum viable platform: BACK stack + observability
If you were to start from scratch, only with a Git and CI tool in place, a simple beginning could be to work with the BACK stack:
- Backstage
- Argo
- Crossplane
- Kyverno
The BACK stack includes the artifact delivery and security as well as the configuration and developer portal, but that’s not all it takes. Observing the workloads is equally important and must be included in a minimum viable platform.
To feed the observability and security data back to the developers, we offer a Backstage integration with Kubernetes support by default and customizable queries.
OpenTelemetry offers open-source observability, and Dynatrace can be used for observability either out of the box with our proprietary OneAgent or by easily ingesting and using the data provided through OpenTelemetry.
Core platform observability and security principles
Kubernetes is a good starting point for building a platform, allowing platform engineering teams to provide self-service capabilities and features to their DevSecOps teams. However, it also introduces complexity to the cloud environment.
Organizations need the automatic answers and insights that observability and security analytics provide to manage and overcome the complexity introduced by today’s business needs and complex multi-cloud-native environments.
Follow these core principles when building your Internal Developer Platform (IDP) to manage an application or service throughout its Software Development Lifecycle (SDLC).
1. Core platform observability
A critical first step in achieving actionable platform insights is ensuring monitoring of the artifact (service or application) as well as the full software development lifecycle and the underlying IDP:
- Artifact: How does my product behave in various environments (staging, testing, production)?
- Platform Toolstack: What is the health and utilization of the tools in use (e.g. BACK stack)?
Treating (critical) platform services like any other business-critical service allows for easy and effective incident triage, issue resolution, and improved developer experience.
Some aspects of core platform observability
- Ensuring resiliency, availability, and security by applying the same practices to all platform services
- Optimizing usage, performance, and licensing to positively impact the application lifecycle and reduce cost
- Detecting misconfiguration or misuse by discovering upcoming problems and issues, used to educate users.
2. Release information
Attaching the current version and stage information to services allows for easy triaging and resolution of issues. This can be done by promoting the version and stage information to Kubernetes containers as environment variables or annotations.
3. Pipeline efficiency
While the platform tool stack monitoring outlined in the previous paragraph covers the health of the IDP, it does not yet cover the efficiency of the pipeline. This is where logs, events, and telemetry data from pipeline or workflow executions come in.
By analyzing pipeline or workflow logs, events, and traces, it’s possible to create metrics (for example, DORA metrics) that can be used for benchmarking and deciding where to invest time or resources for improvement.
Most used tools in a cloud-native environment already emit events or telemetry data, but this area currently lacks dedicated standards and semantic conventions.
4. Ownership information
When looking at artifacts, responsibility is a critical piece of information. Who is responsible for an application or service in production, and who owns security?
This was often maintained in CMDBs, Excel sheets, or active directories. However, it's wise to manage this information proactively and automatically in cloud-native environments with constant updates and changes.
One way to do this is through Kubernetes labels and annotations, ensuring out-of-the-box availability of this critical information across the lifecycle.
5. AI Observability
With the rise of generative AI in DevOps Portals and IDP tools, providing observability for these systems is growing to efficiently drive the experience they provide while keeping costs in check.
Platform Engineering use cases
With effective platform engineering, everything is available in self-service through Golden Paths (templates). Self-service provides autonomy for rapid, secure innovation while maintaining guard rails for consistency and enabling governance.
We have categorized use cases with a product-lifecycle-centric view, rather than a platform-centric view, to emphasize the ease of adoption of use cases for platform engineering teams and cases in which no formal platform engineering team has been established.
Develop - Release - Operate - Predict - Prevent - Resolve - Protect - Improve
All of the following use cases are available to the platform engineering team to make their work observable and easier, or for the platform engineering team to provide automation and self-service capabilities to their users—the development teams.
Develop
This category contains all activities around planning, developing, building, and testing services and applications on an Internal Developer Platform (IDP) provided by a platform engineering team.
