Metrics API - Metric selector
- Reference
The metric selector is a powerful instrument for specifying which metrics you want to read via the GET metric data points request or in the Advanced mode of Data Explorer.
In addition, you can transform the resulting set of data points. These transformations modify the plain metric data.
Even if you are building a selector to use in an API call, we recommend that you create your query using the Code tab of Data Explorer, which offers built-in tools (for example, auto-completion) to help you construct the query.
Limitations
- The selector must contain at least one metric key.
- You can query data points of up to 10 metrics in one query.
Metric dimensions
Many Dynatrace metrics can be referenced with finer granularity using dimensions. For example, the builtin:host.disk.avail metric has two dimensions:
- The primary dimension is Host
- The secondary dimension is Disk
Query a metric with the GET metric descriptor call to obtain information about available dimensions—you can find them in the dimensionDefinitions field of the metric descriptor.
Show descriptor example
{"dimensionDefinitions": [{"key": "dt.entity.host","name": "Host","displayName": "Host","index": 0,"type": "ENTITY"},{"key": "dt.entity.disk","name": "Disk","displayName": "Disk","index": 1,"type": "ENTITY"}]}
Wherever you see the <dimension> placeholder in the example syntax, you can select a specific dimension of the metric. You can reference a dimension by its key. For example, for builtin:host.disk.avail these are dt.entity.host and dt.entity.disk.
Transform operations modify the list of dimensions by adding or removing them. Subsequent transformations operate on the modified list of dimensions. Query the metric descriptor with preceding transformations (for example, builtin:host.disk.avail:names) to view the new list of available dimensions.
Remainder dimension
Dynatrace keeps only the top X dimension tuples (the exact number depends on the metric, aggregation, timeframe, and other factors). All other dimension tuples are aggregated into one, called the remainder dimension.
If the query result includes this dimension, the dimensions and dimensionMap value will be null. However, if the dimensionMap does not contain an entry at all, then this is not the remainder dimension, but rather a literal null value.
Time aggregation
The amount of raw data available in Dynatrace makes it challenging to present the data in a meaningful way. To improve the readability, Dynatrace applies a time aggregation, aligning the data to time slots. You can define the aggregation method via the aggregation transformation.
Even if you don't specify any aggregation transformation, some aggregation applies nevertheless, using the default transformation of the metric. Applying the auto transformation has the same effect.
Available aggregations vary for each metric. You can check the available aggregations (and the default aggregation) via the GET metric descriptor call—look for the aggregationTypes and defaultAggregation fields.
The resolution of the resulting time series depends on factors such as the query timeframe and the age of the data. You can, to an extent, control the resolution via the resolution query parameter of the GET metric data points request. The finest available resolution is one minute. Additionally, you can aggregate all data points of a time series into a single data point—use the fold transformation for that.
Example
To illustrate the time aggregations, let's consider an example of the CPU usage (builtin:host.cpu.usage) metric.
Show metric descriptor
{"metricId": "builtin:host.cpu.usage","displayName": "CPU usage %","description": "Percentage of CPU time currently utilized.","unit": "Percent","dduBillable": false,"created": 0,"lastWritten": 1668607995463,"entityType": ["HOST"],"aggregationTypes": ["auto","avg","max","min"],"transformations": ["filter","fold","limit","merge","names","parents","timeshift","sort","last","splitBy","lastReal","setUnit"],"defaultAggregation": {"type": "avg"},"dimensionDefinitions": [{"key": "dt.entity.host","name": "Host","displayName": "Host","index": 0,"type": "ENTITY"}],"tags": [],"metricValueType": {"type": "unknown"},"scalar": false,"resolutionInfSupported": true}
Because its default transformation is avg, if you query data points without applying any aggregation, you will obtain the average CPU usage for each time slot of the resulting time series.
To obtain the maximum CPU usage per time slot, use the selector below.
builtin:host.cpu.usage:max
If you want the single highest usage of a timeframe, you can apply the fold transformation.
builtin:host.cpu.usage:fold(max)
Space aggregation
Each metric might carry numerous time series for various dimensions. Space aggregation eases the access to dimensions you're interested in by merging everything else together.
Example
Let's consider an example of the Session count - estimated (builtin:apps.other.sessionCount.osAndGeo) metric.
