Calculated service metrics upgrade guide
- Latest Dynatrace
- Upgrade guide
- 11-min read
This guide explains how to upgrade your existing calculated service metrics to Grail.
Creating new calculated service metrics
When creating new calculated service metrics, you should use OpenPipeline, which uses metric extraction from span data to provide more flexibility and control. To read more about metric extraction, see Extract metrics from spans and distributed traces.
You can continue using the existing classic calculated service metrics functionality if needed, but OpenPipeline will eventually become the default method for creating calculated service metrics. At that point, the current calculated service metrics functionality will be deprecated. Currently, no deprecation date is set.
What's in the scope of the upgrade?
Most existing metrics are upgraded automatically to Grail, where they can be leveraged in the new  Dashboards or
Dashboards or  Notebooks, or analyzed in apps such as the Services app.
Notebooks, or analyzed in apps such as the Services app.
Metrics created using the classic calculated service metrics feature remain accessible via Dashboards Classic and the classic Multidimensional analysis.
Some metrics are not auto-upgraded but can be upgraded manually by using a toggle on the Calculated service metrics page to enable or disable the metric being sent to Grail. For details, see Set metric to enabled or disabled on Grail.
There are also some metrics that are not eligible for upgrade. These can be recreated in OpenPipeline or, if long-term historical analysis is not required, in Notebooks.
To determine if a metric can be upgraded, its cardinality—the number of distinct dimensions created by a metric—is taken into account. It is checked over the last two weeks in 5-minute windows, which means any distinct dimension created within those 5 minutes is counted. The resulting sum is the cardinality of that window. The cardinality that is used is the maximum value of all windows. This happens on a per-service basis if the calculated service metric is written for more than one service.
The following applies if you have enabled Split by dimension for the chosen metric. Any metric without this feature will be automatically upgraded. For details on dimensions for calculated service metrics, refer to Calculated service metrics.
-
Auto-upgraded: If the calculated service metric's cardinality is less than the value defined in the "top X" value and less than 500 within any 5-minute window in the past two weeks, and the metric has existed for longer than two weeks, it is auto-upgraded.
- Only new data is written to calculated metrics; retrospective data is not included.
- You can have up to 500 enabled calculated metrics per environment and up to 100 enabled calculated metrics per service.
- Classic calculated metrics support at most 100 dimension values. This is referred to as the "top X" rule, as you can select fewer depending on your configuration. However you choose the top 100 dimension values, the remaining dimensions are aggregated into a single timeseries and the dimension value is accessible through a special
remainderdimension. The remainder filter condition allowing you to filter on thisremainderdimension.
- Grail calculated service metrics with cardinality higher than 2000 within any 5-minute window in the past 2 weeks or since the last metric change are automatically disabled in Grail. Enabling such metrics on Grail is not allowed. If the metric is already enabled on Grail, you are informed of the metric rejection via the Metric & Dimensions Usage + Rejections ready-made dashboard. To enable a Classic metric on Grail and keep collecting incoming data on Grail, make sure cardinality stays below the limit.
-
Not auto-upgraded:
- If the metric's cardinality exceeds the value defined in the "top X" value, the upgrade has to be triggered manually. This upgrade is not automatic because Grail offers enhanced precision and stores the metric's full dimension cardinality, not just the "top X" values. This is a powerful capability, but without a "top X" limit, it may increase the stored metric data points and license consumption compared to the classic metric.
- If the metric's cardinality is above 500, the upgrade also has to be triggered manually. The upgrade is not automatic because many high-cardinality metrics are used for one-off reporting without the need for a long-term historical analysis. With Notebooks, you can use DQL to recreate those metrics as useful and effective reports.
-
Not eligible for upgrade: Metrics with cardinality exceeding 2,000 can't be upgraded. In such cases, the upgrade button is not active, and an information message is displayed. You can recreate the metric using OpenPipeline to extract metrics from span data or use DQL in
Notebooks for one-off reports without long-term historical analysis. Alternatively, you can edit the definition of your classic calculated service metric to reduce its cardinality to below 2,000, resulting in fewer data points.Find the cardinality of a metricFor metrics that are not automatically upgraded, Dynatrace displays the current cardinality of the classic metric in the warning box of the calculated service metric.
