Process group detection
- Dynatrace Classic
- How-to guide
- 10-min read
Dynatrace detects which processes are part of the same process groups by means of a default set of detection rules.
You can change the structure of default process groups by modifying the default process-group detection logic in:
-
Settings > Processes and containers > Process group detection section, which has the following pages:
- On the Built-in detection rules page, you can enable or disable specific process group detection toggles. Hover over the info icon to the right of each toggle for details.
- On the Simple detection rules and Advanced detection rules pages, you can add your own process group detection rules, which will override the default ones.
- On the Declarative process grouping page, you can monitor specific processes of a technology that is unknown to Dynatrace.
-
Settings > Processes and containers > Containers > Cloud application and workload detection, where you can define rules to merge similar Kubernetes workloads into process groups.
- Process group detection settings and rules require a restart of your processes to affect how processes are identified and grouped.
- Process group detection settings and rules only affect the composition of process groups. If you want to change how a process group is named, you have to use the process group naming rules instead.
- It's also possible to use host groups to separate clusters into different process groups.
Simple detection rules
Simple process group detection rules enable you to adapt the default process-group detection logic for deep monitored processes via Java system properties or environment variables. You can create a simple detection rule using the Dynatrace web UI or the Settings API - see Example JSON payload for a simple detection rule.
Simple process-group detection rules are only effective when OneAgent is installed on your hosts or images for processes that can be deep monitored.
This feature can only split a process group into multiple parts. Use it if you have different deployments into the same process group.
To create a simple detection rule in the Dynatrace web UI
-
Go to Settings.
-
Select Processes and containers > Simple detection rules.
-
Select Add item.
-
Set Property source to Java system property or Environment variable.
-
Set Group identifier to a value that Dynatrace will use to identify process groups.
-
Optional Set Instance identifier to a value that Dynatrace will use to identify specific cluster nodes within a process group.
This setting is useful if your process group setup has specific names per node. If you're not sure, leave the field empty. The default setting is one node per host.
-
Optional Set Restrict this rule to specific process types to the type of process to which you want to apply the rule.
-
Select Save changes.
Java system properties
With this option, you can create more fine-grained groups of Java processes.
The Java system property needs to be part of the Java command line to be detected by OneAgent. It can either be an existing system property that your application already uses (for example, three different jetty.home values for three different Solr clusters), or you can add a new system property. As long as the system property is available on the command line, Dynatrace can use it.
Environment variables
This option covers both Java and non-Java processes like NGINX, Apache HTTPserver, FPM/PHP, Node.js, IIS, and .NET. The environment variables that you select as process group identifiers must exist within the scope of the detected processes and be visible at application startup.
- For WebSphere, you can do this in the WebSphere console in the JVM section.
- For Tomcat and others, simply define the environment variable as part of the startup script.
We recommend creating environment variables specific to process detection. Environment variables that serve other scopes, such as DT_TAGS or DT_CUSTOM_PROP, might cause incorrect or unintentional splits because all values of environment variables are evaluated for process-group detection.
Identifiers also serve as the default name for the detected process groups. See Define your own process group metadata for details on how to define an environment variable for IIS or for Windows services.
Example:
Suppose you have two nearly identical Apache HTTP server deployments that reside within the same deployment directory but on different hosts. By default, Dynatrace can't distinguish between the two deployments because they don't have any unique characteristics that can be used for identification. Now consider the following rule: Apache process identified by environment variable MY_PG_NAME.
Any Apache HTTP process that includes the environment variable MY_PG_NAME within its scope will use the content of "MY_PG_NAME" as both its identifier and its default name. In this scenario, you can have Dynatrace separately identify and name each deployment by assigning the environment variable MY_PG_NAME=dynatrace.com-production to one deployment, and MY_PG_NAME=dynatrace.com-staging to the other deployment.
Advanced detection rules
Advanced process group detection rules allow you to create a process group by merging processes from different groups, and enable you to adapt the detection logic for deep monitored processes by leveraging properties that are automatically detected by OneAgent during the startup of a process. You can create an advanced detection rule using the Dynatrace web UI or the Settings API - see Example JSON payload for an advanced detection rule.
Advanced process-group detection rules are only effective when OneAgent is installed on your hosts or images for processes that can be deep monitored.
To create an advanced detection rule in the Dynatrace web UI
-
Go to Settings.
-
Select Processes and containers > Advanced detection rules.
