Ingest Amazon GuardDuty security findings
- Latest Dynatrace
- How-to guide
Prioritize GuardDuty findings with runtime context in Dynatrace.
Get started
Overview
Dynatrace integration with Amazon GuardDuty allows you to unify and contextualize security findings across tools and products, enabling central prioritization, visualization, and automation.
GuardDuty detects suspicious activities in your AWS accounts, workloads, and data. The Dynatrace platform observes the runtime entities related to those AWS resources. Ingesting the detection findings from GuardDuty helps you analyze them in the context of their production apps.
Use cases
With the ingested data, you can accomplish various use cases, such as
Requirements
See below for the Amazon GuardDuty and Dynatrace requirements.
Amazon GuardDuty requirements
-
Install and configure the latest AWS CLI.
-
Select the AWS region where you want to create the event forwarder.
Show me how
-
In a terminal, run:
aws configure -
Set your default region (for example,
us-east-1).
-
Dynatrace requirements
-
Permissions:
- To query ingested data:
storage:security.events:read.
- To query ingested data:
-
Tokens:
- Generate an access token with the
openpipeline.events_securityscope and save it for later. For details, see Dynatrace API - Tokens and authentication.
- Generate an access token with the
Activation and setup
- In Dynatrace, open Hub.
- Look for Amazon GuardDuty and select Install.
- Select Set up, then select Configure new connection.
- Follow the on-screen instructions to set up the ingestion.
Details
How it works
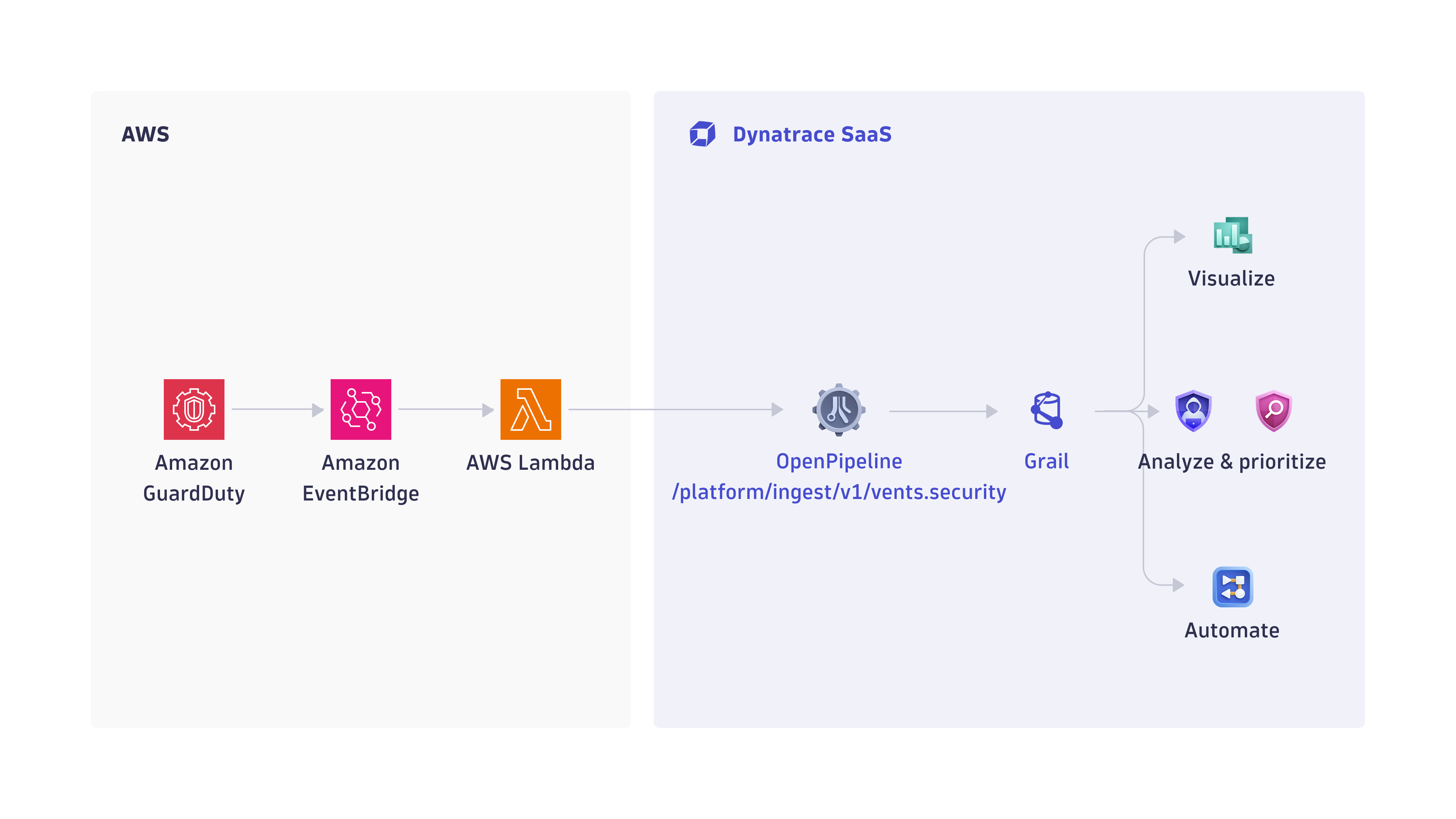
1. Events are ingested into Dynatrace
-
Amazon GuardDuty events are sent to Amazon EventBridge, which triggers an AWS Lambda function.