You can also find the cardinality by running the following expression in the
 Data Explorer app.dsfm:server.metrics.calculated_metrics.number_of_values:filter(eq(metric_key, "calc:service.<your_metric_key>")):splitBy(metric_key):max
Data Explorer app.dsfm:server.metrics.calculated_metrics.number_of_values:filter(eq(metric_key, "calc:service.<your_metric_key>")):splitBy(metric_key):maxReplace <your_metric_key> with the key of your calculated service metric to retrieve its cardinality.
How to upgrade manually?
On the Calculated service metrics page, you can see which metrics are already written to Grail and which are not.
Set which calculated service metrics will be enabled on Grail
To enable or disable classic calculated service metrics on Grail
- Go to Settings Classic > Server-side service monitoring > Calculated service metrics.
- Choose the calculated service metric you want to configure.
- Optional Select to open the metric's details and edit its settings, and then select Save metric.
- Toggle the option to enable or disable the metric being sent to Grail.
- Select Save changes.
What happens after the upgrade?
All calculated service metrics that are enabled on Grail get a corresponding Grail metric key service.xxx. The metric key of the classic metric remains unchanged. The upgraded metrics get new dimensions that make them more powerful and easier to use in Dashboards. For details, refer to Calculated service metrics.
Explore a calculated service metric in Notebooks/DQL
To open a calculated service metric in Notebooks
- Go to Settings Classic > Server-side service monitoring > Calculated service metrics.
- Choose the calculated service metric from the list and select Open with.
- Select Notebooks.
- In Select destination, choose a notebook and then select Confirm.
The Notebooks app opens with the calculated service metric data displayed. You can choose how to visualize the data from the options. For details, refer to Notebooks.
Some calculated service metrics may need manual adjustments to display correctly. For details, refer to section Differences between Grail and Classic metrics.
Differences between Grail and Classic metrics
For the metrics below, the recommended approach is to go to the metric's details, select Open with, and choose to open the metric in Notebooks. This way, the necessary adjustments are automatically applied and a DQL query is provided that can be used as a basis for other queries or dashboards.
-
Failure rate metrics: In Grail, these metrics count the number of failed and successful requests by using an additional Boolean dimension "failed" (
trueorfalse). The failure rate needs to be calculated using DQL.For example, here is a DQL query for the
AEM content failure ratemetric. It calculates the percentage of failed requests by dividing the number of failed requests per minute by the total number of requests per minute.timeseries {failedNum = sum(service.aemcontentfailurerate, default: 0.0, filter: failed == true),totalNum = sum(service.aemcontentfailurerate)},by: { dt.entity.service }, union:true| fieldsAdd failure_rate = (failedNum[] / totalNum[]) * 100| fieldsRemove totalNum, failedNum -
Request count metrics: Classic metrics used a datatype that combined a counter with a rolling average functionality. This data type does not exist in Grail. To chart a rolling average in Grail correctly requires an additional DQL parameter.
timeseries {avg(service.wkndrequestcount, rollup: sum)}
Handling calculated service metrics than can't be upgraded
Here are several examples of cases when you should consider using DQL reports instead of upgrading a calculated service metric to Grail.
1. Example 1: Top 30 web requests
The DQL query returns the top 30 web requests on endpoints where the services returned a 5xx response code. The timeseries should also be split by the server address to distinguish between the different servers.
Upgrading the metric to Grail is not recommended because the combination of endpoint.name and server.address has a high cardinality.