Show metric descriptor
{"metricId": "builtin:apps.other.sessionCount.osAndGeo:names","displayName": "Session count - estimated (by OS, geolocation) [mobile, custom]","description": "","unit": "Count","dduBillable": false,"created": 0,"lastWritten": 1668609851154,"entityType": ["CUSTOM_APPLICATION","MOBILE_APPLICATION"],"aggregationTypes": ["auto","value"],"transformations": ["filter","fold","limit","merge","names","parents","timeshift","sort","last","splitBy","lastReal","setUnit"],"defaultAggregation": {"type": "value"},"dimensionDefinitions": [{"key": "dt.entity.device_application.name","name": "dt.entity.device_application.name","displayName": "dt.entity.device_application.name","index": 0,"type": "STRING"},{"key": "dt.entity.device_application","name": "Application","displayName": "Mobile or custom application","index": 1,"type": "ENTITY"},{"key": "dt.entity.os.name","name": "dt.entity.os.name","displayName": "dt.entity.os.name","index": 2,"type": "STRING"},{"key": "dt.entity.os","name": "Operating system","displayName": "OS","index": 3,"type": "ENTITY"},{"key": "dt.entity.geolocation.name","name": "dt.entity.geolocation.name","displayName": "dt.entity.geolocation.name","index": 4,"type": "STRING"},{"key": "dt.entity.geolocation","name": "Geolocation","displayName": "Geolocation","index": 5,"type": "ENTITY"}],"tags": [],"metricValueType": {"type": "unknown"},"scalar": false,"resolutionInfSupported": true,"warnings": ["The field dimensionCardinalities is only supported for untransformed single metric keys and was ignored."]}
The metric splits the time series based on application, operating system, and geographic location. If you want to investigate data for a particular application regardless of OS and location, you can apply the splitBy transformation as shown below.
builtin:apps.other.sessionCount.osAndGeo:splitBy("dt.entity.device_application")
You can even merge all dimensions into one by omitting the argument of the transformation. Let's look at the CPU usage (builtin:host.cpu.usage) metric again. In the example below, the transformation merges measurements of all your hosts into a single time series.
builtin:host.cpu.usage:splitBy()
Data filtering
Another way to narrow down the data output is by applying the filter transformation. For example, you can filter time series based on a certain threshold—for details, see the description of the series condition.
In combination with space aggregation, you can build powerful selectors like the one below, which reads the maximum pod count for the preproduction Kubernetes cluster split by a cloud application.
builtin:kubernetes.pods:filter(eq("k8s.cluster.name","preproduction")):splitBy("dt.entity.cloud_application"):max
You can also filter data based on monitored entities by using the power of the entity selector. The selector below reads the CPU usage for all hosts that have the easyTravel tag.
builtin:host.cpu.usage:filter(in("dt.entity.host",entitySelector("type(~"HOST~"),tag(~"easyTravel~")")))
How to use the metric selector
Select metrics
You need to specify a metric key to get the timeseries for it. You can also specify multiple metric keys separated by commas (for example, metrickey1,metrickey2).
When using the data explorer, metric key sections beginning with special characters need to be escaped with quotes (""). For example,
| Ingested Metric | Sample Metric Selector |
|---|---|
| custom.http5xx | custom.http5xx:splitBy():auto |
| custom.5xx_errors | custom."5xx_errors":splitBy():auto |
Apply transformations
After selecting a metric, you can apply transformations to its data. You can combine any number of transformations. The metric selector string is evaluated from left to right. Each successive transformation is applied to the result of the previous transformation. Let's consider an example:
builtin:host.cpu.user:sort(value(max,descending)):limit(10)
This selector queries the data for the builtin:host.cpu.usage metric, sorts the results by the maximum CPU usage, and returns the series for the top 10 hosts.
Dynatrace provides you with a rich set of transformations to manipulate the series data points according to your needs. Below you can find a listing of all available transformations the metric selector offers.
Aggregation transformation
| Syntax | :<aggregation> |
| Argument | The desired aggregation. |
Specifies the aggregation of the returned data points. The following aggregation types are available:
| Syntax | Description |
|---|---|
| Applies the default aggregation. To check the default aggregation, query a metric with the GET metric descriptors call and check the defaultAggregation field. |
| Calculates the arithmetic mean of all values from the time slot. All |
| Takes the count of the values in the time slot. All |
| Exposes the buckets of a histogram metric as dimensions. The value of the |
| Selects the highest value from the time slot. All |
| Selects the lowest value from the time slot. All |
| Calculates the Nth percentile, where N is between |
| Sums all values from the time slot. All |
| Takes a single value as is. Only applicable to previously aggregated values and metrics that support the |
Default transformation
Syntax |
|
Arguments |
|
The default transformation replaces null values in the payload with the specified value.
When always is not specified, a pre-transformed time series must have at least one data point for the transformation to work; if the time series doesn't have any data points, it remains empty after transformation.
