Rack-aware deployment
- Explanation
- 3-min read
Dynatrace Managed rack-aware deployment allows you to group Managed Cluster nodes into three fault domains (racks). A rack-aware deployment is resilient to an outage of all nodes in a rack. You can make a single Managed Cluster rack-aware, or apply rack awareness to each data center in a Premium High Availability (PHA) deployment.
How rack-aware deployment works
Rack-aware deployment ensures that no replica is stored redundantly inside a single rack, so replicas are spread across all racks. If one rack goes down, the other two full replicas are available, ensuring data consistency and availability. For example, in the deployment below, the Managed Cluster can handle up to three node failures in a rack before data loss.
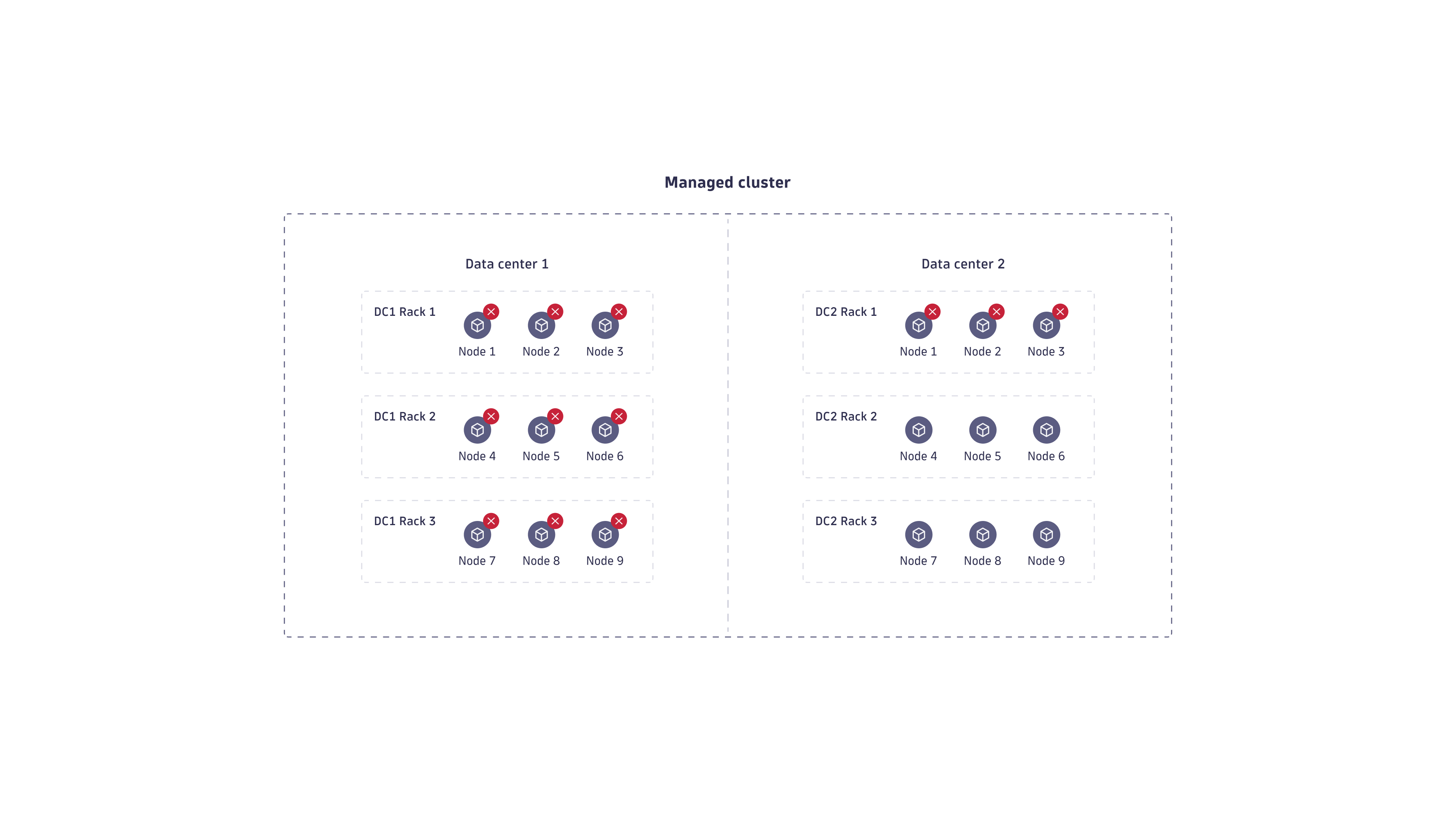
In a standard Dynatrace Managed high availability deployment, you need at least three Managed Cluster nodes to prevent data loss. Similarly, in rack-aware deployments, you must have three racks (fault domains) to prevent data loss. If a rack fails, the surviving two racks maintain the data. Given that the rack contains at least three nodes, in rack-aware deployments, you can afford a failure of the entire rack and still maintain data integrity.
The same concept applies to PHA Managed deployments. Using rack-aware Managed Cluster deployments in separate data centers increases your resilience to data loss.