-
Select Add item.
-
In the Process group detection section, define to which processes this rule should be applied. For example, to a Java JAR file that contains
ws-server.jar. -
In the Process group extraction section, select which property value should be used within the process group detection.
-
Select whether you want the rule to be a standalone rule.
This option is not recommended in containerized environments, as out-of-the-box detection should take care of everything. For details, see Standalone rules.
-
In the Process instance extraction section, select if specific properties should be used to extract single process instances (nodes).
-
Select Save changes.
Standalone rules
When to enable this option
Suppose you have a process group with multiple processes. Each process simultaneously performs the same function for different customers who are using your application at the same time. While each process instance has the same name, each instance runs off a unique customer-specific configuration about which Dynatrace doesn’t have any information. Dynatrace therefore aggregates all related processes into a single process group in order to facilitate monitoring.
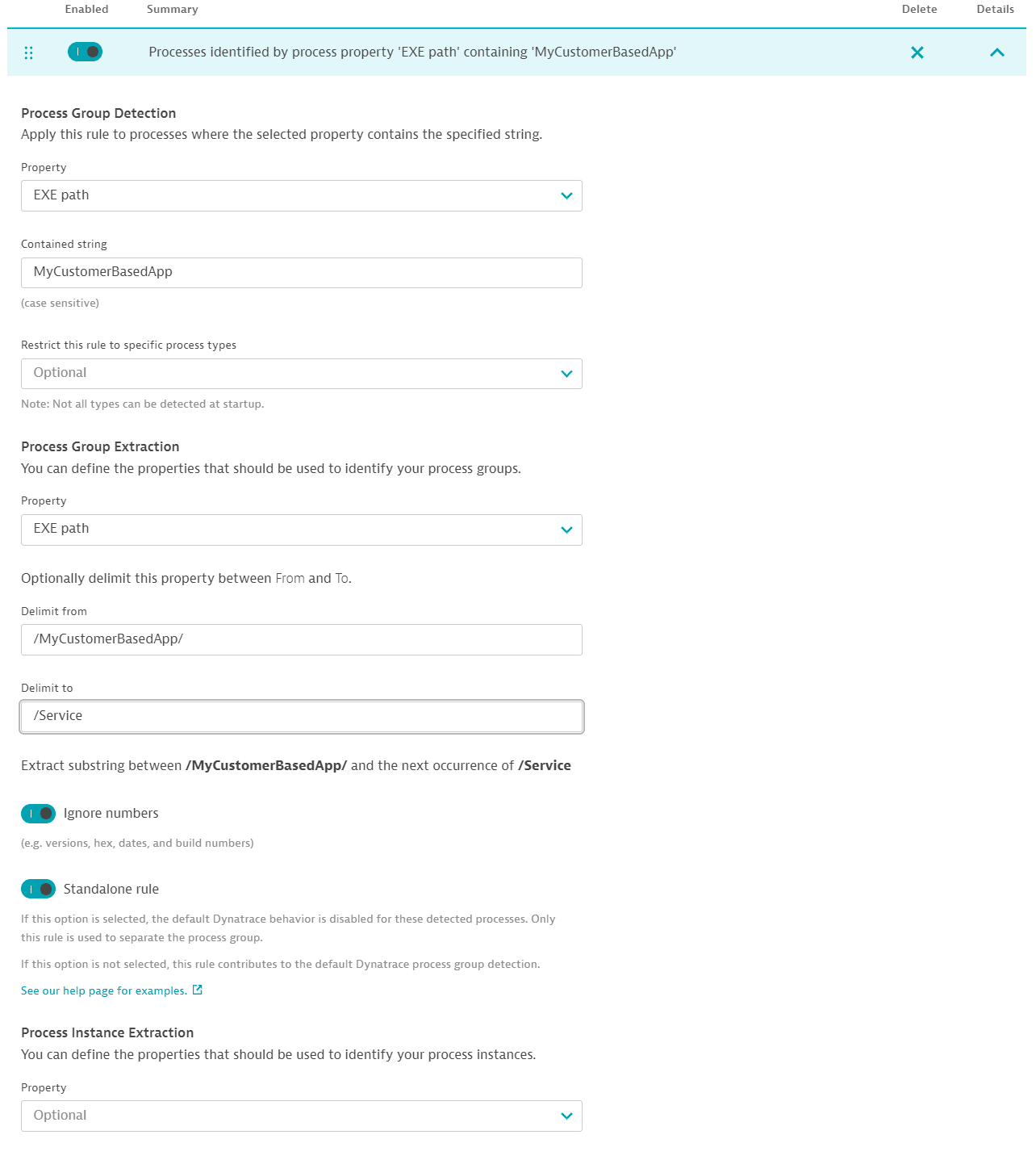
For cases where such grouping is inadequate, you have the option to define process-group detection rules that take into account customer-specific details. Such details can be drawn from your unique deployment scheme. If you have a directory structure that includes a customer ID (for example, /opt/MyCustomerBasedApp/<CustomerId>/Service/MyService), and the directory structure is the same across all your hosts, you can create a customer-specific process-group detection rule that works across all process instances.
