Problems app
- Latest Dynatrace
- App
- 15-min read
Quickly triaging, investigating, and remediating incoming incidents is the core challenge for operations teams.  Problems supports them by automatically analyzing complex incidents, collecting all the context, and presenting the root cause and impact within a consistent view.
Problems supports them by automatically analyzing complex incidents, collecting all the context, and presenting the root cause and impact within a consistent view.
Problems, backed by data from Grail and Dynatrace Intelligence analysis, helps operational and site reliability teams reduce the mean time to repair (MTTR) by presenting every aspect of the incident.
Prereqisites
Permissions
The following table describes the required permissions.
Installation
Make sure the app is installed in your environment.
Get started
Aim and context
This page shows you how to use Problems to triage detected problems and investigate their root cause and impact.
Target audience
This page is written for:
- Operations engineers
- Pipeline engineers
- Systems engineers
- Site reliability engineers (SREs)
- Build automation engineers
Summary
Problems streamlines triage, analysis, and remediation of active incidents by reducing the MTTR. It allows you to focus on AI-detected problems and quickly navigate to their root cause.
- The data provided by Grail and DQL makes it possible to slice and dice all problem-related information for huge amounts of problems and events.
- Integration with context-specific Dynatrace apps allows you to analyze problems without the need to switch the context.
Investigate and remediate active problems
Set focus and triage
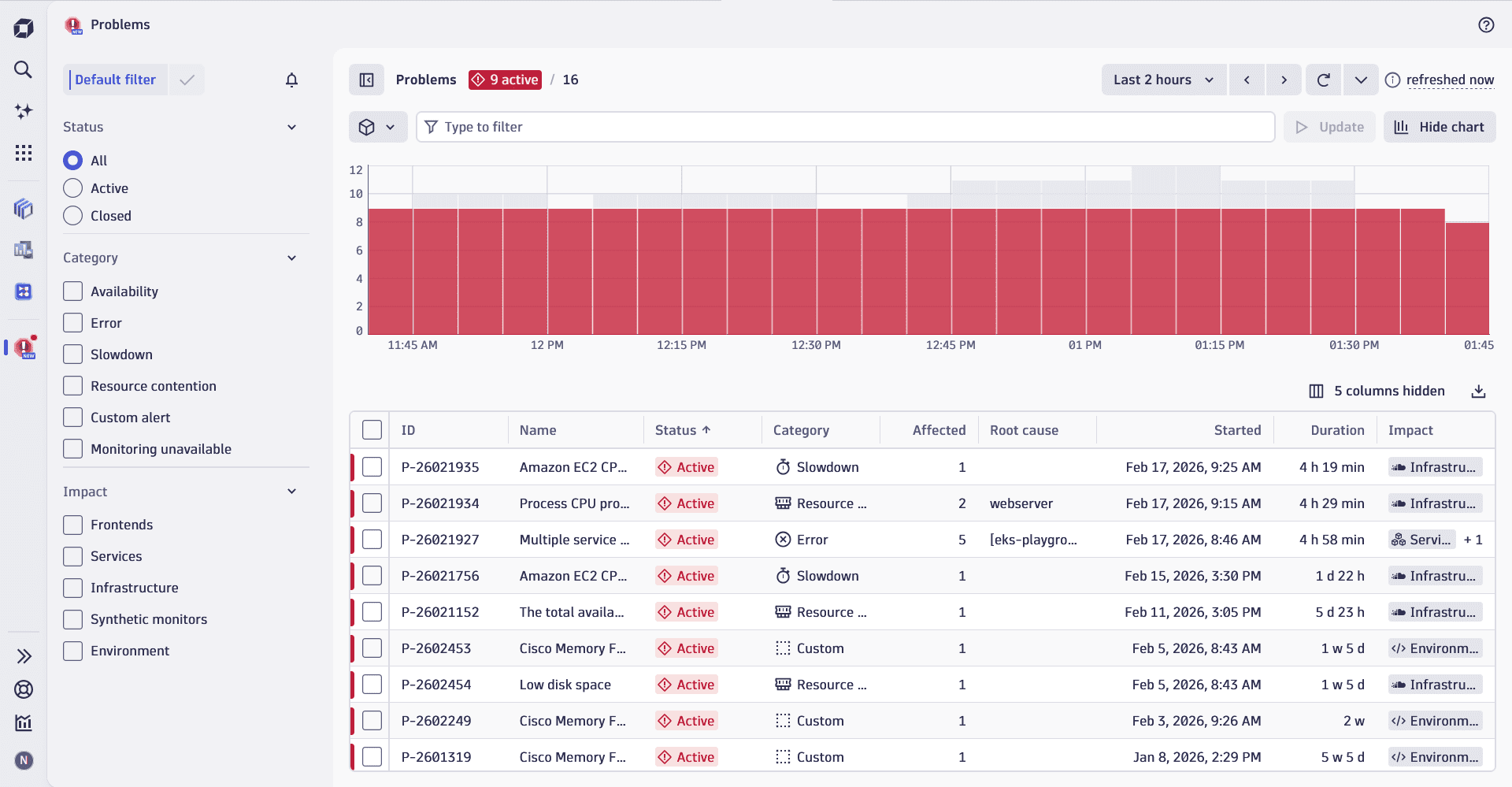
By default, Problems shows:
- A feed of all problems in the last 2 hours. To help operation teams spot open problems regardless of which filter is set, open problems remain on top of the feed no matter how long they are open.
- A problem chart at the top visualizes any abnormality with a high number of problems in the past. Select a peak on the chart to drill into it and investigate further.
Filtering
To focus on your domain and triage problems that affect it, set filters. The three most common filters—Status, Category, and Impact—have selectable settings to the left of the table for quick access. Your selections there automatically add the corresponding filters to the filter bar above the table.
To set other filters, enter them directly in the filter bar.
- Status—Can be
ActiveorClosed.- If this is not set, all problems (active or closed) are listed.
- If you select a status in the controls on the left, the corresponding filter is also displayed in the filter bar.
- Category—Indicates the nature of the incident, such as slowdowns, errors, resource-related issues, or availability incidents.
- If you select one or more categories in the controls on the left, the corresponding filters are also displayed in the filter bar.
- Impact—Indicates the type of the impacted area, such as frontends, services, infrastructure, or environments.
- If you select one or more impact areas in the controls on the left, the corresponding filters are also displayed in the filter bar.
Problems are also classified by a severity level (Critical, Major, Minor, Warning, and Informational). You can filter by severity in the filter bar or select it in the left sidebar. To understand how Dynatrace assigns and manages severity levels, see Standardized event severity concept.
Filtering with the filter bar allows you to focus your feed on problems based on multiple criteria, such as status, number of affected entities, root cause entity, and more. Place your cursor in the input field to see all the available options. By default, filtering criteria are combined by the AND logic. For each criterion, Dynatrace Intelligence provides a list of suggested values, based on your problem feed.
For example, to see problems that are raised due to an increase of JavaScript errors and that persist for longer than 1 hour, use the following filter criteria:
Status=ACTIVEDuration>1hCategory=ErrorName=JavaScript error rate increase
By using the filter bar, you can also narrow your feed to focus on specific impact areas (such as Frontend, Service, or Infrastructure) with the Impact parameter, or use text search to find problems that contain a specific string. To use search, you can:
- Input any text in the filter bar and select Search in all data.
- Enter
* ~ <your_text>in the filter bar and select Update.
The following fields in the problem record are considered for the text search:
event.idevent.nameevent.descriptionevent.statusdisplay_idlabels.alerting_profileentity_tagsroot_cause_entity_name
The problem filter bar supports Boolean logic filters. This allows you to combine AND and OR criteria and create complex filters using parentheses to group Boolean terms. You can see a Boolean logic filter statement within Problems app in the example below.
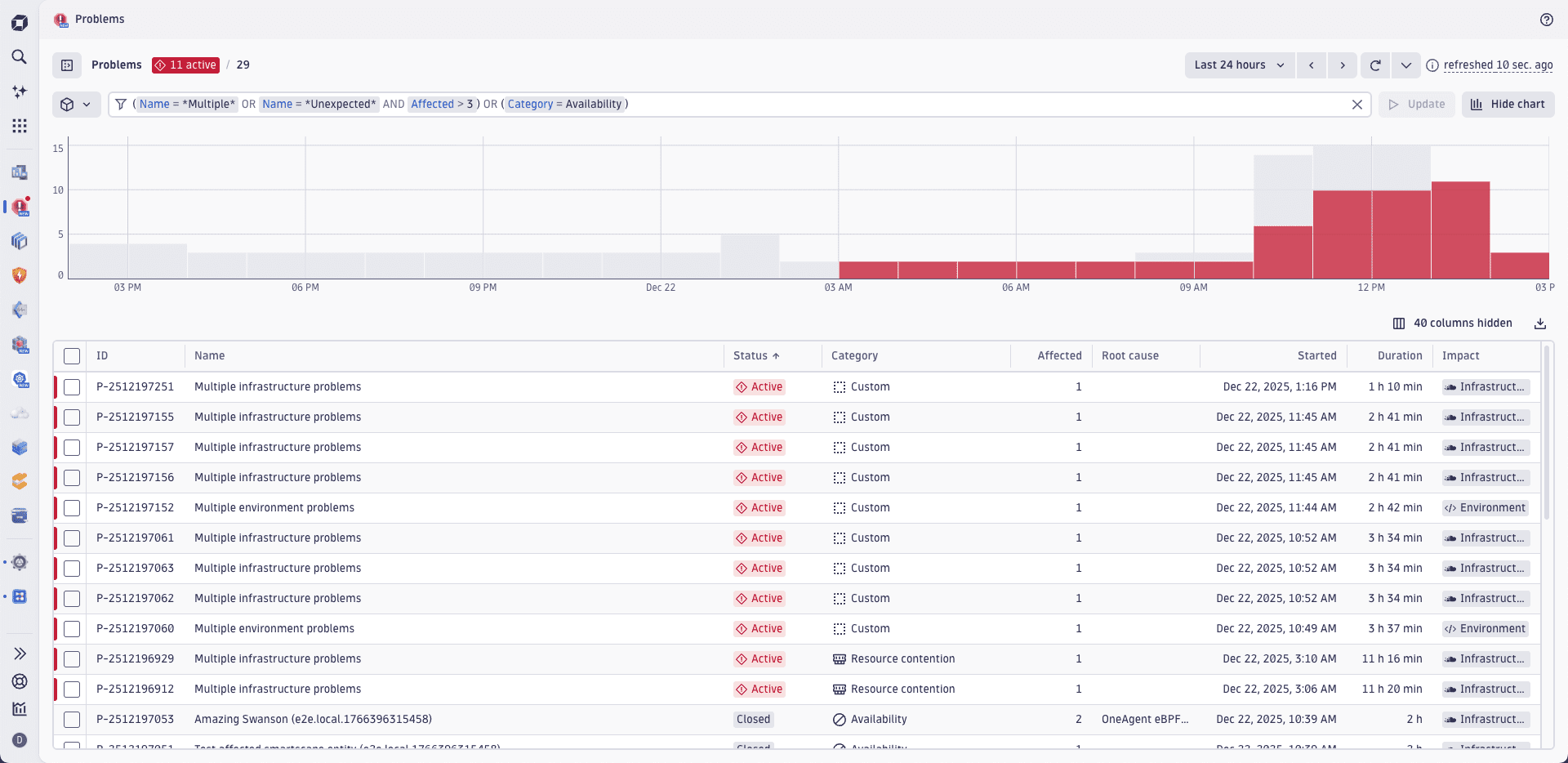
Leverage predefined Team Segments to increase operational productivity
Segments are predefined filters used for quickly filtering the data to include only the relevant entries. In the context of Problems, you or your team can utilize a predefined set of team-specific segments to filter your problem tables instead of having to create your own problem filters.
