Cloud application and workload detection
- Dynatrace Classic
- How-to guide
- 6-min read
Dynatrace allows automatic detection of cloud applications and workloads in your Cloud Foundry, Docker and Podman, and Kubernetes/OpenShift environments. Cloud applications and workloads group similar processes into process groups and services and thus allow for version analysis.
Cloud application and workload detection provides
- Insights into your Kubernetes namespaces, workloads, and pods
- Container resource metrics for Kubernetes and Cloud Foundry containers
- Version detection for services that run in Kubernetes workloads
Starting with Dynatrace version 1.258 and OneAgent version 1.257
-
This feature is enabled by default.
-
You can configure Cloud application and workload detection independently for Kubernetes, Cloud Foundry, and plain Docker and Podman environments:
- Go to Settings.
- Select Processes and containers > Cloud application and workload detection.
- Turn on/off Enable cloud application and workload detection […] for Cloud Foundry, Docker and Podman, or Kubernetes/OpenShift as needed.
- Select Save changes.
OneAgents version 1.256 and earlier do not support independent configuration per environment type. For these OneAgents, cloud application and workload detection is only enabled if the setting is activated for all three environments: Cloud Foundry, Docker and Podman, Kubernetes/OpenShift.
Starting with Dynatrace version 1.299 and OneAgent version 1.297, Dynatrace features automatic container detection based on captured cloud-vendor metadata, such as AWS ECS, AWS Fargate, Azure Container Apps, and many more. You can configure container detection as follows:
- Go to Settings.
- Select Processes and containers > Cloud application and workload detection.
- Turn on/off Enable container detection for serverless container services as needed.
- Select Save changes.
See below for how to use Kubernetes workload properties for grouping processes of similar workloads. In addition, generic process detection rules still apply, while ignoring container or platform specific properties.
Workload detection rules for Kubernetes
By default, Dynatrace separates process groups and services for every Kubernetes workload.
You can define rules to support your release strategies (such as blue/green, canary) by using workload properties like Namespace name, Base pod name, or Container name, as well as the environment variables DT_RELEASE_STAGE and DT_RELEASE_PRODUCT for grouping processes of similar workloads. You can also specify the version and build version of the deployed workload by setting the DT_RELEASE_VERSION and DT_RELEASE_BUILD_VERSION environment variables. This gives you extended visibility into the impact of releases on your services.
The rules are scoped for Kubernetes namespaces so that you can easily migrate your existing environment namespace by namespace. The first applicable rule in the list is applied. If no rule matches, the combination of Namespace name, Base pod name, and Container name is used as a fallback.
To create a rule
- Go to Settings.
- Select Processes and containers > Cloud application and workload detection.
- Select Add rule.
- Use a combination of the five input variables below to calculate how process groups are detected.
-
Namespace name
-
Base pod name (e.g. "paymentservice-" for "paymentservice-5ff6dbff57-gszgq")
-
Container name (as defined in the pod spec)
-
Stage (
DT_RELEASE_STAGE) -
Product (
DT_RELEASE_PRODUCT)If Product is enabled and has no value, it defaults to Base pod name.
-
Set Match operator and Namespace name to define namespaces to which you want this rule to apply.
-
Select Save changes.
Note that changes to the Cloud application and workload detection rules require a restart of the pods to take effect.
Changing the default rules may lead to the creation of new IDs for process groups and services, and the loss of custom configurations on existing process groups.
Once your process groups or services gain new IDs, be aware that:
- Any custom configurations won't be transitioned to the new process group or service. This includes names, monitoring settings, and error and anomaly detection settings.
- Any existing custom alerts, custom charts on dashboards, or filters that are mapped to the overwritten IDs of individual process groups or services will no longer work or display monitoring data.
- Any integrations with the Dynatrace API where specific process groups or services are queried will need to be updated.
Impact on the default process group naming
OneAgent versions 1.241+
Dynatrace aims to provide intuitive names for process groups that make sense for DevOps teams. Creating rules for Kubernetes workloads also affects the composition of meaningful default names for process groups. The default pattern for {ProcessGroup:DetectedName} is as follows: “<tech_prefix> <product> <STAGE> <base_pod_name>”, where
<tech_prefix>refers to names from detected technologies, such as the name of a technology, executable, path, and startup class.<product>,<STAGE>,<base_pod_name>are optional variables and only used when included in the rule that has been applied for the respective Kubernetes namespace.
Example: "index.js emailservice PROD", where
index.jsis<tech_prefix>emailserviceis<product>PRODis<STAGE>
<base_pod_name> isn't used in this case, so it's not included in {ProcessGroup:DetectedName}.