 Test pipeline observability
Test pipeline observability
- Goal
From millions of test events to a single source of truth.
Provide observability into test results automatically across different used tools and ensure all test results are available in a single source of truth.
- Increase efficiency and insights through test observability
- Ingest test events and metadata into a single unified observability platform
- Visualize test results and KPIs in one central view or dashboard
- Identify long lasting tests to easily optimize for faster test feedback
Try it yourself: Test pipeline observability.
 Continuous testing validation
Continuous testing validation
- Goal
120X reduction in evaluation times from days to minutes.
Testing is often highly automated already, but teams still frequently test in siloes.
To ensure high quality customer experience automatically and proactively:
- Combine, continuously evaluate, and baseline test results from testing tools
- Incorporate SLOs, security findings and synthetic tests
- Reduce the number of manual operations by engineers to verify quality of new release
- Easily integrate CI/CD delivery pipeline with tools like Dynatrace Synthetic Monitoring to ensure that new releases where all critical user journeys work as expected
 Observability-driven development
Observability-driven development
- Goal
Mean Time to Observability reduction from hours to seconds.
In the previous section, we outlined the importance of covering ownership and release information early in the lifecycle by extending the provided metadata to include observability and security rules, SLOs, and even automation and remediation steps.
Standardizing these based on technology, team, or criticality of service enables the use of simple as-code templates as Golden Paths, ensuring consistency and governance across the lifecycle.
Standardizing across teams can:
- Bring observability and transparency to development teams out-of-the-box
- Provide real-time insights into what's happening
- Conduct observability and reliability checks at an early stage to enable faster reaction to potential issues before they reach production
- Increase accountability of application teams and empower them to get early insights in their implementations
- Provide autonomy while having consistent rules for the same criticality of service
Release
This category contains all activities around releasing and deploying in environments along the Software Development Lifecycle (SDLC).
Release validation
- Goal
Reduce change failure rate and reduce production deployment lead time by up to 99%
Automatically validate new releases — taking downstream and upstream dependencies into account — based on baselining, observability data, SLOs, and security information. Use the results to drive meaningful follow-up actions. Providing release validation templates as part of every delivery process enables fast feedback regarding any negative side-effects of a new version. Faster feedback leads to better developer experience, higher release quality, and higher innovation pace.
Try it yourself: Release validation.
 Progressive delivery
Progressive delivery
- Goal
90-99% reduced problem exposure with progressive delivery.
Releasing updates and new versions of an application or service in a gradual and controlled manner can help teams provide fast, secure, and high-quality services without disrupting business.
Based on the observability data, including SLO trends and synthetic checks, an automated progressive delivery release like canary or blue/green can be established.
- Automated workflow execution to control the software delivery
- Direct Kubernetes interactions to apply configuration changes
- Governance for the delivery process by leveraging events
- Targeted notifications to inform the team in charge of the delivery process
 Pipeline observability
Pipeline observability
- Goal
100% real-time standardized coverage of your software lifecycle health.
People often say, you can’t manage what you can’t measure. The statement holds true for the software development lifecycle as well. To calculate critical metrics, such as lead time for change, it's important to take note of the pipeline telemetry data.
Using pipeline observability, the data (for example failed builds, lead time) can be calculated and acted upon automatically. With automated data, these metrics—like the DORA metrics lead time for change, deployment frequency, change failure rate, and mean time to resolve—are readily available in several dimensions, including application/service, platform service/pipeline, and technology and ownership.
In addition to metrics, logs and traces of pipeline runs can help debug erroneous pipelines or identify time-consuming hotspots that can be optimized for more efficient pipelines.
Operate
This category contains activities around monitoring and operating services and applications in production environments.
 Cloud cost optimization
Cloud cost optimization
- Goal
Reduce cross-zone network traffic by up to 55%.