The following example shows how to use segments to filter problems connected to easyTravel.
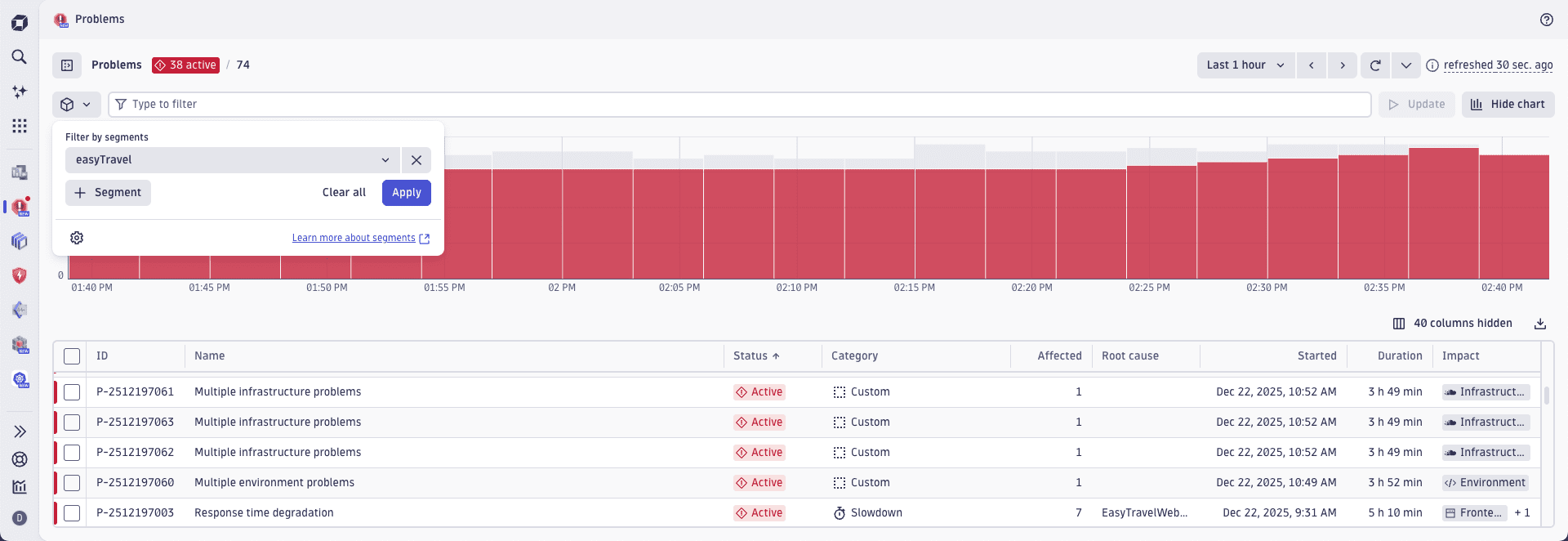
In addition, using segments in Problems allows you to:
- Create sets of filters that can be reused by you and shared to the whole team.
- Save time on recreating filters applied during the previous sessions.
- Increase productivity by quickly filtering relevant problems.
- Quickly check the status of your service by creating and applying service-specific segments.
Since problems are stored as events in Grail, segments created for filtering problems must define an event filter. For example, if you want to filter problems that were raised in a specific cloud region, you can create a segment with the following event filter:
cloud.region = "us-east-1c" AND event.kind = "DAVIS_PROBLEM"
Screenshot example of defining a segment for Problems filtering
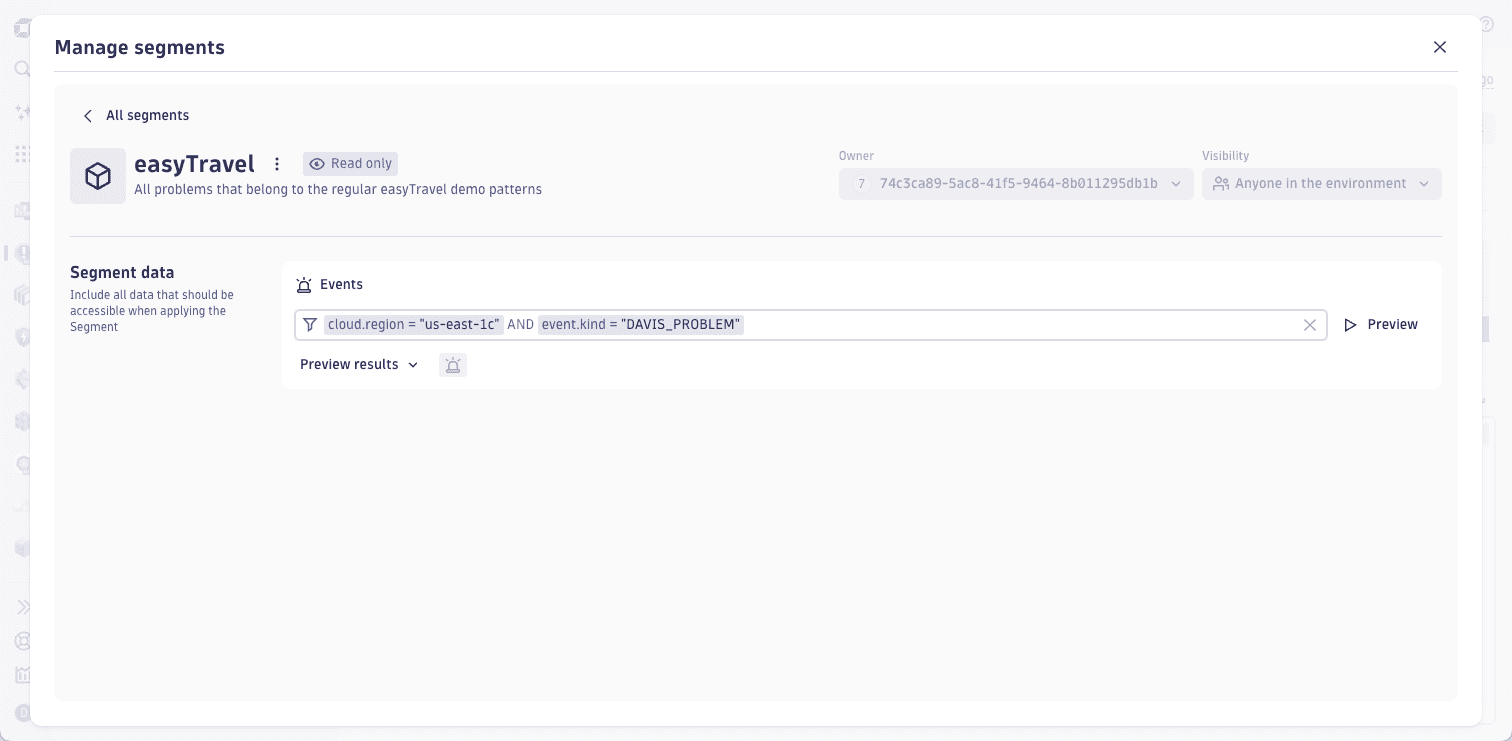
Segment filters are directly applied to the problem Grail records. Consequently, no entity filters are applied to the problem unless the entity ID is chosen as a primary field of the filtered problem.
For more information on segments and how they work, see Segments  .
.
Activate auto refresh
To make sure you always catch incoming problems, use the refresh settings 
 in the upper-right corner of Problems.
in the upper-right corner of Problems.
- To automatically refresh the problem feed, select and choose a refresh rate (or select
Offto turn off automatic refresh) - To manually refresh the problem feed at any time, regardless of the automatic refresh setting, select
Investigate and compare problems
To see the details of a problem
- In the table, select the problem ID in the ID column.
- Review the details page.
The problems details page provides all available details about the problem, highlighting the root cause entity with a red mark, to guide your attention to the right things. The example below shows details of a problem with user action degradation—including the root cause entity (easyTravelBusiness service) and a chart of abnormal response time of that service.