Example:
You can create a rule that applies to processes with executable paths containing the phrase MyCustomerBasedApp. For processes that match this requirement, the string between /MyCustomerBasedApp/ and /Service in the Executable path is extracted and used to uniquely identify each process instance.
When to disable this option
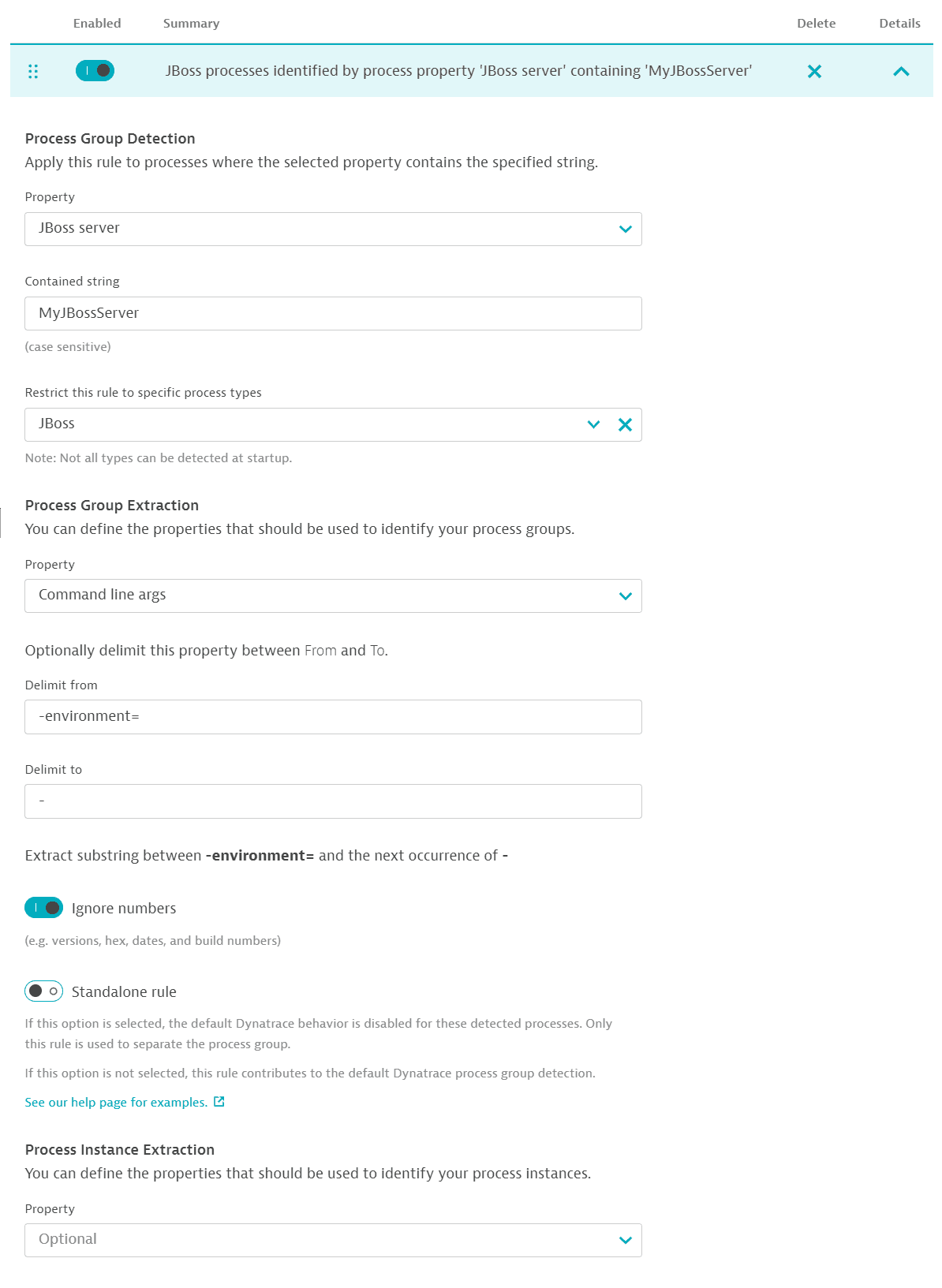
You can disable the Standalone rules option when, within the same environment, you want to differentiate between separate entities (for example, production vs. testing). In this case, you may want to use the default detection by Dynatrace, but enhance it with your own knowledge of the deployment setup.