Show examples
{"totalCount": 1,"nextPageKey": null,"result": [{"metricId": "builtin:tech.jvm.memory.pool.collectionCount","data": [{"dimensions": ["PROCESS_GROUP_INSTANCE-A02ED607B5E9DD20","30382","G1 Old Gen","G1 Old Generation"],"dimensionMap": {"poolname": "G1 Old Gen","rx_pid": "30382","gcname": "G1 Old Generation","dt.entity.process_group_instance": "PROCESS_GROUP_INSTANCE-A02ED607B5E9DD20"},"timestamps": [1623585600000, 1623628800000, 1623672000000, 1623715200000],"values": [3, null, null, 1]}]}]}
{"totalCount": 1,"nextPageKey": null,"result": [{"metricId": "builtin:service.errors.fivexx.count:splitBy():auto:default(0)","data": [],"warnings": ["The :default operator could not be applied as it requires at least one written data point for the metric in the query timeframe."]}]}
Delta transformation
| Syntax | :delta |
| Arguments | None |
The delta transformation replaces each data point with the difference from the previous data point (0 if the difference is negative). The first data point of the original set is omitted from the result.
You must apply an aggregation transformation before using the delta transformation.
Show example
{"totalCount": 1,"nextPageKey": null,"result": [{"metricId": "builtin:service.keyRequest.count.server:value","data": [{"dimensions": ["SERVICE_METHOD-BD61DD6DAC1EFDE1"],"dimensionMap": {"dt.entity.service_method": "SERVICE_METHOD-BD61DD6DAC1EFDE1"},"timestamps": [1630886400000, 1630929600000, 1630972800000, 1631016000000, 1631059200000],"values": [8338, 8449, 8343, 8372, 8425]}]}]}
Filter transformation
| Syntax | :filter(<condition1>,<condition2>,<conditionN>) |
| Arguments | A list of filtering conditions. A dimension has to match all of the conditions to pass filtering. |
The filter transformation filters the response by the specified criteria. It enables you to filter the data points by a secondary dimension, as entitySelector supports only the first dimension, which is an entity. The combination of scope and filter transformation helps you maximize data filtering efficiency.
Conditions
The :filter transformation supports the following conditions.
| Syntax | Description |
|---|---|
prefix("<dimension>","<expected prefix>") | Matches if the value of the specified dimension starts with the expected prefix. |
suffix("<dimension>","<expected suffix>") | Matches if the value of the specified dimension ends with the expected suffix. |
contains("<dimension>","<expected contained>") | Matches if the value of the specified dimension contains the expected value. |
eq("<dimension>","<expected value>") | Matches if the value of the specified dimension equals the expected value. |
ne("<dimension>","<value to be excluded>") | The reverse of the eq condition. The dimension with the specified name is excluded from the response. |
in("<dimension>",entitySelector("<selector>") | Matches if the value of the specified dimension equals any of the expected values provided by the entity selector. |
existsKey("<dimension>") | Matches if the specified dimension exists. |
remainder("<dimension>") | Matches if the specified dimension is part of the remainder. |
series(<aggregation>,<operator>(<reference value>)) | The response contains only series with data points matching the provided criterion. |
Quotes (") and tildes (~) that are part of the dimension key or dimension value (including entity selector syntax) must be escaped with a tilde (~).
Series condition
The series condition filters the time-aggregated value of the data points for a series by the provided criterion. That is, the specified aggregation is applied and then this single value result is compared to the reference value using the specified operator.
For example, for series(avg, gt(10)), the average over all data points of the series is calculated first, and then this value is checked to see whether it is greater than 10. If a series does not match this criterion, it is removed from the provided result. That is, the series operator cannot be used to filter individual data points of a series. To filter individual data points, you need to use the partition transformation.
The condition supports the following aggregations and operators.
Available aggregations
countminmaxavgsummedianpercentile(N), with N in the0to100range.value
Available operators
lt: lower thanle: lower than or equal toeq: equalne: not equalgt: greater thange: greater than or equal to
Compound condition
Each condition can be a combination of subconditions.
| Syntax | Description |
|---|---|
| All subconditions must be fulfilled. |
| At least one subcondition must be fulfilled. |
| Reverses the subcondition. For example, it turns contains into does not contain. |
Syntax examples
:filter(or(eq("k8s.cluster.name","Server ~"North~""),eq("k8s.cluster.name","Server ~"West~"")))
Filters data points to those delivered by either Server "North" or Server "West".
:filter(and(prefix("App Version","2."),ne("dt.entity.os","OS-472A4A3B41095B09")))
Filters data points to those delivered by an application of major version 2 that is not run on the OS-472A4A3B41095B09 operating system.
Fold transformation
| Syntax | :fold(<aggregation>) |
| Arguments | Optional The required aggregation method. |
The fold transformation combines a data points list into a single data point. To get the result in a specific aggregation, specify the aggregation as an argument. If the specified aggregation is not supported, the default aggregation is used. For example, :fold(median) on a gauge metric equals to :fold(avg) because median is not supported and avg is the default. If an aggregation has been applied in the transformation chain before, the argument is ignored.