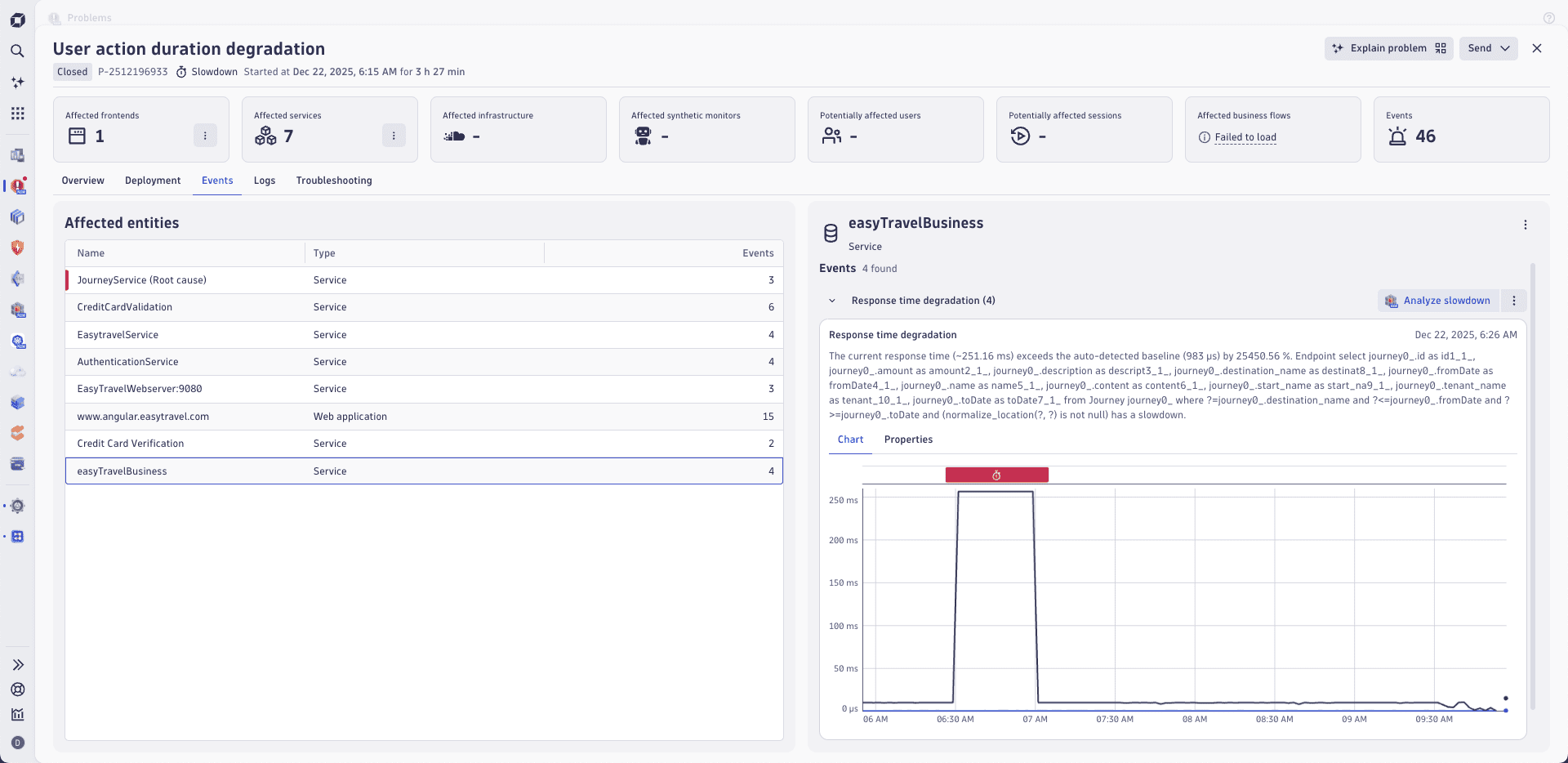
All entities affected by the problem are listed in the Affected entities section, along with information about entity type and the number of events, detected during the analysis.
- As a suggestion for the starting point of the investigation, Dynatrace Intelligence marks the entity that it determined to be the root cause of the problem.
- To review details about an affected entity, select it in the table.
Compare multiple problems
If all the filters are applied and you still have multiple problems to investigate, you can select and compare the details of multiple problems.
-
In the table, use the checkboxes to select two or more problems.
-
Select Show details.
This preloads the details of all selected problems and adds controls to the upper-right corner of the problem details page so you can quickly switch between each selected problem.
Read event properties for additional information
Dynatrace receives events from multiple event sources, such as OneAgent, Synthetic, extensions, and ingestion APIs. Dynatrace accepts and understands various properties (also referred to as fields) of those events that provide additional information about the event.
Event sources can be customized to provide the information you need to analyze and remediate problems caused by the events. For example, linking the configuration that detected the event (dt.settings.schema_id and dt.settings.object_id) helps you to quickly adapt the threshold or baseline if such action is necessary.
Another example is adjusting the sensitivity of the custom alert that triggered the event by modifying the detector's configuration in the settings.
Since available event properties depend on the event's source, events that are not generated by custom alerts don't contain links to relevant event settings. If you want an event to link to a settings object, you can do so by attaching a dt.settings.object_id property to events ingested via API and/or extensions.
Problems displays all event properties for each collected event in a table and provides intent links, such as direct navigation to a custom alert's configuration, as shown below.
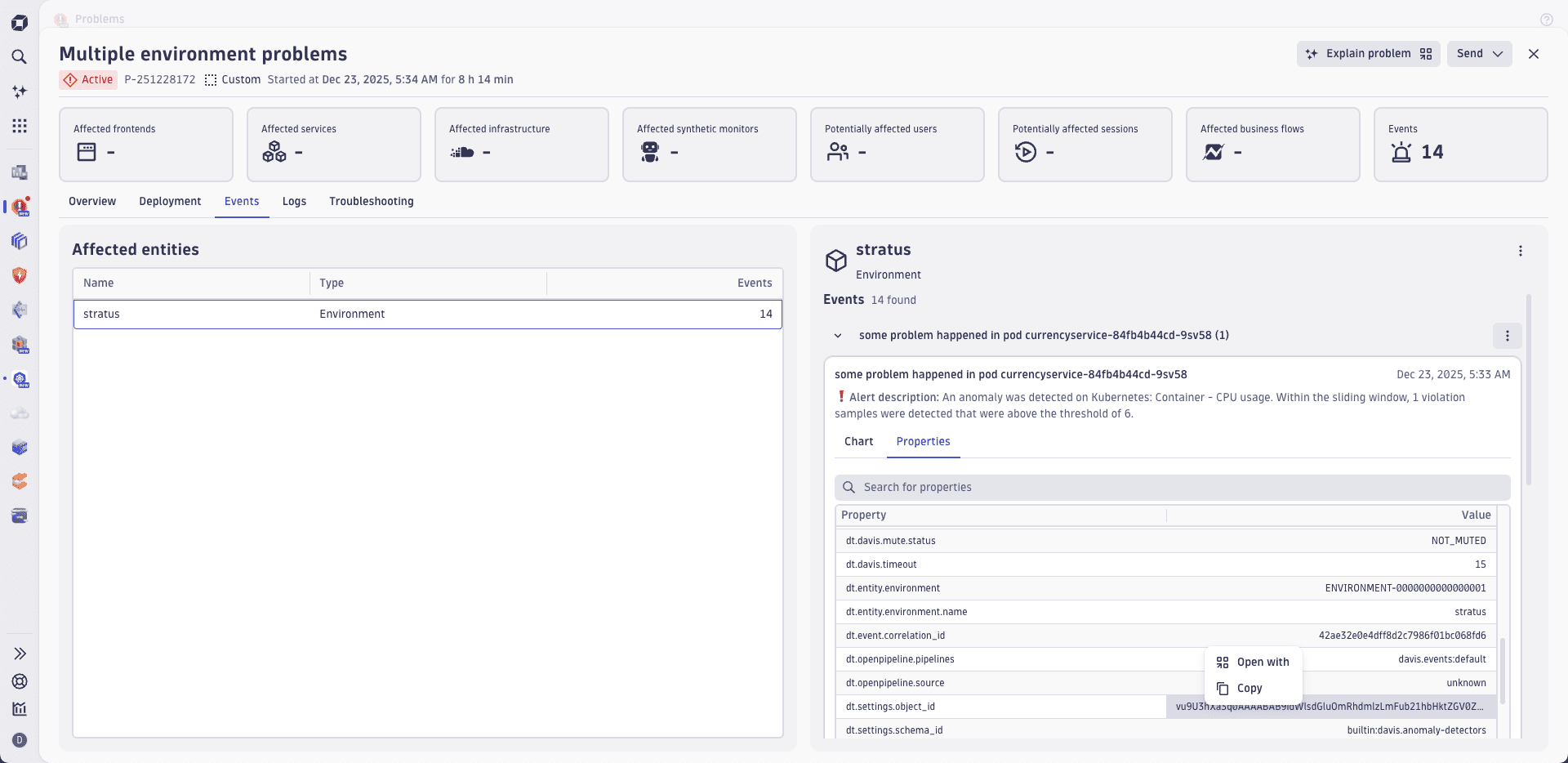
Examples of powerful event properties include:
- Event description (
event.description). The event description supports Markdown-formatted text, enabling you to include links to resources that can help to remediate the problem. - DQL query (
dt.query) allows you to rebuild the event's chart in a notebook or at a dashboard or to copy the raw value of a property. - Related entities (
dt.entity.*) allow you to directly navigate to entities through thedt.entity.*properties. - Link to a settings object (
dt.settings.object_id) and settings schema (dt.settings.schema_id).
To learn more about the semantics and syntax of event properties and how they can be used across Dynatrace, see Semantic Dictionary.