fetch spans| filter http.response.status_code >= 500 and http.response.status_code <= 599 and request.is_root_span == true| fieldsAdd entityName(dt.entity.service) // adds dt.entity.service.name// calculate multiplicity factor for every span based on sampling and aggregation| fieldsAdd sampling.probability = (power(2, 56) - coalesce(sampling.threshold, 0)) * power(2, -56)| fieldsAdd sampling.multiplicity = 1/sampling.probability| fieldsAdd multiplicity = coalesce(sampling.multiplicity, 1)* coalesce(aggregation.count, 1)* dt.system.sampling_ratio| makeTimeseries { count = count()}, by: { dt.entity.service.name, dt.entity.service, endpoint.name, server.address}// only show top 30 timeseries| sort arraySum(`count`) desc | limit 30
Sample output
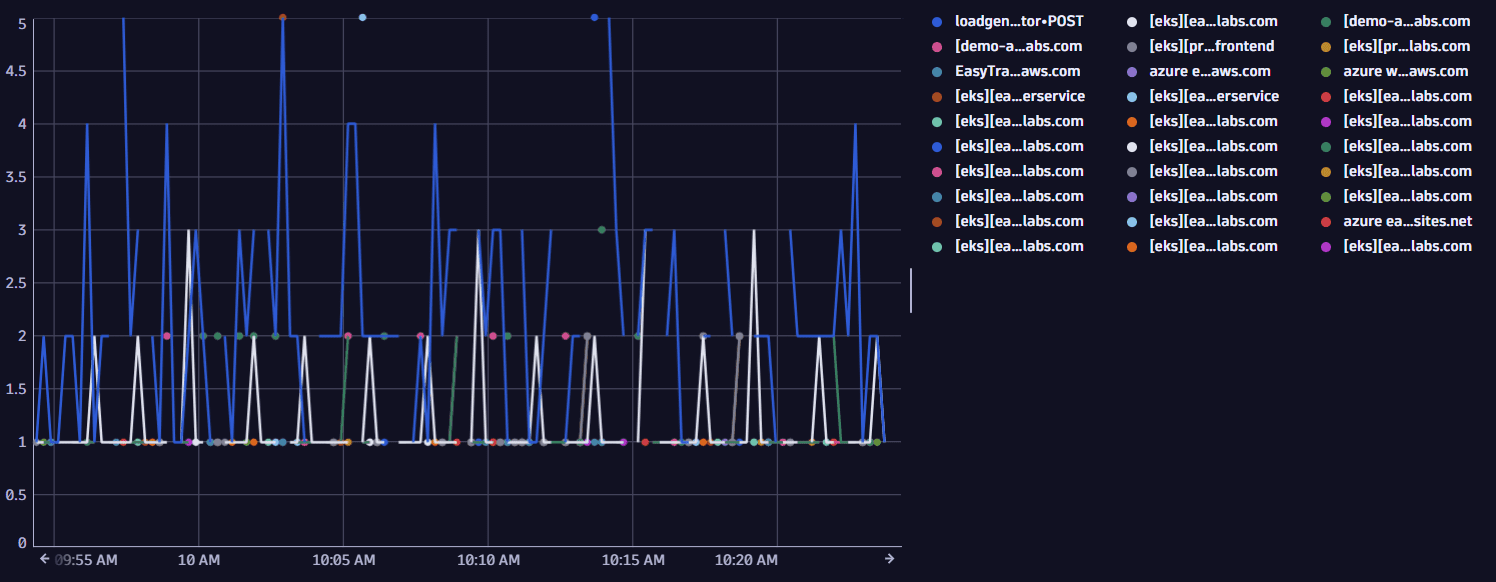
2. Example 2: Top database statements per service
The DQL query returns the top 30 database statements executed in the environment over time.
Upgrading the metric to Grail is not recommended because db.query.text has a very high cardinality.
fetch spans// filter for database spans| filter span.kind == "client" and isNotNull(db.namespace)| fieldsAdd entityName(dt.entity.service) // adds dt.entity.service.name// calculate multiplicity factor for every span based on sampling and aggregation| fieldsAdd sampling.probability = (power(2, 56) - coalesce(sampling.threshold, 0)) * power(2, -56)| fieldsAdd sampling.multiplicity = 1/sampling.probability| fieldsAdd multiplicity = coalesce(sampling.multiplicity, 1)* coalesce(aggregation.count, 1)* dt.system.sampling_ratio| makeTimeseries { db_calls = sum(multiplicity) }, by: { dt.entity.service.name, code.function, db.system, db.namespace, db.query.text }// only show top 30 timeseries| sort arraySum(`db_calls`) desc | limit 30
This DQL query also takes into account span sampling, aggregation, and extrapolation to get the real number of calls.
