NVIDIA NIM
- Latest Dynatrace
- Explanation
- 2-min read
NVIDIA NIM (NVIDIA Inference Microservices) is a set of microservices that accelerate foundation model deployment on any cloud or data center, optimizing AI infrastructure for efficiency and cost-effectiveness while reducing hardware and operational costs.
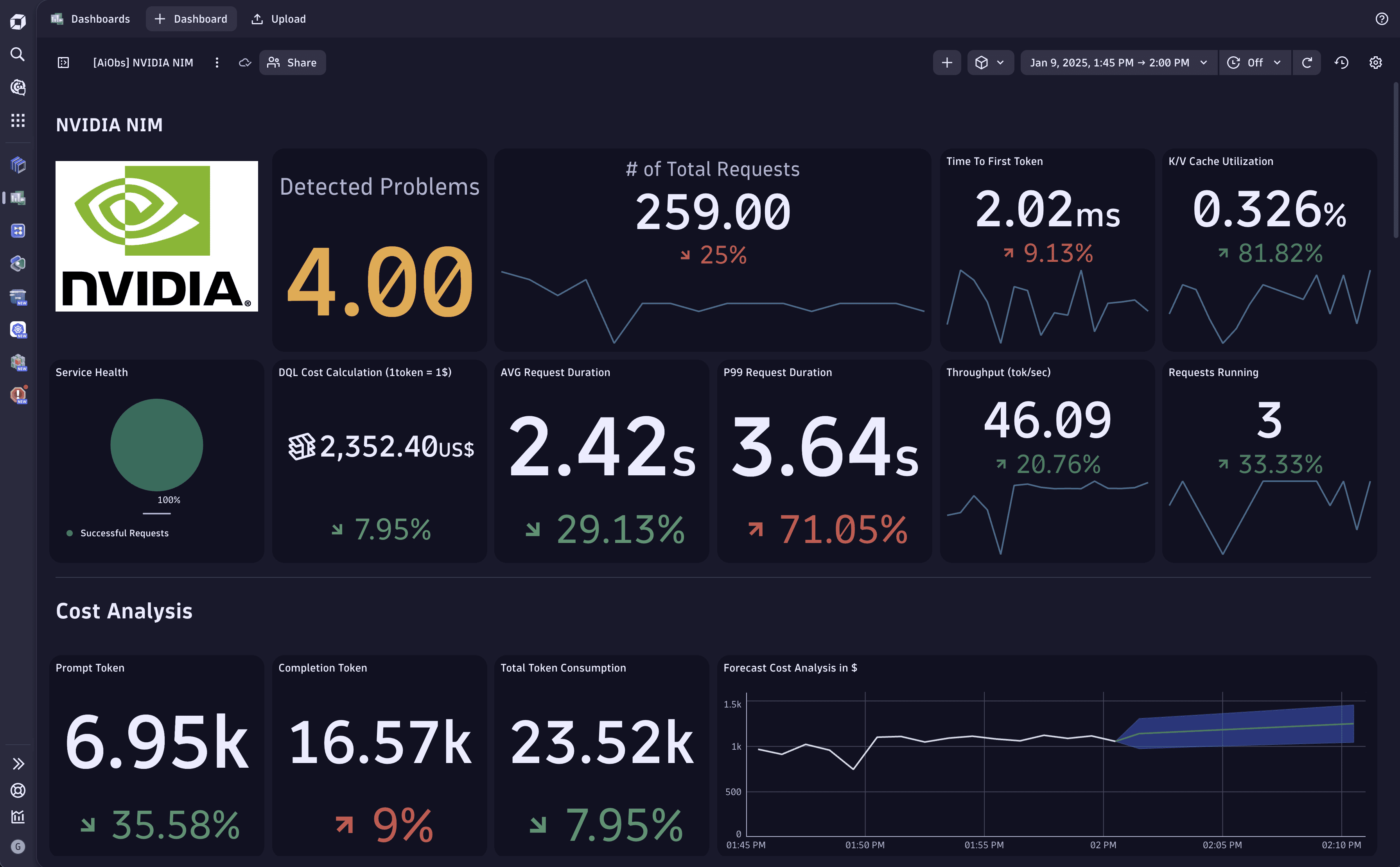
Explore the sample dashboard on the Dynatrace Playground.