Analyze problems with your own tools by exporting CSV
For cases when your software tools create integration gaps preventing you from effective usage of Dynatrace data, we provide the ability to export problem feed data in the CSV format. You can later use this data in various tools, including spreadsheet programs, databases, and data analysis tools.
As illustrated below, you can export problem related-data from the problem feed table. You can also export it from Notebooks and Dashboards within all table visualizations.
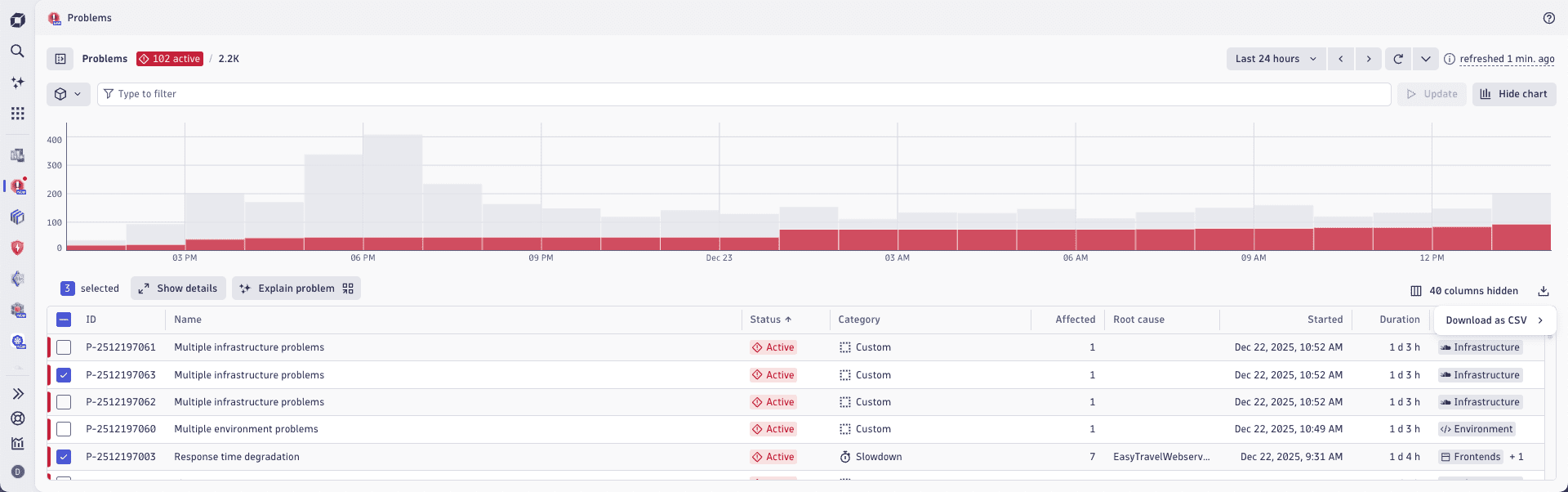
You can export all loaded problems (up to a limit of 1000) or use the multi-select feature to choose specific problems. Additionally, the filter bar above the table allows you to filter through larger subsets of problems. The Select all checkbox helps you to export all problems in the filtered set of entries.
Check the root cause without leaving your context
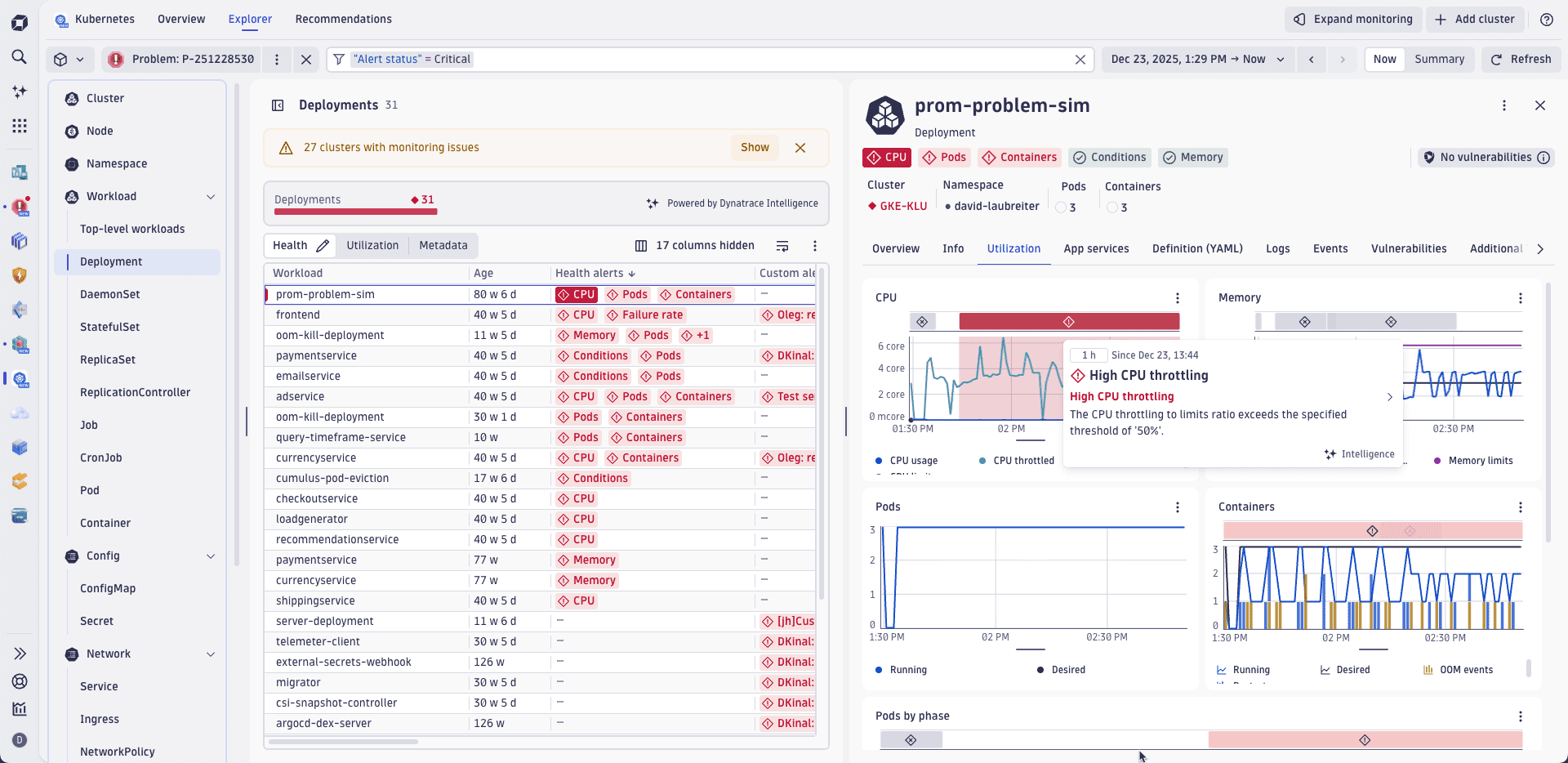
Depending on your team's responsibility, you might want to focus your attention on Kubernetes clusters, cloud resources, and workloads of critical services. To minimize context switching, Dynatrace offers consistent root cause information across multiple apps. No matter where your investigation starts, you don't have to switch to Problems to see the root cause.
In the example below, the Kubernetes app displays information about a problem affecting a workload.
Investigate all problem relevant logs
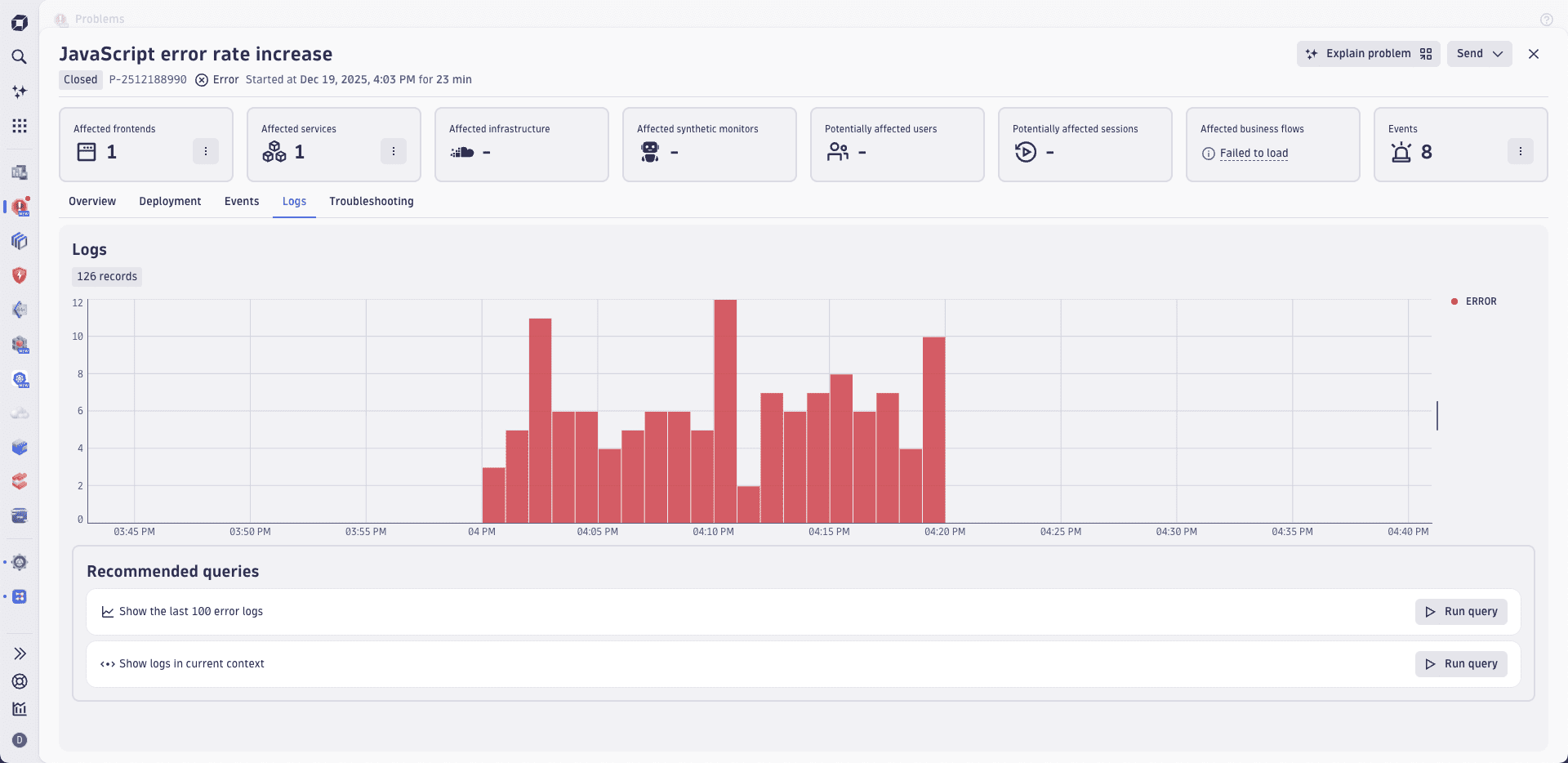
A problem analyzed by Dynatrace Intelligence highlights the root cause of an incident and shows all the incident-relevant log lines across multiple entities in the problem details.