-
The Lambda function pre-processes the events and sends them to Dynatrace via a dedicated OpenPipeline security ingest endpoint.
2. Security findings are processed and stored in Grail
-
The OpenPipeline ingest endpoint processes and maps the data according to the Semantic Dictionary conventions.
-
Data is stored in a bucket called
default_securityevents(for details, see: Built-in Grail buckets).
Monitor data
Once you ingest your Amazon GuardDuty data into Grail, you can monitor your data in the app (in Dynatrace, go to Settings, then search for and select Amazon GuardDuty).
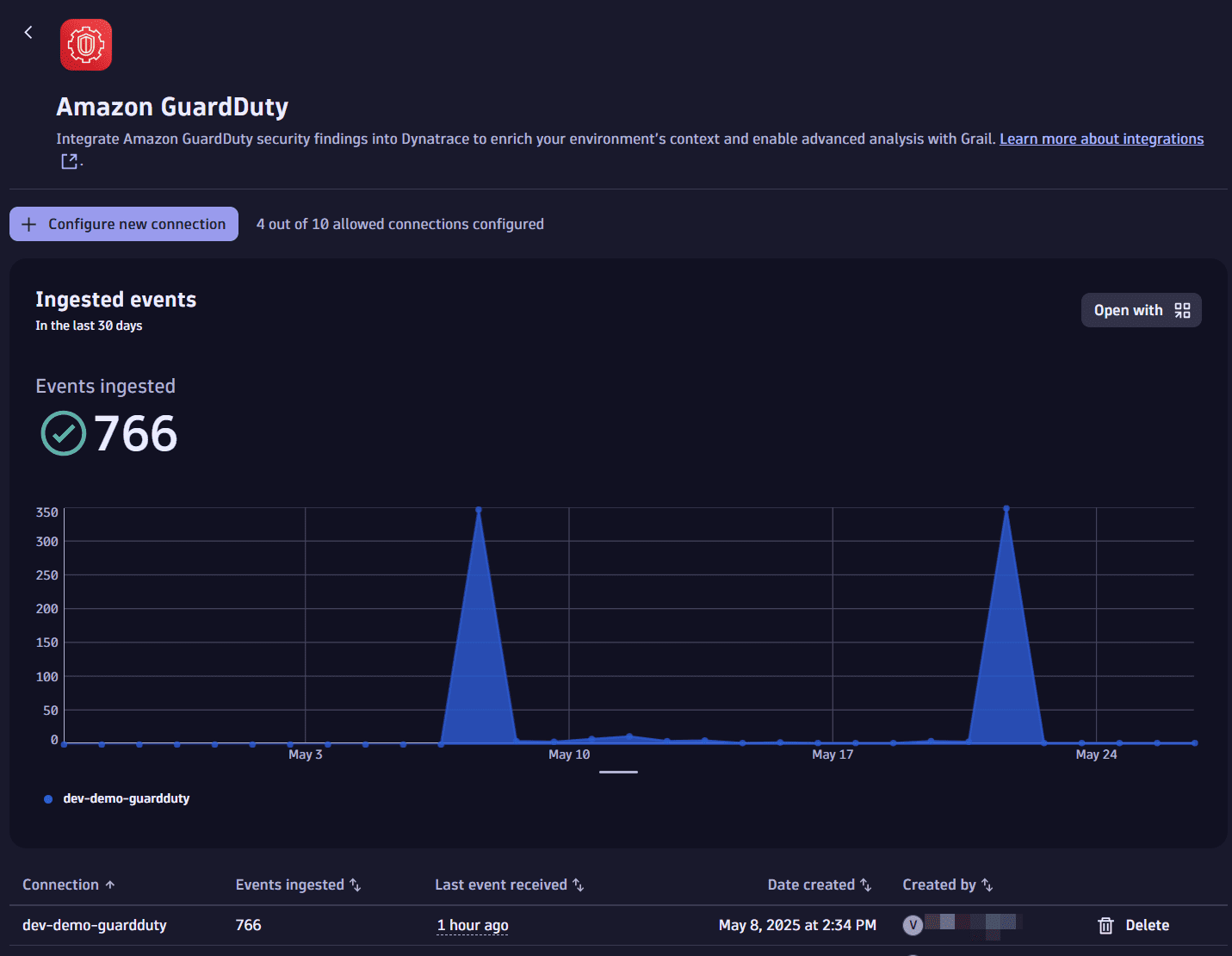
You can view
-
A chart of ingested data from all existing connections over time
- Available actions: Query ingested data
-
A table with information about your connections
- Available actions: Delete connection
Visualize and analyze findings
You can create your own dashboards or use our templates to visualize and analyze container vulnerability findings.
- In Settings, open Amazon GuardDuty.
- In the Try our templates section, select the desired dashboard template.
Automate and orchestrate findings
You can create your own workflows or use our templates to automate and orchestrate container vulnerability findings.
- In Settings, open Amazon GuardDuty.
- In the Try our templates section, select the desired workflow template.
Query ingested data
You can query ingested data in  Notebooks or
Notebooks or  Investigations, using the data format in Semantic Dictionary.
Investigations, using the data format in Semantic Dictionary.
- In Settings, open Amazon GuardDuty.
- Select Open with .
- Select Investigations or Notebooks.
Evaluate, triage, and investigate detection findings
You can evaluate, triage, and investigate detection findings with  Threats & Exploits.
Threats & Exploits.
- Open Threats & Exploits.
- Filter for Provider > Amazon GuardDuty.
Delete connections
To stop sending events to Dynatrace
- In Settings, open Amazon GuardDuty.