Sample output
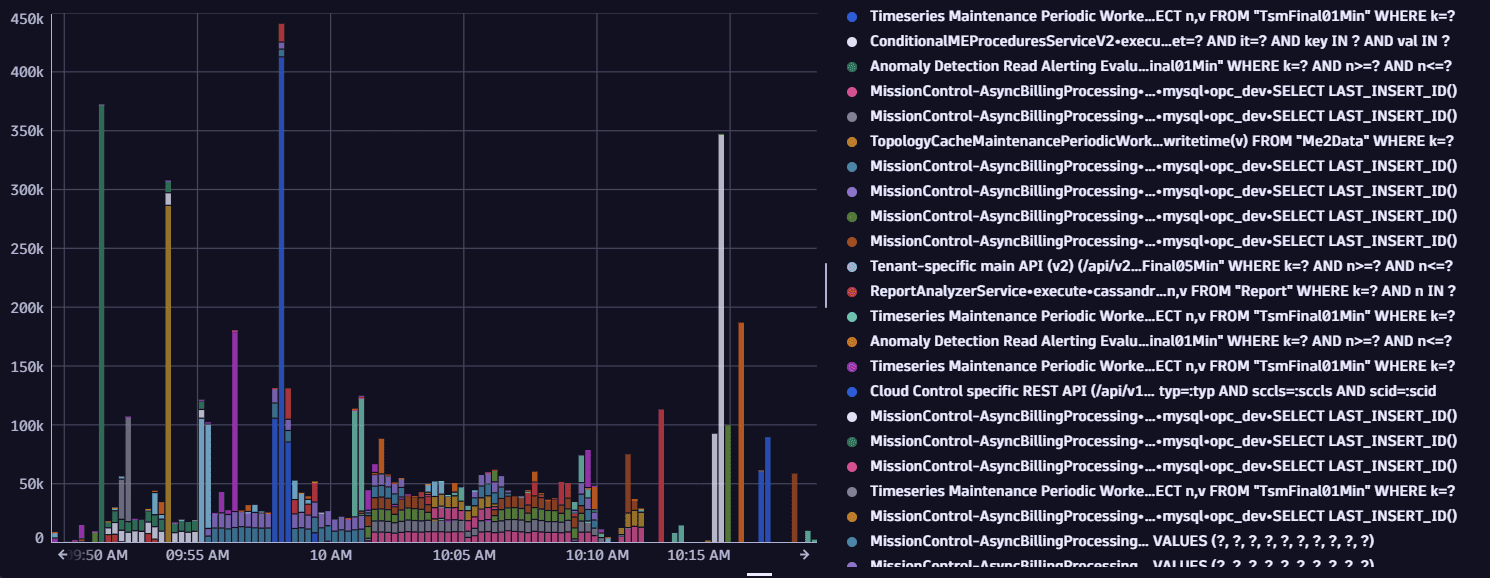
3. Example 3: Exception count by type (Exception frequency)
The DQL query returns the top 10 exception classes that happen in the environment over time.
Upgrading the metric to Grail is not recommended because of the high cardinality due to the exception type splitting.
fetch spans// only spans which contain a span event of type "exception"| filter iAny(span.events[][span_event.name] == "exception")// make exception type top level attribute| expand span.events | fieldsFlatten span.events, fields: { exception.type }| makeTimeseries cnt=count(), by: { exception.type }// only show top 10 timeseries| sort arraySum(cnt) desc | limit 10
This DQL query doesn't take into account sampling, aggregation, and extrapolation. For more details, refer to the database example or Advanced Tracing Analytics powered by Grail.