To access the log lines that were collected during the incident, select the Logs tab. Additionally, you're able to see their log level across all entities affected by the problem, allowing you to save time on manual investigations and filtering logs of relevant entities separately.
The Logs tab also includes references to the affected entities and information about all related entities, such as parent hosts. To verify which entities are affected by the problem event, you can refer to all the event properties that start with the dt.entity. prefix.
See how Logs tab summarizes all problem-relevant logs in the image below.
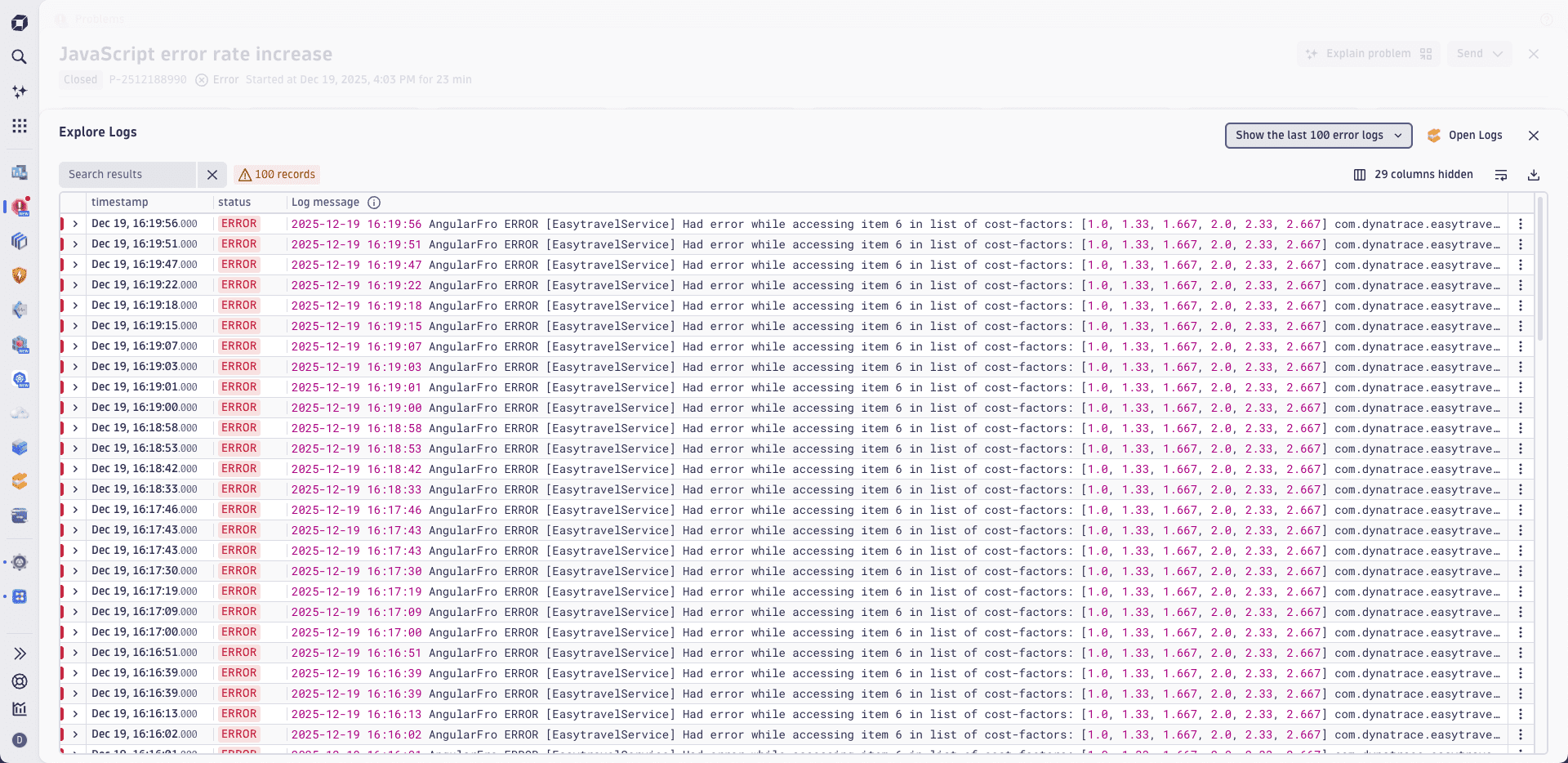
The image below illustrates the further sorting of the log lines with the help of a DQL query.
Visually notify and automate to speed up remediation
Problems features a global problem indicator that shows the number of active problems within the environment and is always visible in the Dock. When the Dock is collapsed, a red dot is displayed next to the app icon instead of a number.
To personalize the indicator and the number of the displayed active issues, select filters in Category and save the filter configuration by selecting the icon. The saved filter will automatically apply to the global problem indicator, reducing the number of problems counted for the user, as shown below. Selecting the Default filter button restores the last saved configuration.
While a problem filter is active, the indicator number will only show active problems from your chosen categories. The indicator updates on a one-minute schedule, which means that after the filter is updated, it can take some time for the indicator to adapt.
You can also set up email notifications for filtered problems using your email address by selecting the icon, as shown below:
The email notification is your personal setting, so you can enable it without the need for configuration permissions or the risk of impacting other users within the same environment.
The email notification is directly triggered within OpenPipeline, meaning only simple filters can be applied. Workflows that query Problems through DQL can use the complete feature set of Grail queries, such as joining tables.
If you need to send out customized email messages or have more complex automation and integration needs, you should apply a complete workflow along with the problem trigger.
Visualize affected deployments to gather additional insights
The Deployment perspective equips operations teams with deeper insight into the infrastructure and cloud resources impacted by large-scale incidents. The root cause analysis feature automatically collects and visualizes affected deployments and related resources.
The additional context provided by related resources allows you to:
- Quickly understand where an affected resource resides, for example, a specific cloud region or Kubernetes cluster.
- Gather additional insight for multicloud deployments by showing an app's deployment across clouds, regions, and technology boundaries.
Deployment view uses a diagram similar to a Unified Modeling Language (UML) deployment diagram and follows a top-down approach, starting with the largest container element at the top and becoming more detailed as you drill down. The deployment structure is visualized as collapsible cards with horizontally overlapping elements, for example, services running in multiple regions. In this case, cards representing such services are duplicated and shown in multiple deployment stacks.