Enable monitoring
Follow the Set up Dynatrace on Kubernetes guide to monitor your cluster.
Afterwards, add the following annotations to your NVIDIA NIM deployments:
metrics.dynatrace.com/scrape: "true"metrics.dynatrace.com/port: "8000"
Spans
The following attributes are available for GenAI Spans.
| Attribute | Type | Description |
|---|---|---|
gen_ai.completion.0.content | string | The full response received from the GenAI model. |
gen_ai.completion.0.content_filter_results | string | The filter results of the response received from the GenAI model. |
gen_ai.completion.0.finish_reason | string | The reason the GenAI model stopped producing tokens. |
gen_ai.completion.0.role | string | The role used by the GenAI model. |
gen_ai.openai.api_base | string | GenAI server address. |
gen_ai.openai.api_version | string | GenAI API version. |
gen_ai.openai.system_fingerprint | string | The fingerprint of the response generated by the GenAI model. |
gen_ai.prompt.0.content | string | The full prompt sent to the GenAI model. |
gen_ai.prompt.0.role | string | The role setting for the GenAI request. |
gen_ai.prompt.prompt_filter_results | string | The filter results of the prompt sent to the GenAI model. |
gen_ai.request.max_tokens | integer | The maximum number of tokens the model generates for a request. |
gen_ai.request.model | string | The name of the GenAI model a request is being made to. |
gen_ai.request.temperature | double | The temperature setting for the GenAI request. |
gen_ai.request.top_p | double | The top_p sampling setting for the GenAI request. |
gen_ai.response.model | string | The name of the model that generated the response. |
gen_ai.system | string | The GenAI product as identified by the client or server instrumentation. |
gen_ai.usage.completion_tokens | integer | The number of tokens used in the GenAI response (completion). |
gen_ai.usage.prompt_tokens | integer | The number of tokens used in the GenAI input (prompt). |
llm.request.type | string | The type of the operation being performed. |
Metrics
The following metrics will be available:
| Metric | Type | Unit | Description |
|---|---|---|---|
e2e_request_latency_seconds | histoGrailm | s | Histogram of end-to-end request latency in seconds |
generation_tokens_total | counter | integer | Number of generation tokens processed |
gpu_cache_usage_perc | gauge | integer | GPU KV-cache usage. 1 means 100 percent usage |
num_request_max | counter | integer | Maximum number of concurrently running requests |
num_requests_running | counter | integer | Number of requests currently running on GPU |
num_requests_waiting | counter | integer | Number of requests waiting to be processed |
prompt_tokens_total | counter | integer | Number of prefill tokens processed |
request_failure_total | counter | integer | Number of failed requests; requests with other finish reason are counted |
request_finish_total | counter | integer | Number of finished requests, with label indicating finish reason |
request_generation_tokens | histogram | integer | Histogram of number of generation tokens processed |
request_prompt_tokens | histogram | integer | Histogram of number of prefill tokens processed |
request_success_total | counter | integer | Number of successful requests; requests with finish reason "stop" or "length" are counted |
time_per_output_token_seconds | histogram | s | Histogram of time per output token in seconds |
time_to_first_token_seconds | histogram | s | Histogram of time to first token in seconds |
Additionally, the following metrics are reported.
| Metric | Type | Unit | Description |
|---|---|---|---|
gen_ai.client.generation.choices | counter | none | The number of choices returned by chat completions call. |
gen_ai.client.operation.duration | histogram | s | The GenAI operation duration. |
gen_ai.client.token.usage | histogram | none | The number of input and output tokens used. |
llm.openai.embeddings.vector_size | counter | none | The size of returned vector. |
Related topics
Related tags
AI Observability