Sample output
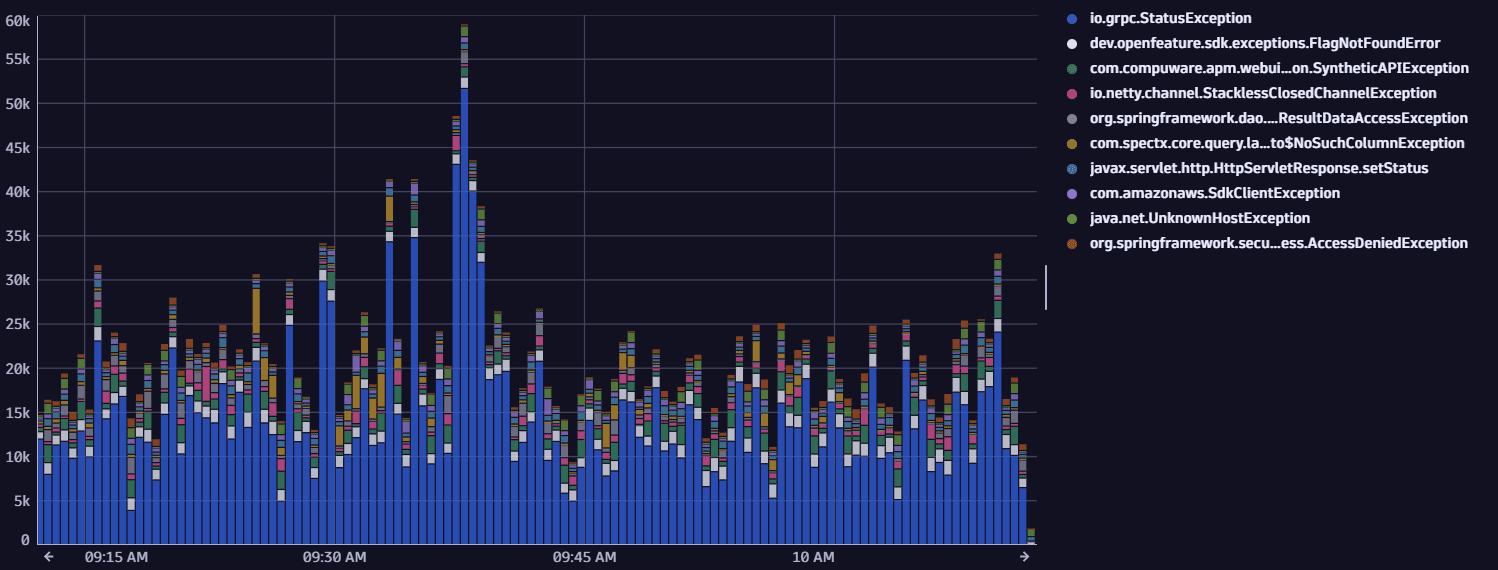
4. Example 4: Requests of a specific service split by service instance
The DQL query returns the top 10 requests on service instances over time. A service instance is the combination of the service and the host or Kubernetes pod, respectively.
Upgrading the metric to Grail is not recommended because of the high cardinality due to the service instance splitting.
fetch spans// filter specific service| filter dt.entity.service == "SERVICE-20E42C3D8D3E0C62"// filter only for request root spans| filter request.is_root_span == true| makeTimeseries { requests=count(), avg(duration) }, by: { url.path, dt.entity.host, k8s.pod.name }// only show top 10 timeseries| sort arraySum(requests) desc | limit 10
This DQL query doesn't take into account sampling, aggregation, and extrapolation. For more details, refer to the database example or Advanced Tracing Analytics powered by Grail.