The deployment containing the root cause is automatically expanded and tagged with a red root cause badge, while all other deployments are collapsed by default. The deployment hierarchy is focused on a maximum of 5 levels, starting with the hierarchy leaf nodes at the bottom of the diagram upwards, seen in the example below:
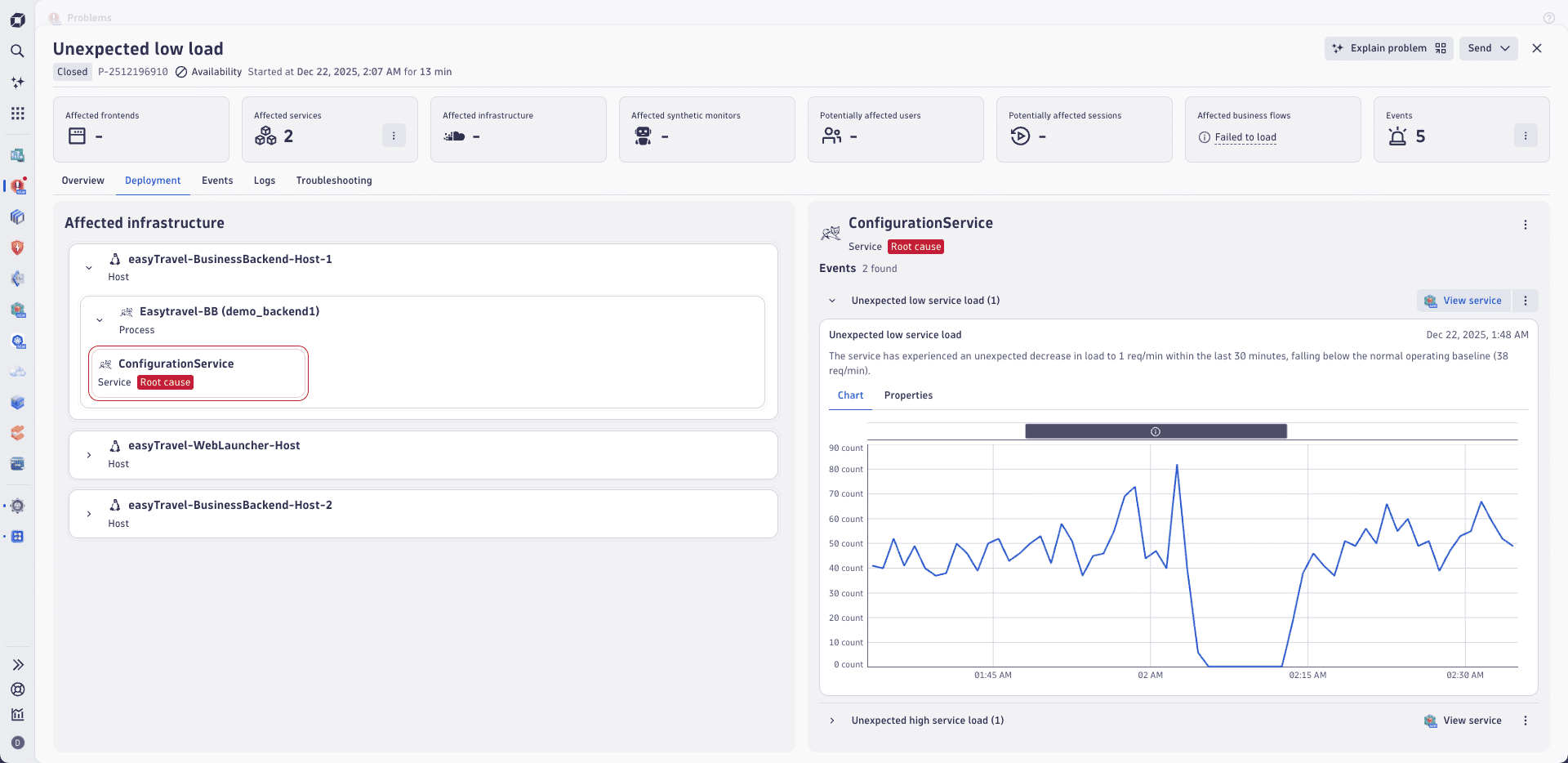
Interactivity is a crucial feature of the deployment view. On the right side, you can click on any element to visualize findings, such as events related to the problem, along with a direct link to the selected entity. This structured approach allows you and your operations team to reduce the time needed to respond to incidents by navigating a familiar visual representation.
Not all incident-relevant related elements may show information on the right. Some elements, like the cloud region, are displayed for better context but may not necessarily show problem-relevant events.
Define custom problem fields
Dynatrace Intelligence causal AI root-cause detection identifies and reports issues triggered by one or more events within a Dynatrace environment, and saves the results in the form of a problem record in Grail.
The problem record includes an array of event IDs (dt.davis.event_ids) that represents all the events collected and merged during the root-cause analysis. Event-related Problems table fields such as category, name, description, status, start, and end are derived from these events, which allows you to efficiently filter and sort all incoming problem records.
By default, Dynatrace propagates a set of built-in problem fields along with record-level permission fields, such as dt.host_group.id, k8s.namespace.name, k8s.cluster.name, onto problems. For the full list of built-in problem fields, see Record level permissions in Grail.
Other built-in and custom event fields are not automatically propagated to avoid an excessive number of problem records.
In Davis events, permission policies based on Grail record-level permissions work as expected because the fields contain single values. However, when multiple events are aggregated into a problem, the values of the same field are combined into an array. Due to the current implementation of Grail record-level permission filters, only dt.security_context supports filtering array values. Other permission fields can't be used with array-based filters in permission policies.
This behavior differs from the DQL filter functionality, where array filters on array fields are fully supported. While this limitation may impact the flexibility of permission filters, it's important to consider when you're managing permission policies.
- Dynatrace doesn't allow you to define problem field names that repeat existing Semantic Dictionary event field names.
- You can only define problem fields for source fields with values of type
string. Fields that contain values of other types aren't supported.
Custom problem fields modification
To view or change the fields automatically propagated from events to problems, go to ![]() Settings > Dynatrace Intelligence > Root cause analysis > Problem fields. By modifying these problem fields, you can:
Settings > Dynatrace Intelligence > Root cause analysis > Problem fields. By modifying these problem fields, you can:
- Subscribe to custom record fields to be automatically propagated from all single events to any detected problem.
- Rename existing problem fields.
- Remove problem fields.
Renaming existing problem fields and removing problem fields changes current and future Grail problem records and may break your DQL queries.
To learn more about custom problem fields use cases, see Dynatrace Intelligence Problems use cases.
Create a troubleshooting guide
Problems allows you to create troubleshooting guides using  Dashboards or
Dashboards or  Notebooks to document your investigation and the steps taken to resolve the problem. The guide is based on a predefined template and contains two types of sections:
Notebooks to document your investigation and the steps taken to resolve the problem. The guide is based on a predefined template and contains two types of sections:
- Sections with information extracted directly from the problem.
- Template sections (such as
Initial Response & Detection,Troubleshooting, andRemediation steps) that you can edit to describe the process and steps followed to resolve the problem.
To create a troubleshooting guide
- Go to Problems and open the problem you need to resolve.
- On the problem details page, select Troubleshooting.
- Select New.
- Select Notebooks to create a new document in Notebooks.
- Select Dashboards to create a new document in Dashboards.
- Select Notebooks to create a new document in
- Follow the instructions in the template to document the details for your troubleshooting guide.
If you share a troubleshooting guide with all users in your environment, and you have enabled document suggestions based on vector similarity, Dynatrace Intelligence agentic and generative AI will index your document and proactively suggest it to your team to help them remediate similar problems faster. To learn more about Dynatrace Intelligence agentic and generative AI document suggestions, see Find relevant documents with Dynatrace Intelligence agentic and generative AI.
The ability to create and share troubleshooting guides allows DevOps teams to:
- Share and spread their domain knowledge about specific business logic, software implementation, and infrastructure.
- Enrich the Dynatrace AI in their environment with shared knowledge for a more streamlined, tailored experience during problem investigation and remediation.
- Enrich the Dynatrace AI in their environment.
Resolve the cases of missing events
Dynatrace offers a wide range of tools suited for your needs, such as configuring user group permissions, Dynatrace Intelligence alerting rules, or OpenPipeline ingestion rules. Due to the rich customization options, however, there are cases that might lead to events not being visible in Problems and differences in the number of affected entities in the available tabs. The most common reasons for events "missing" from Problems are:
- Difference in bucket retention period: you can configure your bucket retention period for the monitored data to last longer, so that the events related to the problem will be visible regardless of how long the problem has been in the open state. To learn more about configuring bucket retention period for monitored data, see Retain trace data for long periods.
- Missing permissions necessary for viewing the event: check with your Dynatrace support group and ensure that you have necessary permissions. Ask the administrator to adjust permissions, so the event becomes visible to you.
- OpenPipeline ingestion rules dropping records: you can adjust OpenPipeline ingestion rules to prevent it from dropping any records or broaden the rules to keep records that might be connected to the alerted problem. To learn more about configuring OpenPipeline ingestion rules, see Log processing with OpenPipeline.
Streamline problem resolution with problems-specific drill-down options
Problems provides drill-down options that are designed to guide you toward the most relevant actions for resolving detected problems and help you streamline problem resolution.
Drill-down options available to you are displayed within the problem details view and depend on the type of the affected entity (such as service, Kubernetes workload, host, or AWS availability zone).
Some of the available drill-down options are:
- Analyze failures: Perform a focused failure analysis to identify the root cause of failure rates, error patterns, or performance issues.
- View related logs: Investigate relevant log entries directly within Problems.
- View failed traces: Analyze failed traces in
 Distributed Tracing to understand the root cause of failures.
Distributed Tracing to understand the root cause of failures. - View
app: Navigate to the associated app's details page. The exact name is specific to the affected entity (such as View service, View Kubernetes workload, or View host).
To access drill-down options
- In Dynatrace, go to Problems.
- Select the problem you want to investigate from the Problems overview. This opens a problem details page.
- Optional On the left side of the problem details page, select the affected entity or infrastructure you want to investigate further. Usually, when you open the problem details page, the affected entity is pre-selected for you.
- From the affected entity details on the right, select the preferred option for further investigation.
- Select > View related logs to continue the investigation without leaving Problems.
- Select > View failed traces to continue the investigation in the Distributed Tracing.
- Select > View
appto continue the investigation in one of the available Dynatrace apps. - Select > Open with to see all available investigation options.
- Select > View related logs to continue the investigation without leaving
Drill-down options provide you with seamless navigation between Problems and other Dynatrace apps to ensure focus and continuity in problem resolution.
Review problem overview
The Overview is a concise, executive summary of a detected problem.
To view a problem overview
-
Go to
Problems and open the problem you need to resolve. -
On the problem details page, select Overview.
