Drill-down to service failure causes
- Dynatrace Classic
- Tutorial
- 1-min read
Analyzing individual requests is a useful way of gaining a better understanding of detected errors. In this article, you will learn how to determine the error underlining an increasing service failure rate using distributed tracing.
Scenario
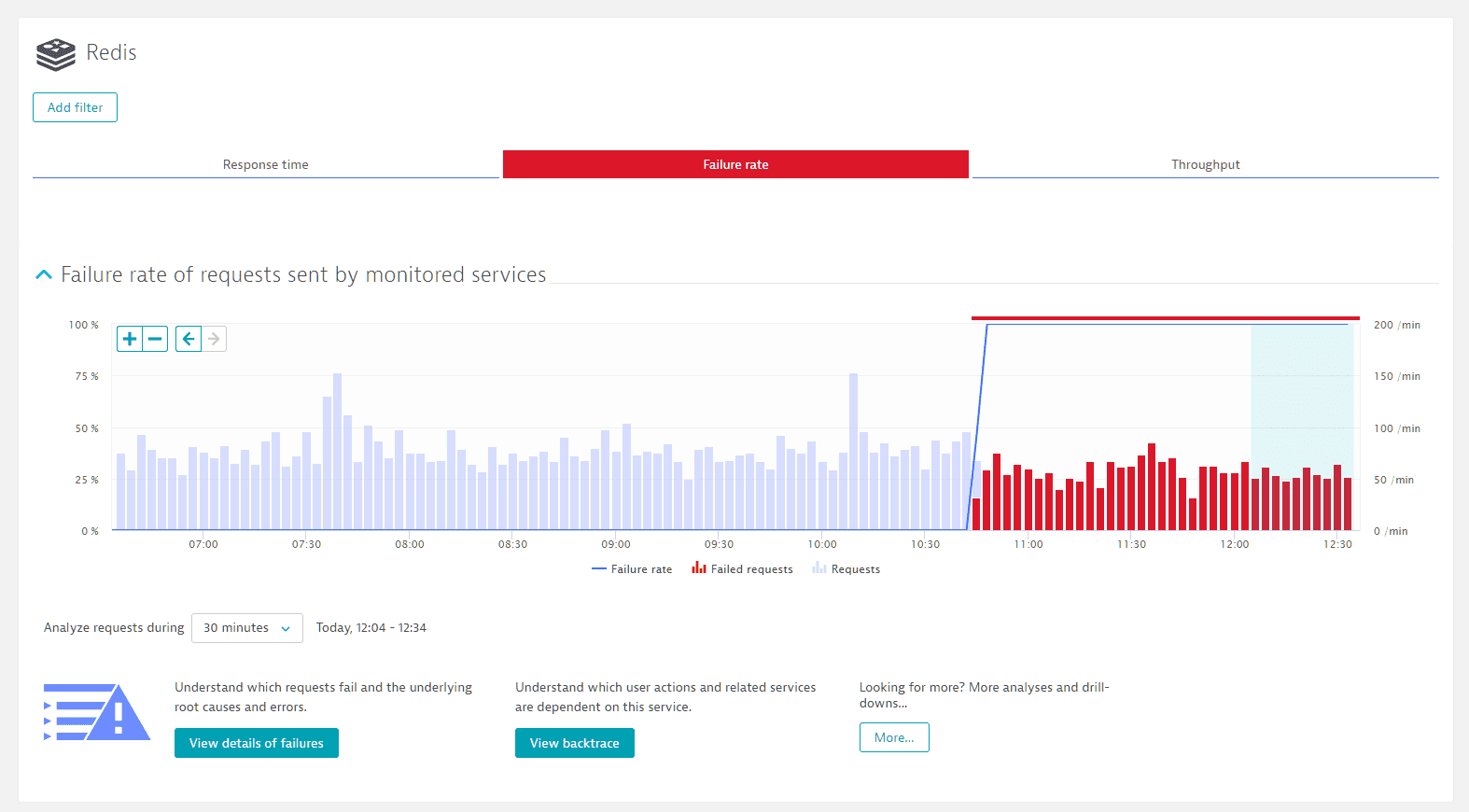
In the image below, you can see that requests to Redis started to fail around the 10:45 mark on the timeline.
Steps
-
To find the Failure rate tab, go to the service’s details page and select a View button (such as View requests, View dynamic requests, or View resource requests).
 Distributed trace 11
Distributed trace 11 -
Select Analyze backtrace to see where these requests came from.