Show example
{"metricId": "builtin:host.disk.avail","data": [{"dimensions": ["HOST-BB4DF8969CB41C60", "DISK-FB78447211EE76BF"],"dimensionMap": {"dt.entity.disk": "DISK-FB78447211EE76BF","dt.entity.host": "HOST-BB4DF8969CB41C60"},"timestamps": [1612794060000, 1612794120000, 1612794180000],"values": [4.605786630826667e11, 4.424691002026667e11, 439596351488]}]}
Last transformation
| Syntax | :last<aggregation>:lastReal<aggregation> |
| Arguments | Optional The required aggregation method. |
The last transformation returns the most recent data point from the query timeframe. To get the result in a specific aggregation, specify the aggregation as an argument. If the specified aggregation is not supported, the default aggregation is used. For example, :last(median) on a gauge metric equals to :last(avg) because median is not supported and avg is the default. If an aggregation has been applied in the transformation chain before, the argument is ignored.
If the metric before transformation contains multiple tuples (unique combinations of metric—dimension—dimension value), the most recent timestamp is applied for all tuples. To obtain the actual last timestamp, use the lastReal operator.
Show example
{"totalCount": 3,"nextPageKey": null,"result": [{"metricId": "builtin:apps.other.sessionCount.osAndGeo:names:splitBy(\"dt.entity.geolocation.name\")","data": [{"dimensions": ["Austria"],"dimensionMap": {"dt.entity.geolocation.name": "Austria"},"timestamps": [1617178800000, 1617180000000, 1617181200000, 1617182400000, 1617183600000, 1617184800000],"values": [90, 106, 110, 96, 116, 102]},{"dimensions": ["Switzerland"],"dimensionMap": {"dt.entity.geolocation.name": "Switzerland"},"timestamps": [1617178800000, 1617180000000, 1617181200000, 1617182400000, 1617183600000, 1617184800000],"values": [176, 168, 178, 174, 183, 172]},{"dimensions": ["Germany"],"dimensionMap": {"dt.entity.geolocation.name": "Germany"},"timestamps": [1617178800000, 1617180000000, 1617181200000, 1617182400000, 1617183600000, 1617184800000],"values": [1168, 1121, 1154, 1160, 1108, 1135]}]}]}
Limit transformation
| Syntax | :limit(2) |
| Argument | The maximum number of tuples in the result. |
The limit transformation limits the number of tuples (unique combinations of metric—dimension—dimension value) in the response. Only the first X tuples are included in the response; the rest are discarded.
To ensure that the required tuples are at the top of the result, apply the sort transformation before using the limit.
Show example
{"totalCount": 4,"nextPageKey": null,"result": [{"metricId": "builtin:apps.other.sessionCount.osAndGeo:names:splitBy(\"dt.entity.geolocation.name\"):sort(value(sum,descending))","data": [{"dimensions": ["Austria"],"dimensionMap": {"dt.entity.geolocation.name": "Austria"},"timestamps": [1613559180000],"values": [6593]},{"dimensions": ["Switzerland"],"dimensionMap": {"dt.entity.geolocation.name": "Switzerland"},"timestamps": [1613559180000],"values": [1002]},{"dimensions": ["Germany"],"dimensionMap": {"dt.entity.geolocation.name": "Germany"},"timestamps": [1613559180000],"values": [564]}]}]}
Merge transformation
| Syntax | :merge("<dimension0>","<dimension1>","<dimensionN>") |
| Arguments | A list of dimensions to be removed. A dimension must be specified by its key. Quotes ( ") and tildes (~) that are part of the dimension key must be escaped with a tilde (~). |
The merge transformation removes the specified dimensions from the result. All series/values that have the same dimensions after the removal are merged into one. The values are recalculated according to the selected aggregation.
You can apply any aggregation to the result of the merge transformation, including those that the original metric doesn't support.
Show example
{"totalCount": 2,"nextPageKey": null,"result": [{"metricId": "builtin:synthetic.browser.event.actionDuration.load.geo:count","data": [{"dimensions": ["SYNTHETIC_TEST_STEP-002D5D5A0230A18F", "GEOLOCATION-B69A5A40388CC698"],"dimensionMap": {"dt.entity.synthetic_test_step": "SYNTHETIC_TEST_STEP-97EF148D63564F29","dt.entity.geolocation": "GEOLOCATION-0A41430434C388A9"},"timestamps": [1559865600000, 1560124800000, 1560384000000],"values": [143, 156, 217]},{"dimensions": ["SYNTHETIC_TEST_STEP-002D5D5A0230A18F", "GEOLOCATION-43BA84CAB24D7950"],"timestamps": [1559865600000, 1560124800000, 1560384000000],"values": [773, 804, 801]}]}]}
Names transformation
| Syntax | :names |
| Arguments | None |
| Limitations | Applies only to dimensions of the entity type. |
The names transformation adds the name of the dimension value to the dimensions array and dimensionMap object of the response. The name of each dimension is placed before the ID of the dimension.