Example:
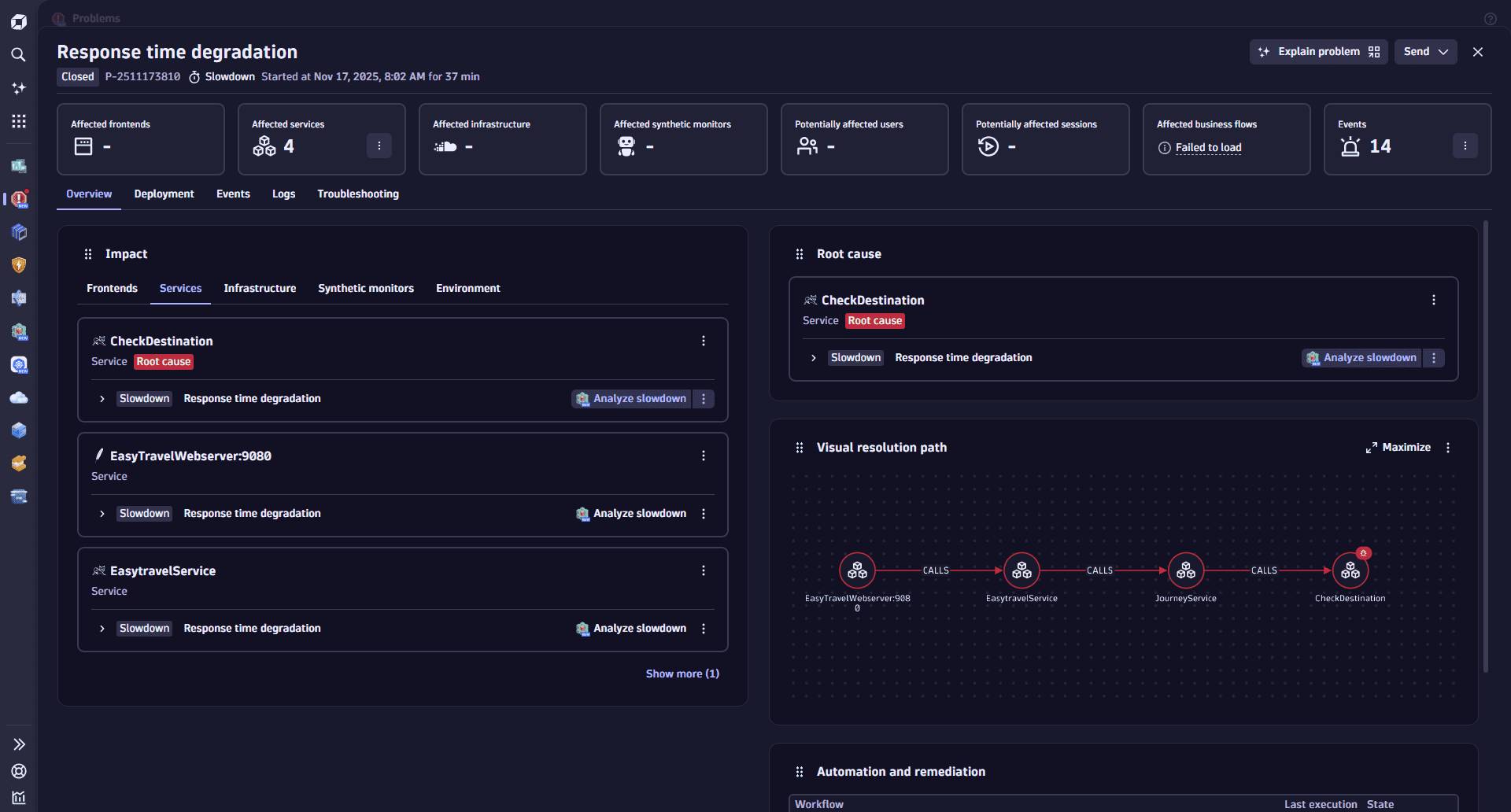 Example problem details Overview tab
Example problem details Overview tab
The Overview has four sections:
| Section | Description |
|---|---|
Displays all impacted Smartscape entities (for example, services, processes, and hosts) along with brief issue details for each entity. | |
Focuses on the root cause of the issue, including detailed information about the affected deployment stack. | |
Graphically illustrates the relationships between frontends, services, and backends involved in the issue. | |
Lists all automation workflows triggered by the problem, such as notifications, remediations, and external integrations. |
You can move these sections around to personalize your view of the Overview.
- In the header of the section you want to move, select and drag the section.
- Drop the section where you want it to appear in the layout.
These changes are saved per user. Your layout changes don't affect how others see the overview.
Impact
The Impact section displays all impacted Smartscape entities (for example, services, processes, and hosts) along with brief issue details for each entity.
The Impact section is categorized by:
- Frontends
- Services
- Infrastructure
- Synthetic monitoring
- Environment
Root cause
The Root cause section focuses on the root cause of the issue, including detailed information about the affected deployment stack. This may include:
- The process and host where the root-cause service is running.
- The Kubernetes workload serving the impacted service.
To ensure consistency, the root-cause entity is also listed in the Impact table.
Visual resolution path
The Visual resolution path section graphically illustrates the relationships between frontends, services, and backends involved in the issue.
- Each node represents a Smartscape entity (frontend, service, or backend) where a health issue was detected.
- Gray nodes indicate related entities used in the analysis but not directly impacted.
This graph helps explain how Dynatrace AI identified the root-cause backend service.
To maximize your view of the graph, select Maximize.
Automation and remediation
The Automation and remediation section lists all automation workflows triggered by the problem. These workflows may include:
- Alert notifications sent to response teams.
- Remediation flows and runbooks for auto-remediation.
- External AI agent triggers, such as cloud platform SRE agents, to gather further insights or resolve issues within cloud vendor infrastructure.
The table provides key details for each workflow, including:
- The last trigger time (as workflows may run multiple times during problem updates).
- The execution state (for example, success or failure).
Workflow execution details are based on standard workflow execution events, which can also be queried using DQL in Notebooks and Dashboards.
- Only users with system event read permissions can view workflow executions. Without these permissions, the table is empty and a message indicates the missing access.
- Workflows not shared with your user are listed but shown in gray without direct links, indicating restricted access.
Comment and annotate problems in Dynatrace
A problem annotation is a type of Davis event that can be linked with one or multiple detected problems. You can annotate Dynatrace-detected problems with text comments and links, and use this functionality to:
- Attach an external ticket link for reference.
- Annotate the problem with comments from people directly working on the issue. Annotating problems with comments allows you to:
- Exchange information for better team coordination and avoiding duplicate tasks.
- Synchronize user comments with external ticketing systems.
- Annotate the problem with additional insights from an automation workflow or an external AI agent.
Comments from  Problems Classic and Problems aren't compatible. This means that:
Problems Classic and Problems aren't compatible. This means that:
- Comments added via Problems Classic or Dynatrace Classic API are only visible in Problems Classic.
- Comments added via Problems, v2 API events, or a
 Workflows action are only visible in Problems.
Workflows action are only visible in Problems.
Annotation-specific permissions
To use and ingest annotations, in addition to standard Problems permissions, you need the event ingest permission (ALLOW storage:events:write). You also need the same permission to comment on the problem using the problem details UI.
Annotation events
Annotation events act the same as the Davis info events: they don't trigger alerts or create new problems, and they can be used to transport additional information in the form of Markdown text and optional URL linking.
Since annotation events are stored in Grail, they're licensed according to the event rate card in the same way as Events powered by Grail.
Annotation events metadata is standardized through the Dynatrace Semantic Dictionary and consists of the following fields:
| Field | Description |
|---|---|
event.kind |
|
event.type |
|
event.start | A single point of time when the annotation was added. |
annotation.source | A source of the annotation event, such as an author or an external system. |
annotation.id | Annotation's unique ID; can be used for overriding. |
annotation.problem_ids | A reference ID for a problem, or problems, that contain an annotated event. The field also accepts values of type |
annotation.url | Optional A URL link to an external source, such as a Jira ticket. |
event.description | Annotation text content, including comments. |
event.name | The name of the event, used as a title for the |
As a type of Davis event stored in Grail, annotation events have traits similar to Grail events, such as:
- Immutability, which means that once the events are ingested, they can't be modified. Similarly, you can't modify history of the ingested events.
- While you can't modify annotation events directly, you can use
annotation.idfield to override existing annotation events if you want to update or correct errors in the UI. - You can't overwrite or edit the history of the ingested annotations. However, you can access and monitor updates in Grail via DQL.
- While you can't modify annotation events directly, you can use
- Flexible query and visualization options.
- Same Grail storage permission policy for ingest and query.
- Same storage management applicable Grail records, which mean that you can modify retention, create buckets, and set permissions.
- Same ingest possibilities as other Grail records.
- Same OpenPipeline processing possibilities, which means you can enrich, drop, or mask your annotations.
Annotate the problem
To access problem annotation
- In the table, select the problem ID in the ID column.
- On the problem details page, go to Comments and insights.
To annotate the problem, you can
- Provide a text comment directly in Comments and insights, in the Add your comment field.
- Ingest and create annotations via SDK, REST API, or Dynatrace workflows.