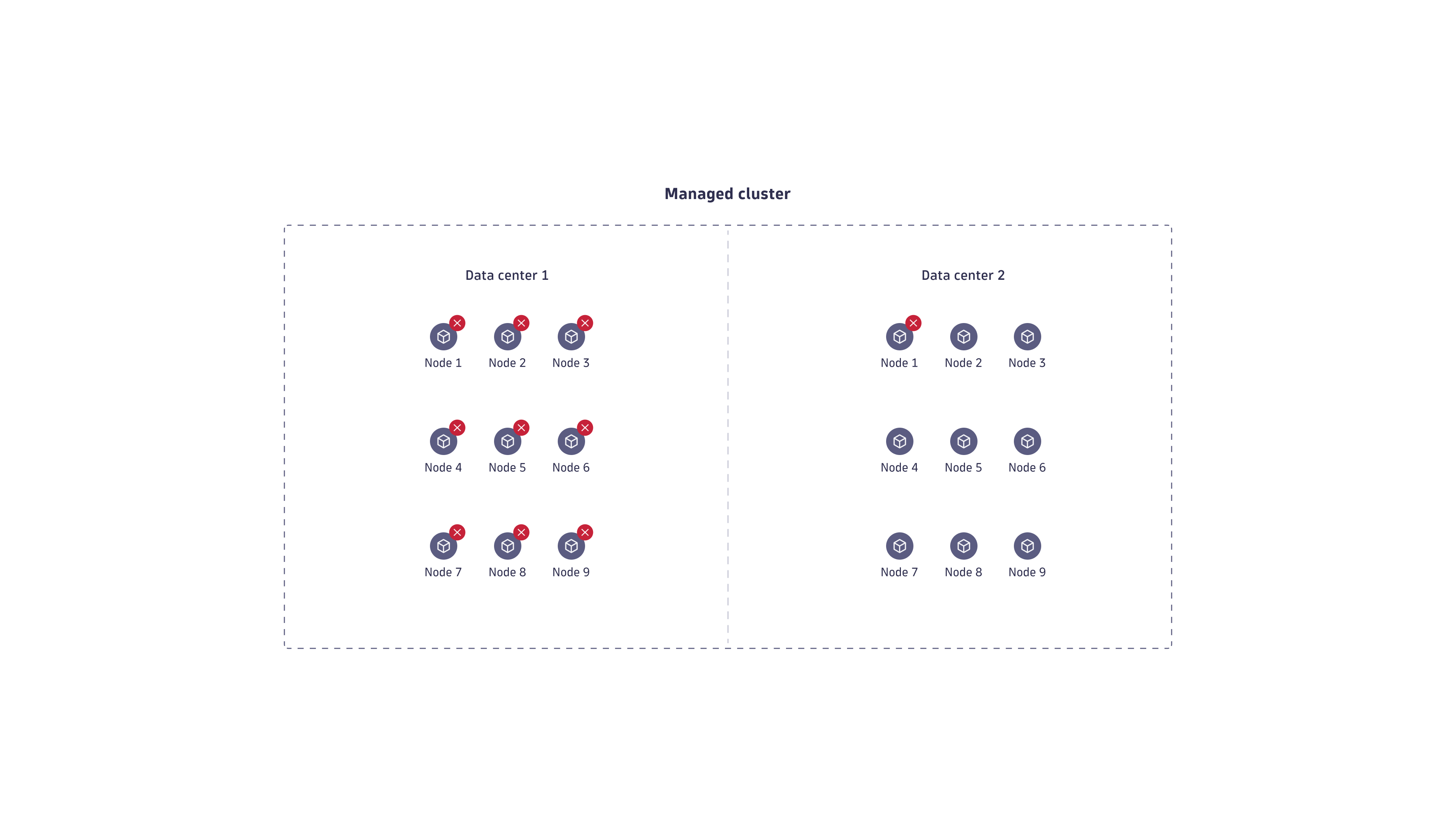
For the ultimate high availability and redundancy, use the PHA deployment that's rack-aware.
Prerequisites
Use rack awareness only if:
- The final number of racks is three, corresponding to the replication factor of Dynatrace data storage.
- Racks reflect the underlying physical deployment location of nodes.
- Racks are in the same low-latency network. Typically, this means the same local area network. If racks are in separate sites connected over a wide area network, network latency between sites needs to stay below 10 ms.
Otherwise, you may lose data and have issues with Managed Cluster availability.
Set up rack-aware deployment
To create a rack-aware deployment during the initial Managed deployment, use the installation parameters to indicate the data center and the rack for each node. See Install a Managed Cluster and Customize installation for Dynatrace Managed. For example:
dynatrace-managed.sh --rack-name az-1 --rack-dc datacenter1
To convert an existing Managed Cluster to rack-aware, choose a method based on your metric storage size:
- Use the rack-aware conversion using replication method for small Managed Clusters where one node can contain a full replica. This method doesn't cause Managed Cluster downtime.
- Use the rack-aware conversion using restore method when your metric storage (Cassandra database) per node is more than 1 TB. The cluster expansion method also works, but the required Cassandra bootstrapping takes an unreasonably long time.