By combining network data with infrastructure and billing information, top cost contributors can be identified and analyzed, leading to improvements by pinpointed adoption of network compression or other hyperscaler tools.
Try it yourself: Data-driven cloud tuning.
 Generative AI observability
Generative AI observability
- Goal
Increase reliability while keeping costs from surging.
With the rise of generative AI in DevOps Portals and IDP tools, tracking usage and consumption is becoming increasingly important, allowing streamlined access and managing cost effectively.
Using observability data further allows the proper sizing and configuration of generative AI tools, increasing experience and productivity for development teams.
Try it yourself:
 Observability for infrastructure
Observability for infrastructure
- Goal
30% reduced MTTR by breaking down data silos.
For IT operations teams, the central challenge in ensuring the health of the IT infrastructure lies in the daunting task of pinpointing the exact root cause of issues.
By applying Golden Paths and as-code templates, users can quickly trace performance issues to their source by "following the red" to the problematic infrastructure entity. This approach allows an immediate understanding of how entities such as hosts, processes, and their associated relationships contribute to the identified issue.
Kubernetes monitoring
- Goal
Manage your platform with 30+ out-of-the-box health alerts.
Establishing scalable cluster lifecycle management within a diverse multi-cluster environment featuring various distributions requires a centralized repository with a single source of truth.
This centralized view:
- Serves as the hub for ingesting, visualizing, and analyzing telemetry data from different layers of the Kubernetes stack
- Enables the execution of configuration actions based on observability insights, such as resource consumption and performance management across all clusters
- Offers extended centralized monitoring and alerting capabilities, particularly for node failure incidents
Predict
Many incidents that used to result in wake-up calls for people on standby can now be addressed before they become major issues by using predictive AI and forecasting.
 Predictive Kubernetes operations
Predictive Kubernetes operations
- Goal
Reduce overprovisioning and storage needs by up to 75%.
Within cloud-native environments, resizing disks can happen frequently. Predictive AI for forecasting enables automatic and timely resizing of disks, avoiding system outages while keeping costs low.
Try it yourself: Predictive Kubernetes operations.
 Forecasting in data analytics
Forecasting in data analytics
- Goal
Zero disk-resize related after-hour alerts for SREs.
Anticipatory management of cloud resources within highly dynamic IT systems is a critical success factor for modern companies. Operators must closely observe business-critical resources such as storage, CPU, and memory to avoid resource-driven outages.
 Forecasting in workflow automation
Forecasting in workflow automation
- Goal
Reduce up to 100% of recurring manual efforts with prediction-driven automation.
Predictive AI in workflow automation makes it possible to proactively raise tickets and act automatically before problems arise.
Try it yourself: Forecast disk and resource utilization.
Prevent
Even when AI can’t predict issues, it can often prevent them using observability and security data.
 Preventing customer-facing bugs
Preventing customer-facing bugs
- Goal
Reduce end-user-facing bugs by up to 36%.
Ingesting and automatically analyzing application log data from production makes it easy to issue tickets with context and create and assign work to the respective development teams, allowing them to act and resolve bugs before end-users encounter them.
Try it yourself: Automated bug triaging and ticketing.
 Unified exposure protection
Unified exposure protection
- Goal
Cut risk remediation from 96 hours to 4 hours – 95% faster.
Observability and security are converging to facilitate prioritization and risk assessment of security findings, resolving the most common frustration with existing tools, specifically during the software development stages. Combining this with automation leads to effective engagements with the teams who need to act on those security findings.
 Continuous security posture awareness
Continuous security posture awareness
- Goal
Instant live security reports.
Get a unified and prioritized view of different exposures across your different application tiers and your production and pre-production environments.
- Prioritize vulnerabilities with a custom risk specific to your organization
- Learn what remediation activities prioritize for impact—and let automation handle it
- Learn the details of a vulnerability, such as which entities are impacted and whether there’s any link to databases.
