Kong AI Gateway
- Latest Dynatrace
- Explanation
- 2-min read
The Kong AI Gateway is a set of features built on top of Kong Gateway, designed to help developers and organizations adopt AI capabilities quickly and securely. It provides a normalized API layer that allows clients to consume multiple AI services from the same client code base.
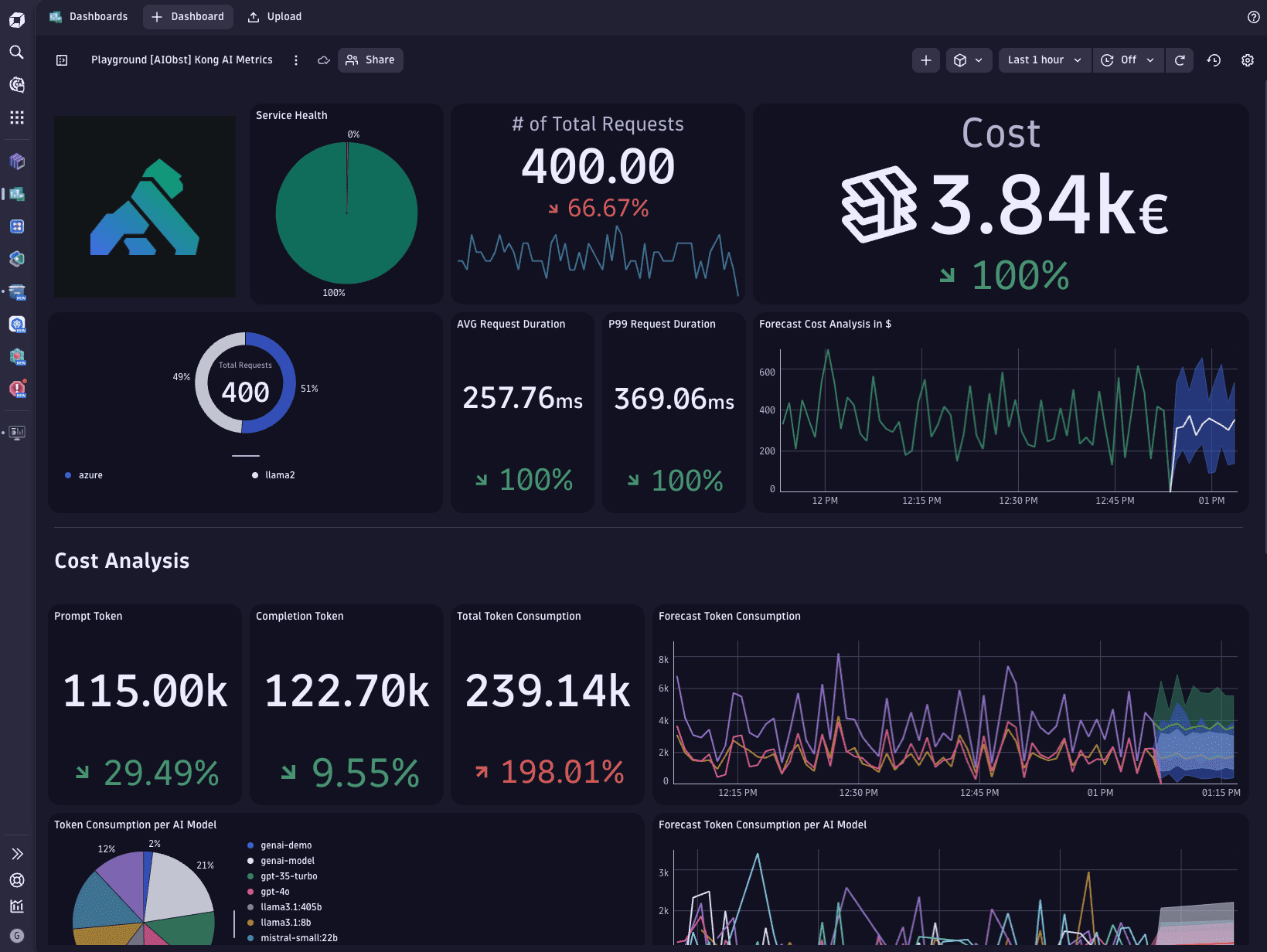
Explore the sample dashboard on the Dynatrace Playground.
Enable monitoring
Ensure that the Kong Prometheus plugin is enabled and exposes AI LLM metrics.
Follow the Set up Dynatrace on Kubernetes guide to monitor your cluster.
Afterwards, add the following annotations to your Kong Deployments:
metrics.dynatrace.com/scrape: "true"metrics.dynatrace.com/port: "8100"
Spans
The following attributes are available for GenAI Spans.
| Attribute | Type | Description |
|---|---|---|
gen_ai.completion.0.content | string | The full response received from the GenAI model. |
gen_ai.completion.0.content_filter_results | string | The filter results of the response received from the GenAI model. |
gen_ai.completion.0.finish_reason | string | The reason the GenAI model stopped producing tokens. |
gen_ai.completion.0.role | string | The role used by the GenAI model. |
gen_ai.openai.api_base | string | GenAI server address. |
gen_ai.openai.api_version | string | GenAI API version. |
gen_ai.openai.system_fingerprint | string | The fingerprint of the response generated by the GenAI model. |
gen_ai.prompt.0.content | string | The full prompt sent to the GenAI model. |
gen_ai.prompt.0.role | string | The role setting for the GenAI request. |
gen_ai.prompt.prompt_filter_results | string | The filter results of the prompt sent to the GenAI model. |
gen_ai.request.max_tokens | integer | The maximum number of tokens the model generates for a request. |
gen_ai.request.model | string | The name of the GenAI model a request is being made to. |
gen_ai.request.temperature | double | The temperature setting for the GenAI request. |
gen_ai.request.top_p | double | The top_p sampling setting for the GenAI request. |
gen_ai.response.model | string | The name of the model that generated the response. |
gen_ai.system | string | The GenAI product as identified by the client or server instrumentation. |
gen_ai.usage.completion_tokens | integer | The number of tokens used in the GenAI response (completion). |
gen_ai.usage.prompt_tokens | integer | The number of tokens used in the GenAI input (prompt). |
llm.request.type | string | The type of the operation being performed. |
Metrics
After following the steps above, the following metrics will be available:
| Metric | Type | Unit | Description |
|---|---|---|---|
ai_llm_requests_total | counter | integer | AI requests total per ai_provider in Kong |
ai_llm_cost_total | counter | integer | AI requests cost per ai_provider/cache in Kong |
ai_llm_provider_latency_ms_bucket | histogram | ms | AI latencies per ai_provider in Kong |
ai_llm_tokens_total | counter | integer | AI tokens total per ai_provider/cache in Kong |
ai_cache_fetch_latency | histogram | ms | AI cache latencies per ai_provider/database in Kong |
ai_cache_embeddings_latency | histogram | ms | AI cache embedding latencies per ai_provider/database in Kong |
ai_llm_provider_latency | histogram | ms | AI provider latencies per ai_provider/database in Kong |
Additionally, the following metrics are reported.
| Metric | Type | Unit | Description |
|---|---|---|---|
gen_ai.client.generation.choices | counter | none | The number of choices returned by chat completions call. |
gen_ai.client.operation.duration | histogram | s | The GenAI operation duration. |
gen_ai.client.token.usage | histogram | none | The number of input and output tokens used. |
llm.openai.embeddings.vector_size | counter | none | The size of returned vector. |
Related tags
AI Observability