The requests originate from the
weather-expressservice and nearly all failed requests toRedishave the same exception—anAbortErrorcaused by a closed connection.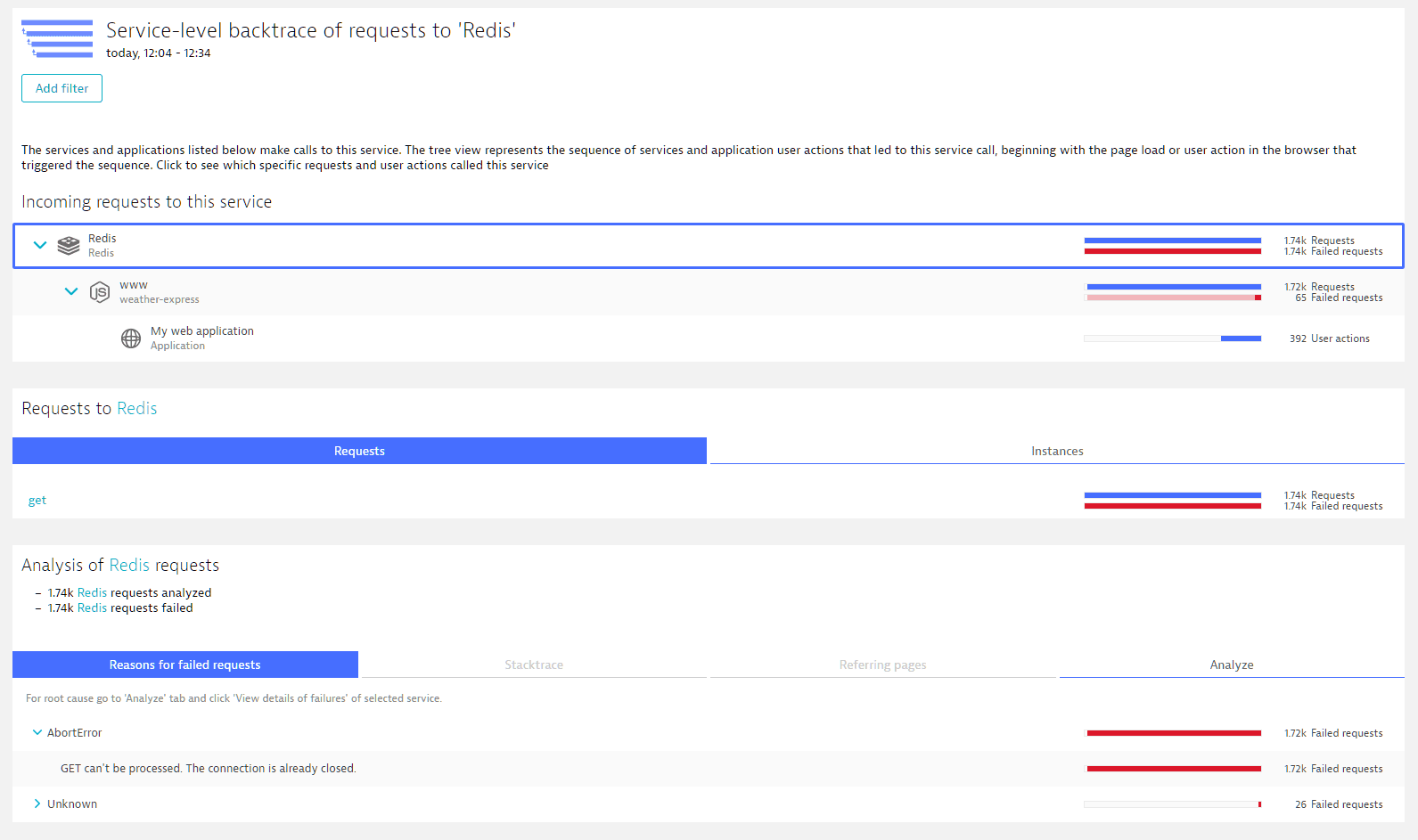 Distributed trace 12
Distributed trace 12 -
To analyze down to the affected
Node.jstraces, select More (…) > Distributed traces.By looking at the
Node.jstrace and its code-level execution tree below, you can see that aRedisrequest leads to an error. You can see where this error occurs in the flow of theNode.jscode.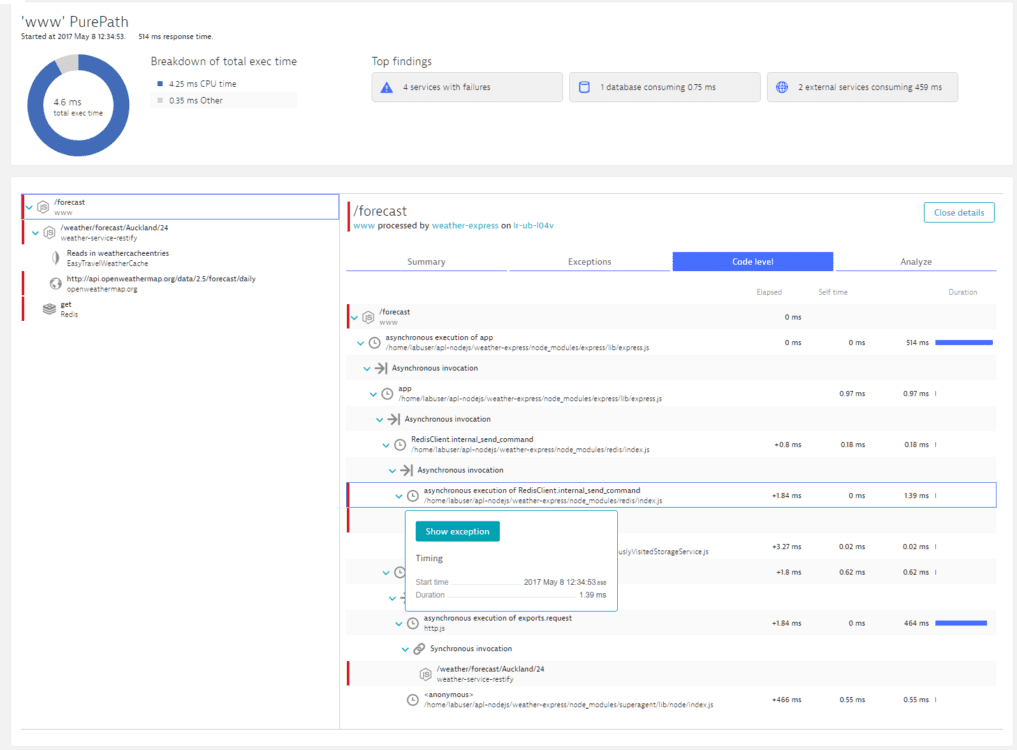 Distributed trace 13