Resolve
Once an incident occurs, it's important to take the right steps immediately. Sometimes, the first step is to inform the right team with the required information. At other times, issues can be remediated and resolved automatically.
 Incident triaging and response
Incident triaging and response
- Goal
Improve MTTR by up to 99%.
Using observability and security data combined with context and further metadata (such as ownership information), it becomes easy to automatically triage issues as they arise and follow through with the proper response.
The proper response could be any automated action available, such as informing stakeholders through communication tools, opening incident tickets, triggering configuration management tools, or remediating directly by executing Kubernetes jobs or creating pull requests.
 Resolving critical business impact
Resolving critical business impact
- Goal
Linking IT alerts to business impact provides prioritization.
Combining IDP observability data with the impact an IDP has on business transactions and footprints allows organizations to prioritize based on the highest-impact issues first.
 Error budget alerting
Error budget alerting
- Goal
Increase triaging efficiency by 90%.
If you have 99 problems, how do you prioritize?
An easy way to focus on the right problems is to look at those actively impacting Service-Level Objectives (SLOs). If the number of issues in an environment still calls for further prioritization, automatically triage and inform stakeholders easily by alerting them on the SLO error budget burn rate (how fast the SLO error budget is consumed).
Protect
All environments, infrastructures, and applications must be protected — with the right measures. Organizations can protect their assets more easily with a consistent Internal Developer Platform (IDP), providing governance and security.
 Security Operations Center (SOC) noise reduction
Security Operations Center (SOC) noise reduction
- Goal
Reduce security event storms by 99%
Avoiding fatigue due to the myriad of security events emitted by hyperscaler tools every single day by deduplication and consolidation combined with automatic ticket creation and assignment based on development and security ownership.
Try it yourself: CSPM Notification Automation.
 Automate security findings at scale
Automate security findings at scale
- Goal
Strive towards zero false positives.
Understand the threat posed by your code, third party, and open-source libraries and block malicious requests attempting to exploit code weaknesses in these.
- Precisely detect & block attacks
- While applications keep serving their users
- Integrated with OneAgent & available at the flip of a switch
Contextualized threat detection and incident response
- Goal
From threat hypothesis to tangible evidence in minutes.
Today, security takes everyone in your organization, and all your data is relevant for security. That's why it needs to be easy to ingest any data and have it available for manual detailed security analytics. At the pace of cybersecurity attacks today, there is no way around automation. By the time your valuable security analysts get in front of an incident or investigate a malicious pattern - you want to ensure it's worth their time. With data contextualization, workflow actions, and dedicated security analytics apps, you have all the tools to be proactive about security. Finding whether you have a bad actor in your system, what they are up to, and preventing them from being successful – with the merge of observability and security, it's easy to understand how to elevate your analysts by leveling up the security incident first, fully contextualizing the incident, and prioritizing based on importance.
- Stop attackers in their tracks
- Leverage observability and security data in context to see every detail of your environment
- All the data is consolidated at your fingertips
- Automation actions easily combined into a workflow elevate your analysts whenever they need to look at an incident
Improve
Continuous improvement of resources drives business. These improvements can range from cost- to time-savings to always ensuring best-in-class customer experiences.
 Always-on app profiling
Always-on app profiling
- Goal
5x faster performance bottleneck issue resolution
With observability data around CPU, thread, and memory usage, it's easy to quickly identify the biggest performance bottlenecks and flag them for improvement. Such bottlenecks could manifest themselves as inefficient string operations leading to high memory allocation and pressure on the garbage collector, which can, in turn, lead to scalability and performance issues.
Try it yourself: Always-on app profiling.
 Kubernetes utilization improvement
Kubernetes utilization improvement
- Goal
Automated K8s utilization improvement reduces spend up to 25%.
Continuously update and improve k8s requests and limits automatically, reducing cognitive load on developers and providing peace of mind for platform engineers.
By analyzing Kubernetes metrics and SLOs for resource allocation and utilization, it's possible to set environment configuration avoiding any misalignment.