Sample output
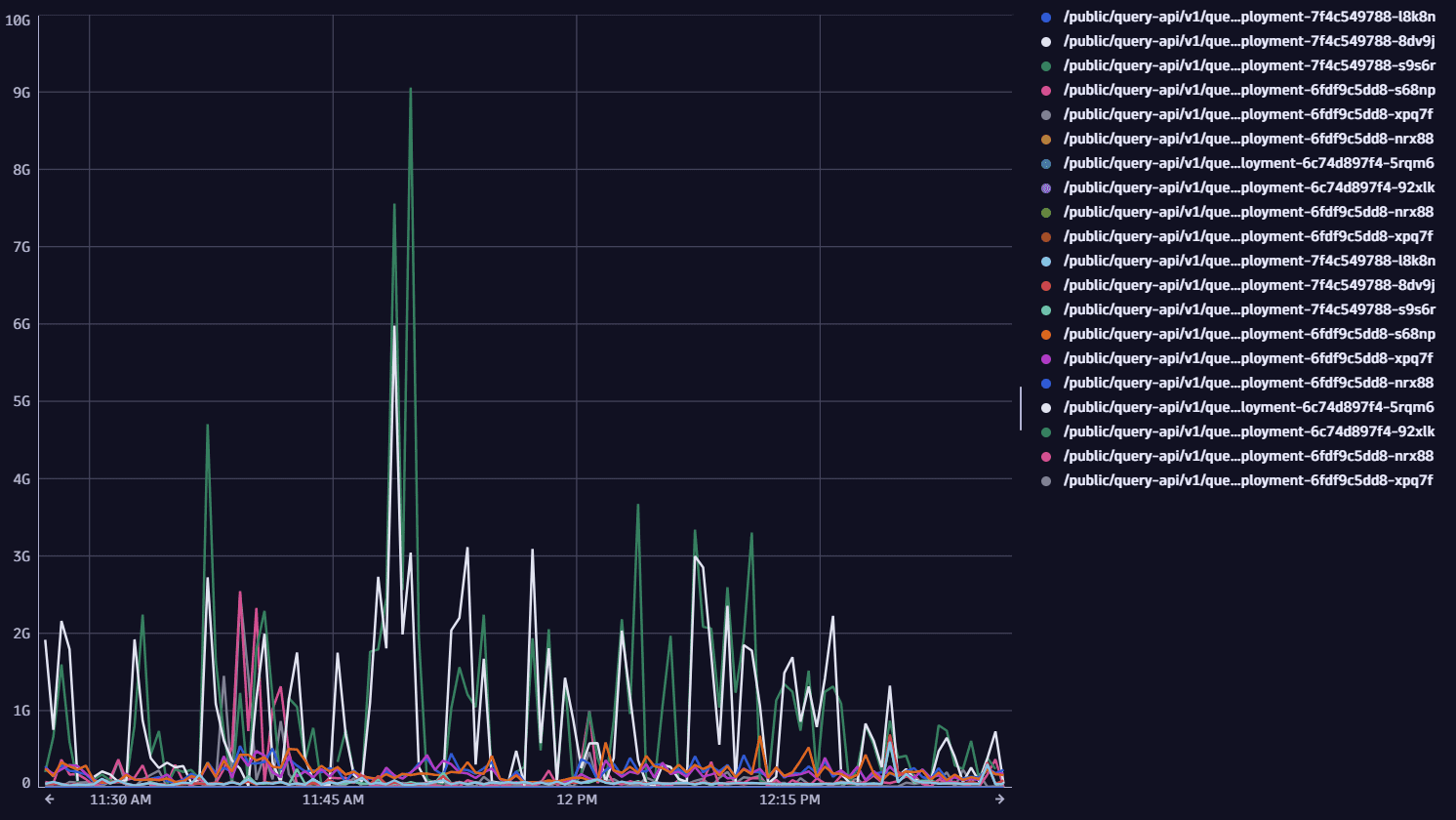
5. Example 5: Drilldown on top 10 URLs with fine-granular conditions
The DQL query returns the top 10 URLs with most failed attempts on wallet-services if a payment is involved. Payments are indicated by the request attribute PaidAmount.
Upgrading the metric to Grail is not recommended because of the high cardinality due to URL splitting.
fetch spans// filter for "failed requests"| filter isNotNull(endpoint.name) and request.is_failed == true// conditions on service display name and request attribute| filter contains(entityName(dt.entity.service), "wallet-service")| filter exists(request_attribute.PaidAmount)// count requests and split by service and url| makeTimeseries failed_request_count=count(), by: { dt.entity.service, url.full }// only show top 10 timeseries| sort arraySum(failed_request_count) desc | limit 10
This DQL query doesn't take into account sampling, aggregation, and extrapolation. For more details, refer to the database example or Advanced Tracing Analytics powered by Grail.
Sample output
Licensing considerations
- Calculated service metrics continue to consume your license like custom metrics—there are no changes with the upgrade.
- You are not billed twice. When a calculated service metric is upgraded to Grail, you're only billed for the classic or the Grail metric, not both, even if the metric is available in both versions.