You have the option to define a second property that identifies specific process instances (or cluster nodes) within a process group. This is useful if your process group setup has specific names per instance. If you're not sure, leave the field empty. The default setting is one node per host.
Example:
-
If none of the above process group detection options works, you can use the environment variable DT_CLUSTER_ID to group all processes that have the same value for this variable. All processes found in a monitoring environment that share the same cluster ID are treated as members of the same process group, and are separated only by the hosts they run on (for example, clusters of Apache web servers that belong together and host the same site). Make sure you set the DT_CLUSTER_ID variable only on a process-by-process basis, not system wide! If you set this variable system-wide, all processes may be grouped into a single process group for monitoring. This is undesirable and unsupported.
-
To identify nodes within a process cluster that run on the same host, use the DT_NODE_ID environment variable. This tells Dynatrace which processes should be taken as separate process group instances.
Declarative process grouping
Dynatrace automatically monitors process groups that are of known technology types or that consume significant resources. With declarative process grouping, you can automatically monitor additional technologies by overriding the default behavior and customizing the grouping of processes into process groups (PGs) and process group instances (PGIs). For more details, refer to Declarative process grouping.
Easy configuration with Settings API
Using the Settings API, you can easily
- Change the definition of your process groups
- Set up a simple or an advanced detection rule
- Configure a declarative process group detection
To use the Settings API
-
Create an API token and enable the Write settings (
settings.write) permission. -
Use the Get a schema endpoint to learn the JSON format required to post your configuration.
Example JSON payload for a simple detection rule
-
SchemaID:
builtin:process-group.simple-detection-rule[{"schemaId": "builtin:process-group.simple-detection-rule""scope": "environment""value": {"enabled": true,"ruleType": "env","groupIdentifier": "MY_PG_NAME","instanceIdentifier": "MY_INSTANCE_NAME","processType": "PROCESS_TYPE_APACHE_HTTPD"}}]
Example JSON payload for an advanced detection rule
-
SchemaID:
builtin:process-group.advanced-detection-rule[{"schemaId": "builtin:process-group.advanced-detection-rule""scope": "environment""value": {"enabled": true,"processDetection": {"property": "JBOSS_SERVER_NAME","containedString": "MyJBossServer","restrictToProcessType": "PROCESS_TYPE_JBOSS"},"groupExtraction": {"property": "COMMAND_LINE_ARGS","delimiter": {"from": "-environment=","to": "-","removeIds": true},"standaloneRule": false},"instanceExtraction": {}}}]
Example JSON payload for a declarative process group configuration
-
SchemaID:
builtin:declarativegrouping[{"schemaId": "builtin:declarativegrouping""scope": "environment""value": {"name": "keepalived","detection": [{"id": "keepalived","processGroupName": "keepalived","rules": [{"property": "executable","condition": "$eq(keepalived)"},{"property": "executablePath","condition": "$prefix(/usr/sbin/keepalived)"},{"property": "commandLine","condition": "$eq(-d)"}]}]}}]
-
-
Use the Post an object endpoint to send your configuration.
Add your configuration to Extensions 2.0
You can also attach your current configuration to your Extensions 2.0 extension so that your custom extension comes with predefined process grouping rules. Add your definition to the Extension YAML file as in this example:
---name: custom:my-extensionversion: 1.0.0minDynatraceVersion: "1.218"author:name: Joe Doeprocesses:- name: keepaliveddetection:- id: ext.keepalivedprocessGroupName: keepalivedrules:- property: executablecondition: "$eq(keepalived)"- property: executablePathcondition: "$prefix(/usr/sbin/keepalived)"- property: commandLinecondition: "$eq(-d)"