Distributed trace 13 -
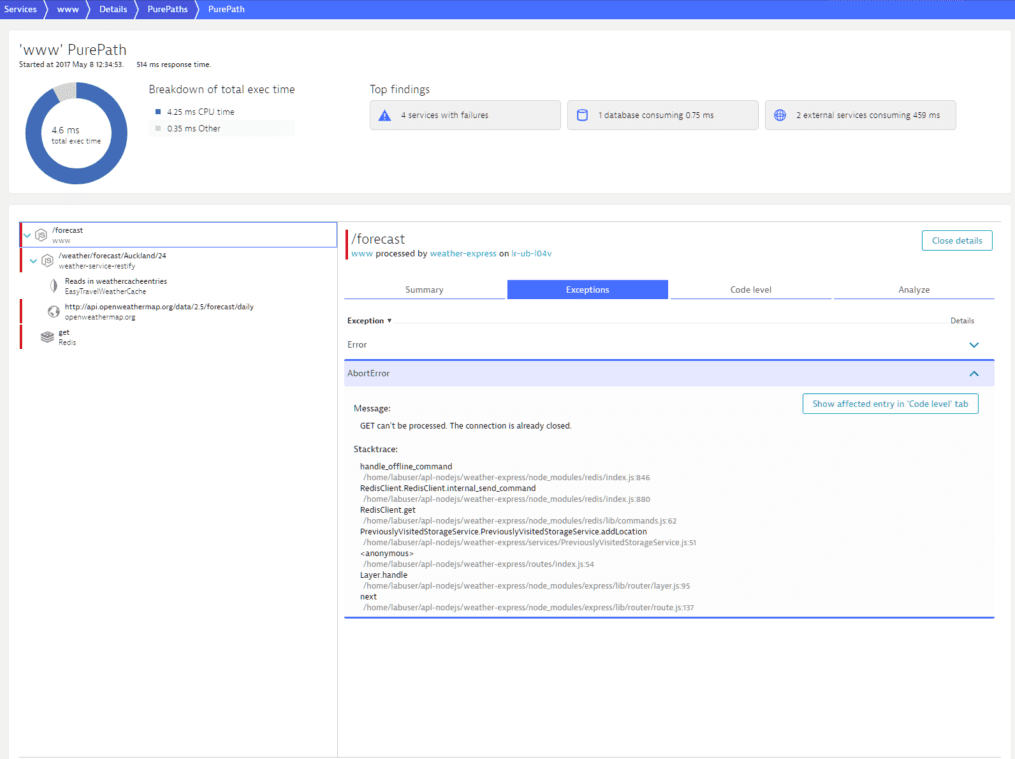
Select the Errors tab to analyze the exception.
 Distributed trace 14
Distributed trace 14
Conclusion
Each distributed trace on the Errors tab shows a unique set of parameters leading up to the error. With this approach to analysis, the distributed traces view can be very useful in helping you understand why certain exceptions occurred.
 Distributed Traces Classic
Distributed Traces Classic