Show example
{"dimensions": ["HOST-BB4DF8969CB41C60", "DISK-FB78447211EE76BF"],"dimensionMap": {"dt.entity.disk": "DISK-FB78447211EE76BF","dt.entity.host": "HOST-BB4DF8969CB41C60"}}
Parents transformation
| Syntax | :parents |
| Arguments | None |
| Limitations | Applies only to dimensions of the entity type listed below. |
The parents transformation adds the parent of the dimension to the dimensions array and dimensionMap object of the response. The parent of each dimension is placed before the dimension itself.
This transformation works only if the dimension entity is part of another, bigger entity. For example, PROCESS_GROUP_INSTANCE is always the child of the HOST it runs on. The following relationships are supported.
| Child dimension | Parent dimension |
|---|---|
| SERVICE_METHOD | SERVICE |
| SERVICE_INSTANCE | SERVICE |
| APPLICATION_METHOD | APPLICATION |
| PROCESS_GROUP_INSTANCE | HOST |
| DISK | HOST |
| NETWORK_INTERFACE | HOST |
| SYNTHETIC_TEST_STEP | SYNTHETIC_TEST |
| HTTP_CHECK_STEP | HTTP_CHECK |
| EXTERNAL_SYNTHETIC_TEST_STEP | EXTERNAL_SYNTHETIC_TEST |
Show example
{"dimensions": ["SERVICE_METHOD-D9D3A16FA577BF1C"],"dimensionMap": {"dt.entity.service": "SERVICE-C22F1E8EA66FF4C5"}}
Partition transformation
Syntax |
|
Arguments |
|
The partition transformation splits data points of a series based on the specified criteria. It introduces a new dimension (the partition dimension), with the value determined by a partition criterion. Data points from the original series are distributed between one or several new series according to partition criteria. In each new series, data points that don't pass the criterion or are already taken by another criterion are replaced with null.
Partition syntax
A single transformation can contain several partitions. These are evaluated from top to bottom; the first matching partition applies.
Each partition must contain a value for the partition dimension that will mark the passed data points and a criterion by which to filter data points.
Note that you can use either the value or the dimension condition, but not both, in a single partition operator. You can always use otherwise conditions.
Value conditions
You need to apply an aggregation transformation before using value conditions within the partition transformation.
value("<partition dimension value>",<criterion>)
The following criteria are available:
| Syntax | Description |
|---|---|
lt(X) | Less than X |
le(X) | Less than or equal to X |
eq(X) | Equal to X |
ne(X) | Not equal to X |
ge(X) | Greater than or equal to X |
gt(X) | Greater than X |
range(X,Y) | Greater than or equal to X and less than Y |
or(<criterion1>,<criterionN>) | At least one sub-criterion must be fulfilled. |
and(<criterion1>,<criterionN>) | All sub-criteria must be fulfilled. |
not(<criterion>) | Negated criterion matching all values that do not fulfill the criterion |
Dimension conditions
dimension("<partition dimension value>",<criterion>)
The following criteria are available.
| Syntax | Description |
|---|---|
prefix("<dimension>","<expected prefix>") | Matches if the value of the specified dimension starts with the expected prefix. |
suffix("<dimension>","<expected suffix>") | Matches if the value of the specified dimension ends with the expected suffix. |
contains("<dimension>","<expected contained>") | Matches if the value of the specified dimension contains the expected value. |
eq("<dimension>","<expected value>") | Matches if the value of the specified dimension equals the expected value. |
ne("<dimension>","<value to be excluded>") | The reverse of the eq condition—the dimension with the specified name is excluded from the response. |
or(<criterion1>,<criterionN>) | At least one sub-criterion must be fulfilled. |
and(<criterion1>,<criterionN>) | All sub-criteria must be fulfilled. |
not(<criterion>) | Negated criterion matching all values that do not fulfill the criterion |
Otherwise condition
otherwise("<partition dimension value>")
A universal operator matching all values—use it at the end of a partition chain as the default case.
Show example
The following partition transformation is used in this example.