You can add a link to the annotation via the annotation.url field. This allows you, for example, to record a link to an external ticketing system. Meanwhile, the event.name field is used as a ticket link title as shown below:
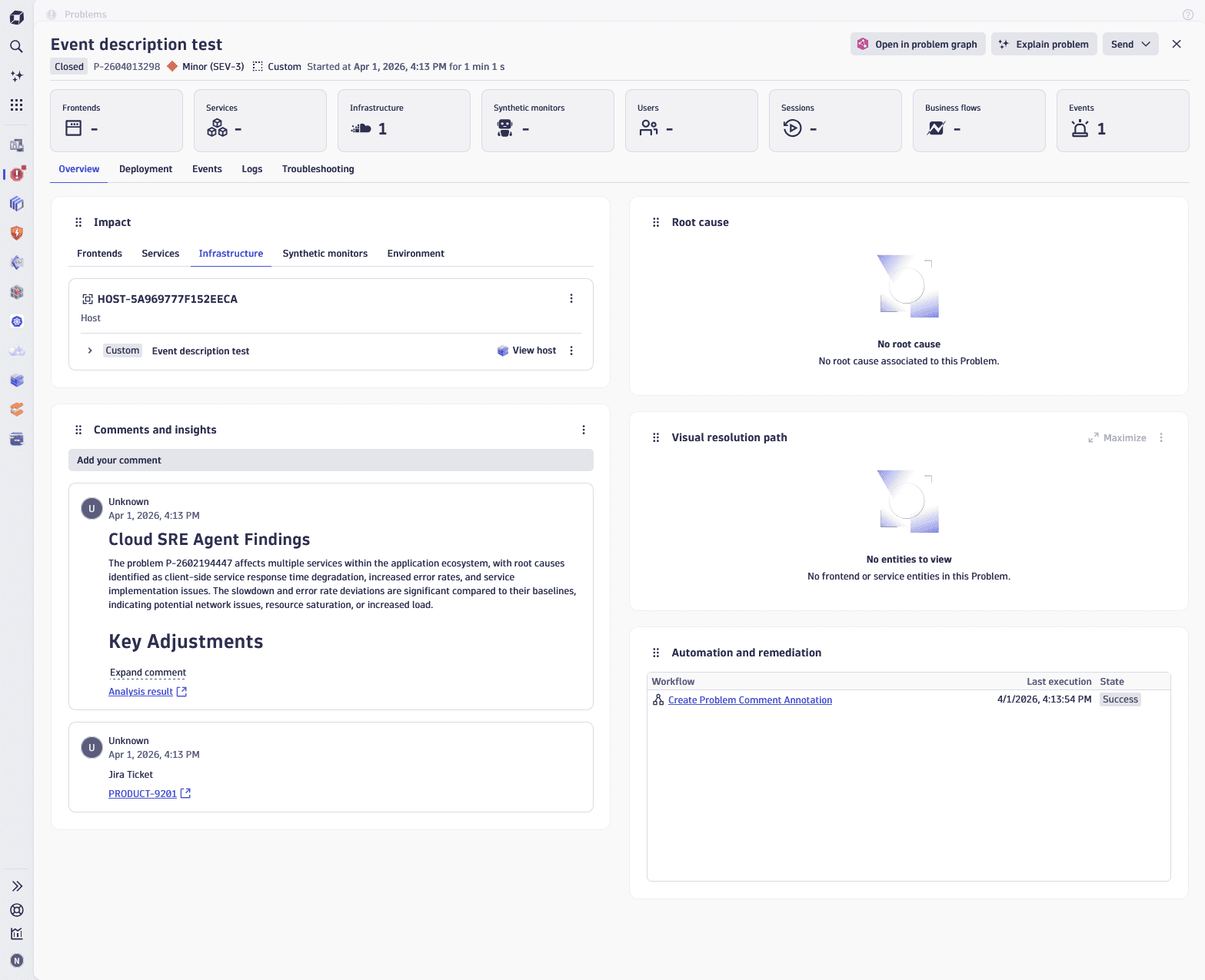
To add a ticket link, you need to configure a workflow, as shown in example event payload below:
// Create a ticket link as an annotation event.const resultTicket = await eventsClient.createEvent({body: {eventType: 'CUSTOM_ANNOTATION',title: 'PRODUCT-9201',startTime: nowInUTC,endTime: nowInUTC,properties: {'annotation.source': 'JIRA','annotation.id': '' + Math.random(),'annotation.url': 'https://dt-rnd.atlassian.net/browse/PRODUCT-9201','annotation.problem_ids': problem_id,'dt.event.description': 'Jira Ticket',}}});
Query annotations in Notebooks
Since annotation events are stored in Grail, you can query and later display them in Dashboards or Notebooks using the following DQL:
fetch dt.davis.events| filter event.type == "CUSTOM_ANNOTATION"| filter isNotNull(annotation.problem_ids) and isNotNull(annotation.id)| dedup annotation.id, sort: { event.start desc }
Ingest problem comments and annotations through API
You can use the existing event ingest REST API to ingest problem comment and annotation events. To do so, ensure that the API token has the event.ingest access scope.
The annotation.id field must be unique for each comment, since it can be used to override an existing comment. If you send an updated annotation using the same annotation.id, the previous comment will be overwritten.
This is an example of ingesting a problem markdown comment from an external AI agent:
POST https://<YOUR-TENANT-ID>.live.dynatrace.com/api/v2/events/ingest HTTP/1.1Authorization: Api-Token <YOUR-API-TOKEN>content-type: application/json{"eventType": "CUSTOM_ANNOTATION","title": "This is an annotation","properties": {"annotation.source": "My own AI Agent","annotation.id": "unique-id-12345","annotation.url": "https://example.com","annotation.problem_ids": "-8846223150850373620_1779767520000V2","dt.event.description": "## My own AI agent findings\n\nThis annotation was created by an AI agent to provide more context about the problem."}}
Ingest problem annotations
You can ingest your problem annotations at any time after a problem was detected and created in Dynatrace, regardless of whether you created the annotation minutes or days after the problem opened.
Problems ingests annotations by using a DQL join command based on the problem_ids field. This means that Problems doesn't group or collect the annotation events into the problem. As a result, annotation events don't show up in the Problems events list or within the problem records event_ids array.
If you want to create or ingest annotation events, you can use the same ingestion mechanism and permission policies as standard Davis info events. To create an annotation event, you can use:
- JavaScript SDK
- REST API
- Workflows
- Problem details page UI
- OpenPipeline extraction rules for Davis events
An example of a Javascript workflow action that creates a problem annotation
import { eventsClient, EventIngestEventType } from "@dynatrace-sdk/client-classic-environment-v2";import { execution } from '@dynatrace-sdk/automation-utils';export default async function ({ execution_id }) {const ex = await execution(execution_id);const problem_event = ex.params.event;var problem_id = problem_event['event.id'];const nowInUTC = Date.now();// Create an annotation event. Use a one point in timeconst resultAnn = await eventsClient.createEvent({body: {eventType: 'CUSTOM_ANNOTATION',title: 'Analysis result',startTime: nowInUTC,endTime: nowInUTC,properties: {'annotation.source': 'AWS SRE Agent','annotation.id': '' + Math.random(),'annotation.url': 'https://www.dynatrace.com','annotation.problem_ids': problem_id,'event.name': 'AWS Cloudsmith analysis result','event.description': 'This is a finding coming from **AWS**',}}});};
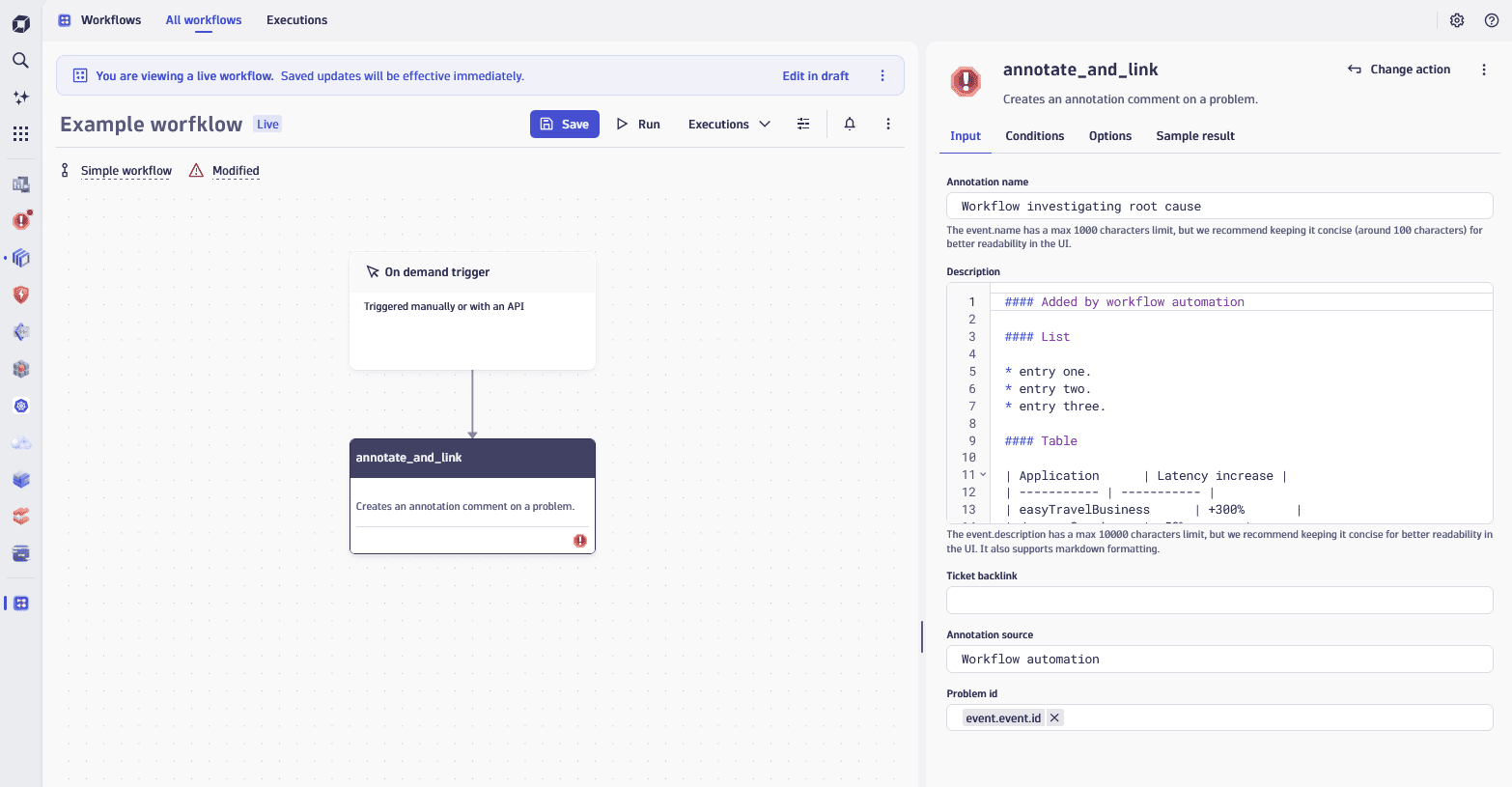
You can also use Annotate & link workflow action to simplify the creation of problem annotations in Dynatrace Automation workflows, as seen in the example below:
Use cases
 Problems
Problems