 Business alignment
Business alignment
- Goal
Bring in context to your business processes and accelerate collaboration.
It's critical to align platform engineering initiatives and work with the primary value stream. Aligning initiatives to assets allows for easier prioritization of improvement work and communication with the line of business.
Measuring platform success
Governance and consistency at scale
Golden Paths guide developers, saving time and reducing risks. But they're not one-size-fits-all — flexibility exists for individual customization and exploration.
The result? A platform that scales effortlessly, where standardized efficiency works with developer autonomy to offer governance and consistency.
Applying product management principles and observability to the IDP makes it possible to provide meaningful insights into platform infrastructure, tools, and services. Golden Paths adoption and efficiency regarding feedback for developers.
DORA metrics
Google’s DevOps Research and Assessment (DORA) team established the DORA metrics to provide key metrics on the performance of a software development team.
The established four keys include:
- Deployment frequency
Measures how often a team successfully releases to production
- Lead time for change
Measures the time it takes for committed code to get into production.
- Change failure rate
Measures the percentage of deployments that result in a failure in production that requires a bug fix or roll-back.
- Mean time to restore service (MTTR)
Measures how long it takes an organization to recover from a failure in production.
The DORA team extended these metrics by adding a fifth one in 2021:
- Reliability
Representing availability, latency, performance, and scalability
Benchmarking in real-time and across dimensions (such as technologies and teams) provides crucial benefits or a platform engineering team.
Developer experience
Platform engineering is ultimately about driving developer productivity. But how do you define and measure developer productivity and satisfaction? It can’t be reduced to a single metric, but the SPACE framework captures critical dimensions of developer productivity:
- Satisfaction
- Performance
- Activity
- Communication and collaboration
- Efficiency and flow
The SPACE framework doesn't provide a ready-to-use list of metrics like the DORA metrics, but instead guides in providing categories to consider.
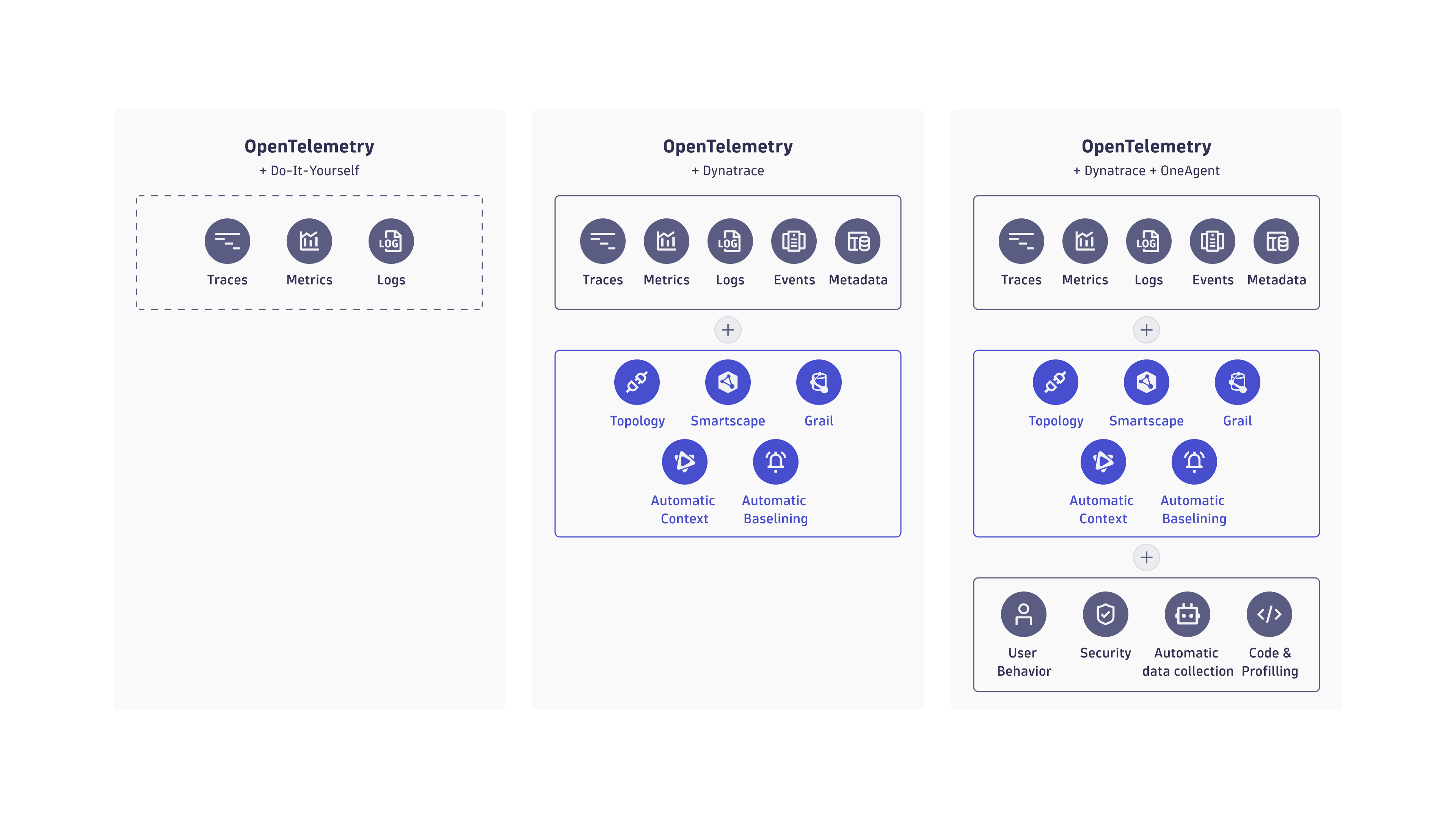