:partition("Action duration",value("slow",gt(200)),value("fast",lt(100)),value("normal",otherwise))
It adds the Action duration dimension to the metric and splits data points into three categories based on it.
fastfor actions faster than100millisecondsslowfor actions slower than200millisecondsnormalfor all other actions
{"totalCount": 1,"nextPageKey": null,"resolution": "10m","result": [{"metricId": "builtin:apps.web.action.domInteractive.load.browser:avg","data": [{"dimensions": ["APPLICATION_METHOD-E418A4BC1DC2C911", "BROWSER-EFB8A292CB368A8D"],"dimensionMap": {"dt.entity.browser": "BROWSER-EFB8A292CB368A8D","dt.entity.application_method": "APPLICATION_METHOD-E418A4BC1DC2C911"},"timestamps": [1637152200000, 1637152800000, 1637153400000, 1637154000000, 1637154600000,1637155200000, 1637155800000, 1637156400000, 1637157000000, 1637157600000,1637158200000, 1637158800000, 1637159400000],"values": [155, 215, 247, 118, 94, 119, 67, 159, 114, 169, 113, 75, 160]}]}]}
Rate transformation
Syntax |
|
Argument | The base of the rate. The following values are supported:
|
The rate transformation converts a count-based metric (for example, bytes) into a rate-based metric (for example, bytes per minute).
Any argument can be modified by an integer factor. For example, 5m means per 5 minutes rate. If no argument is specified, the per 1 minute rate is used.
You can use the rate transformation with any metric that supports the VALUE aggregation. Query a metric with the GET metric descriptors call to obtain information about available aggregations. If the metric doesn't support the VALUE aggregation, apply the aggregation transformation first and then the rate transformation.
- You must apply an aggregation transformation before using the rate transformation.
- You can use the rate transformation only once in a single transformation chain.
Rollup transformation
Syntax |
|
Arguments |
|
The rollup transformation smoothes data points, removing any spikes from the requested timeframe.
The transformation takes each data point from the query timeframe, forms a rollup window by looking into past data points (so the initial data point becomes the last point of the window), calculates the requested aggregation of all original values, and then replaces each data point in the window with the result of the calculation.
For example, if you specify :rollup(avg,5m) and the resolution of the query is one minute, the transformation takes a data point, adds the four previous data point to form a rollup window, and then uses the average of these five datapoints to calculate the final datapoint value.
- You must apply an aggregation transformation before using the rollup transformation.
- The rollup window duration is limited to 60 minutes.
- You can roll up data from the last 2 weeks (including rollup windows) only. That is, the oldest data point of your query can't be more than
2w-windowDurationin the past.
Show example
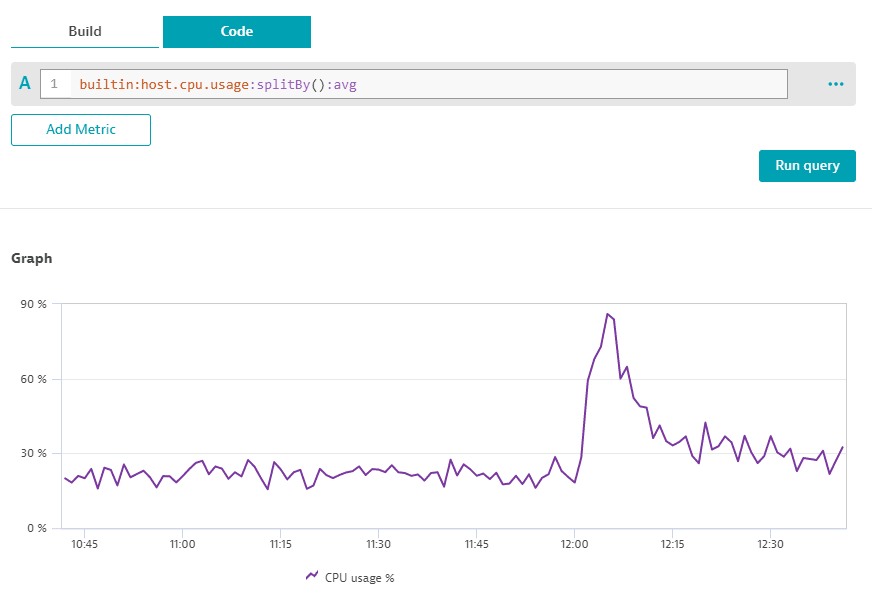
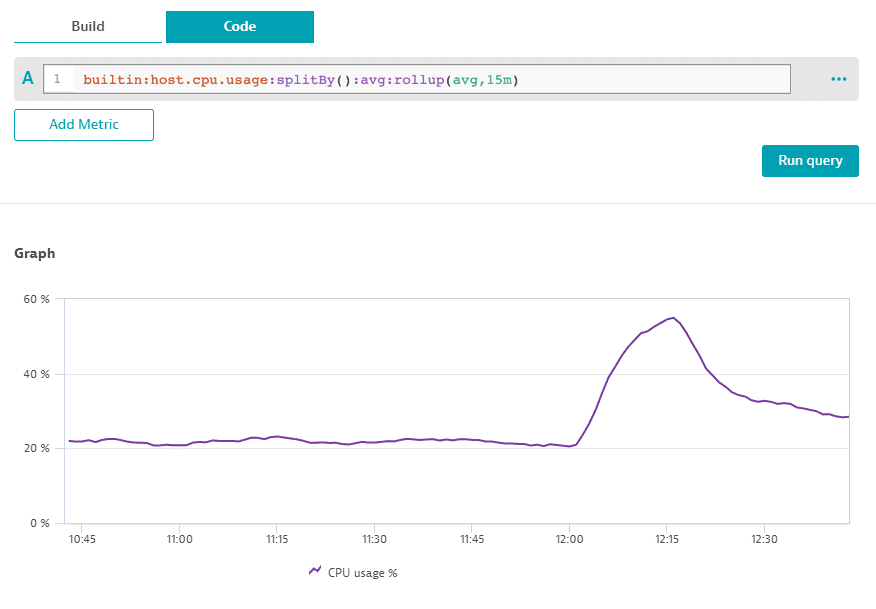
Smooth transformation
| Syntax | :smooth(skipfirst) |
| Argument | The smoothing strategy. Only the skipfirst strategy is supported. |
The smooth transformation smooths a series of data points after a data gap (one or several data points with the value of null).