If the default process group naming is too generic or doesn't reflect your naming standards, you can always customize it by creating process group naming rules.
Example - best practices with Kubernetes labels
We recommend that you propagate Kubernetes labels to environment variables in the deployment configuration (see Version detection with Kubernetes labels) using the Downward API:
-
app.kubernetes.io/version->DT_RELEASE_VERSION -
app.kubernetes.io/name->DT_RELEASE_PRODUCT -
app.kubernetes.io/stage->DT_RELEASE_STAGE
apiVersion: apps/v1kind: Deploymentmetadata:name: emaildeployspec:selector:matchLabels:app: emailservicetemplate:metadata:annotations:metrics.dynatrace.com/path: /stats/prometheusmetrics.dynatrace.com/port: "15090"metrics.dynatrace.com/scrape: "true"labels:app: emailserviceapp.kubernetes.io/version: 0.3.6app.kubernetes.io/stage: productionapp.kubernetes.io/name: emailserviceapp.kubernetes.io/part-of: online-boutiquespec:serviceAccountName: defaultterminationGracePeriodSeconds: 5containers:- name: serverimage: gcr.io/google-samples/microservices-demo/emailservice:v0.3.6ports:- containerPort: 8080env:- name: PORTvalue: "8080"- name: DT_RELEASE_VERSIONvalueFrom:fieldRef:fieldPath: metadata.labels['app.kubernetes.io/version']- name: DT_RELEASE_PRODUCTvalueFrom:fieldRef:fieldPath: metadata.labels['app.kubernetes.io/name']- name: DT_RELEASE_STAGEvalueFrom:fieldRef:fieldPath: metadata.labels['app.kubernetes.io/stage']- name: DISABLE_TRACINGvalue: "1"- name: DISABLE_PROFILERvalue: "1"readinessProbe:periodSeconds: 5exec:command: ["/bin/grpc_health_probe", "-addr=:8080"]livenessProbe:periodSeconds: 5exec:command: ["/bin/grpc_health_probe", "-addr=:8080"]resources:requests:cpu: 100mmemory: 64Milimits:cpu: 200mmemory: 128Mi---
As a next step, this configuration can then be easily leveraged with one rule - Namespace exists.
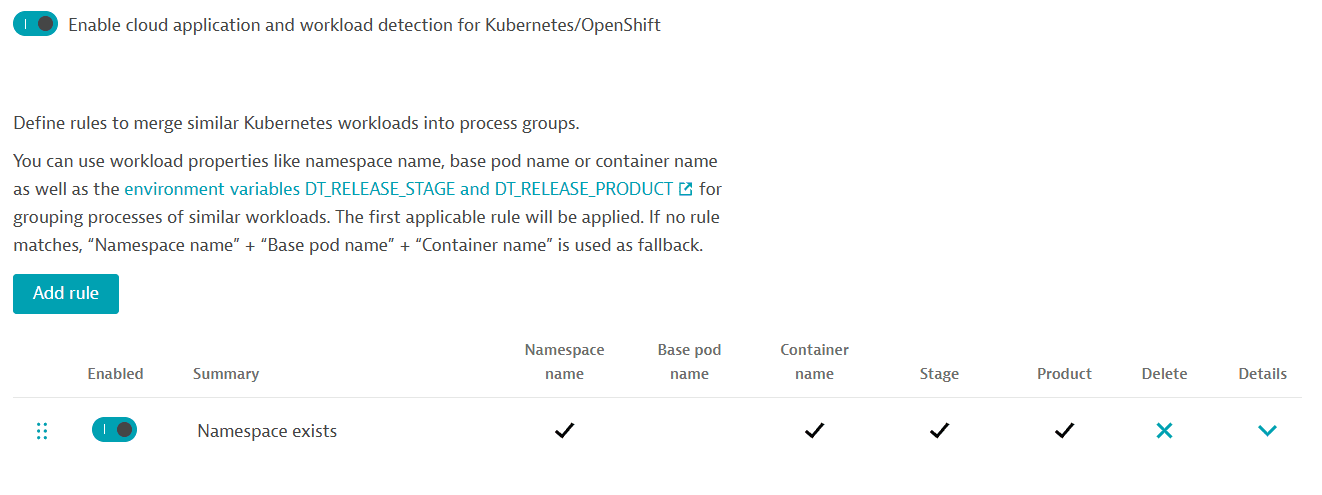
As an outcome of the applied configuration, Dynatrace will merge similar processes and services with the same Product, Stage, Container name, and Namespace values. Because all these values are identical, this rule also makes workloads merge across different Kubernetes clusters into the same process group.