Dynatrace and OpenTelemetry
OpenTelemetry (also referred to as OTel) is an open-source observability framework made up of a collection of tools, APIs, and SDKs.
-
OTel enables IT teams to instrument, generate, collect, and export telemetry data for analysis and understanding software performance and behavior.
As a Cloud Native Computing Foundation (CNCF) incubating project, OTel aims to provide unified sets of vendor-agnostic libraries and APIs, mainly for collecting data and transferring it somewhere.
-
Dynatrace, which is committed to making observability seamless for technical teams, is the only observability solution that combines high-fidelity distributed tracing, code-level visibility, and advanced diagnostics across cloud-native architectures. Data plus context are critical to supercharging observability.
By integrating OTel data seamlessly, Dynatrace’s distributed tracing technology automatically picks up OTel data and provides the instrumentation for all the essential frameworks beyond the scope of OTel.
Take action!
Implementing DevOps and platform engineering is not optional for organizations serious about transforming their ability to deliver value in the cloud. These practices are crucial, not just beneficial, for boosting productivity and achieving success in today's tech landscape.
Dynatrace’s purpose-built solution for platform engineering reduces complexity through automated workflows, including auto-scaling, deployment validation, and anomaly remediation.
By leveraging the power of the Dynatrace platform and the new Kubernetes experience, platform engineers are empowered to implement the following best practices, enabling their development teams to deliver best-in-class applications and services to their customers.
- Centralize and standardize
The ability to effectively manage multi-cluster infrastructure is critical to consistent and scalable service delivery.
- Provide self-service platform services with dedicated UI
for development teams to improve developer experience and increase speed of delivery.
- Automation, automation, automation
Adoption of GitOps practices enables platform provisioning at scale.
- Context
Get access to not just data, but answers — reaching the right stakeholders at the right time.
Gartner, Top Strategic Technology Trends for 2024, Bart Willemsen, Gary Olliffe, and Arun Chandrasekaran, 16 October 2023. GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.