The skipfirst strategy replaces the first data point after the data gap with null.
Show example
{"totalCount": 1,"nextPageKey": null,"result": [{"metricId": "builtin:service.keyRequest.count.server","data": [{"dimensions": ["SERVICE_METHOD-BBA9C77B774B0C15"],"dimensionMap": {"dt.entity.service_method": "SERVICE_METHOD-BBA9C77B774B0C15"},"timestamps": [1628618460000, 1628618520000, 1628618580000, 1628618640000, 1628618700000,1628618760000, 1628618820000, 1628618880000, 1628618940000, 1628619000000],"values": [null, 15, 13, 15, null, null, 28, 14, 14, 13]}]}]}
Sort transformation
| Syntax | :sort(<sorting key 1>,<sorting key 2>) |
| Arguments | One or several sorting keys. |
The sort transformation specifies the order of tuples (unique combinations of metric—dimension—dimension value) in the response. You can specify one or several sorting criteria. The first criterion is used for sorting. Further criteria are used for tie-breaking. You can choose the direction of the sort:
ascendingdescending
You can also specify the type of sort:
lexicalnatural
Dimension sorting
To sort results by the value of a dimension, use the dimension("<dimension>", <direction>) or dimension("<dimension>", <direction>, <type>) key. Quotes (") and tildes (~) that are part of the dimension key must be escaped with a tilde (~).
Entity dimensions are sorted lexicographically (0..9a..z) by Dynatrace entity ID values.
String dimensions are sorted lexicographically.
Sorting type
The sorting type defines how dimension values are ordered.
The lexical sorting type arranges dimension strings lexicographically (for example, 1,11,2,21,3). This is the default sorting type when no type is explicitly specified, as in dimension("<dimension>", ascending). You can also specify it explicitly using dimension("<dimension>", <direction>, lexical).
The natural sorting type arranges dimension strings in a human-friendly, natural order (for example, 1,2,3,11,21). It can be specified using dimension("<dimension>", <direction>, natural).
Data points sorting
To sort results by metric data points in a dimension, use the value(<aggregation>,<direction>) key.
The following aggregations are available:
avgcountmaxmedianminsumpercentile(N), with N in the0to100range.value
The aggregation is used only for sorting and doesn't affect the returned data points.
The sorting is applied to the resulting data points of the whole transformation chain before the sort transformation. If the transformation chain doesn't have an aggregation transformation, the sorting is applied to the default aggregation of the metric.
Show example
{"totalCount": 4,"nextPageKey": null,"result": [{"metricId": "builtin:apps.other.sessionCount.osAndGeo:names:splitBy(\"dt.entity.geolocation.name\")","data": [{"dimensions": ["Austria"],"dimensionMap": {"dt.entity.geolocation.name": "Austria"},"timestamps": [1613557980000],"values": [6543]},{"dimensions": ["Switzerland"],"dimensionMap": {"dt.entity.geolocation.name": "Switzerland"},"timestamps": [1613557980000],"values": [1009]},{"dimensions": ["Germany"],"dimensionMap": {"dt.entity.geolocation.name": "Germany"},"timestamps": [1613557980000],"values": [6673]},{"dimensions": ["Lichtenstein"],"dimensionMap": {"dt.entity.geolocation.name": "Lichtenstein"},"timestamps": [1613557980000],"values": [86]}]}]}
Split by transformation
| Syntax | :splitBy("<dimension0>","<dimension1>","<dimensionN>") |
| Arguments | A list of dimensions to be preserved in the result. A dimension must be specified by its key. Quotes ( ") and tildes (~) that are part of the dimension key must be escaped with a tilde (~). |
The split by transformation keeps the specified dimensions in the result and merges all remaining dimensions. The values are recalculated according to the selected aggregation. Only metric series that have each of the specified dimensions are considered.