- For the connection you want to delete, select Delete.
- Follow the on-screen instructions to delete the resources. If you used values different from those specified in the setup dialog, adjust them accordingly.
This removes the Dynatrace resources created for this integration.
Licensing and costs
For billing information, see Events powered by Grail.
FAQ
Which data model is used for the security logs and events coming from Amazon GuardDuty?
Detection finding events store the individual detection findings per affected object represented by an AWS resource.
Which extension fields are added on the events ingested from Amazon GuardDuty?
The aws namespace is added to store AWS-related information with the following fields:
-
aws.account.id -
aws.region -
aws.availability_zone -
aws.resource.type -
aws.resource.name
What Amazon GuardDuty resource types are supported by Dynatrace for runtime contextualization?
CONTAINER: All the detection findings with a container as the target resource are classified as CONTAINER in object.type, and the container namespace is added with the corresponding fields:
-
container.id -
container.name -
container.image.name -
container.image.version
How do we normalize the risk score for Amazon GuardDuty findings?
Dynatrace normalizes severity and risk scores for all findings ingested through the current integration. This helps you to prioritize findings consistently, regardless of their source.
For details on how normalization works, see Severity and score normalization.
-
dt.security.risk.levelis mapped from the severity level determined by Amazon GuardDuty mapping of the severity score (detail.severity). -
dt.security.risk.scoreis mapped directly from the severity score (detail.severity) set by Amazon GuardDuty.
dt.security.risk.level (mapped from finding.severity) | dt.security.risk.score (mapped from finding.score) |
|---|---|
CRITICAL -> CRITICAL | 9.0-10.0 |
HIGH -> HIGH | 7.00-8.9 |
MEDIUM -> MEDIUM | 4.0-6.9 |
LOW -> LOW | 1.0-3.9 |