You can apply any aggregation to the result of the split by transformation, including those that the original metric doesn't support.
Show example
{"totalCount": 4,"nextPageKey": null,"result": [{"metricId": "builtin:apps.other.sessionCount.osAndGeo:names","data": [{"dimensions": ["easyTravel Demo","MOBILE_APPLICATION-752C288D59734C79","Android","OS-472A4A3B41095B09","Switzerland","GEOLOCATION-976217DC7560B588"],"dimensionMap": {"dt.entity.device_application.name": "easyTravel Demo","dt.entity.os": "OS-472A4A3B41095B09","dt.entity.os.name": "Android","dt.entity.device_application": "MOBILE_APPLICATION-752C288D59734C79","dt.entity.geolocation.name": "Switzerland","dt.entity.geolocation": "GEOLOCATION-976217DC7560B588"},"timestamps": [1612950360000],"values": [557]},{"dimensions": ["easyTravel Demo","MOBILE_APPLICATION-752C288D59734C79","Android","OS-472A4A3B41095B09","Austria","GEOLOCATION-EADFE05E062C8D33"],"dimensionMap": {"dt.entity.device_application.name": "easyTravel Demo","dt.entity.os": "OS-472A4A3B41095B09","dt.entity.os.name": "Android","dt.entity.device_application": "MOBILE_APPLICATION-752C288D59734C79","dt.entity.geolocation.name": "Austria","dt.entity.geolocation": "GEOLOCATION-EADFE05E062C8D33"},"timestamps": [1612950360000],"values": [328]},{"dimensions": ["easyTravel Demo","MOBILE_APPLICATION-752C288D59734C79","iOS","OS-62028BEE737F03D4","Switzerland","GEOLOCATION-976217DC7560B588"],"dimensionMap": {"dt.entity.device_application.name": "easyTravel Demo","dt.entity.os": "OS-62028BEE737F03D4","dt.entity.os.name": "iOS","dt.entity.device_application": "MOBILE_APPLICATION-752C288D59734C79","dt.entity.geolocation.name": "Switzerland","dt.entity.geolocation": "GEOLOCATION-976217DC7560B588"},"timestamps": [1612950360000],"values": [383]},{"dimensions": ["easyTravel Demo","MOBILE_APPLICATION-752C288D59734C79","iOS","OS-62028BEE737F03D4","Austria","GEOLOCATION-EADFE05E062C8D33"],"dimensionMap": {"dt.entity.device_application.name": "easyTravel Demo","dt.entity.os": "OS-62028BEE737F03D4","dt.entity.os.name": "iOS","dt.entity.device_application": "MOBILE_APPLICATION-752C288D59734C79","dt.entity.geolocation.name": "Austria","dt.entity.geolocation": "GEOLOCATION-EADFE05E062C8D33"},"timestamps": [1612950360000],"values": [214]}]}]}
Time shift transformation
Syntax |
|
Argument | The period of the shift. The following values are supported:
|
The time shift transformation shifts the timeframe specified by the from and to query parameters and maps the resulting data points to timestamps from the original timeframe. It can help you hand data from different time zones or put yesterday's and today's data on the same chart for visual comparison.
A positive argument shifts the timeframe into the future; a negative argument shifts the timeframe into the past. In either case, there's a limit of 5 years.
You can use this transformation to handle data from different time zones.
Let's consider an example with a timeframe from 1615550400000 (March 12, 2021 13:00 CET) to 1615557600000 (March 12, 2021 15:00 CET) and a time shift of -1d (one day into the past).
- The data points will be queried for the timeframe from
1615464000000(March 11, 2021 13:00 CET) to1615471200000(March 11, 2021 15:00 CET). - Timestamps in the response will be aligned to the original timeframe. For example, the data point with a timestamp of
1615465800000(March 11, 2021 13:30 CET) will be returned as1615552200000(March 12, 2021 13:30 CET).
Unit transformations
Set unit
| Syntax | :setUnit(<unit>) |
| Argument | The desired unit. To fetch the list of available units, use the GET all units API call. |
The setUnit transformation sets the unit in the metric metadata.
This transformation does not affect data points.
To unit
| Syntax | :toUnit(<sourceUnit>,<targetUnit>) |
| Arguments | The source and the target unit of the transformation. To fetch the list of available units, use the GET all units API call. |
The toUnit transformation converts data points from the source unit to target unit. If specified units are incompatible, the original unit is persisted and a warning is included in the response.
You must apply an aggregation transformation before using the unit transformations.