Cisco Catalyst Center (DNA Center) extension
- Latest Dynatrace
- Extension
Monitor Cisco Catalyst Center (DNA Center) network infrastructure with device health, performance, client experience, and topology insights.
Get started
Overview
Cisco Catalyst Center is formerly known as Cisco DNA.
Collect information about networks that are managed by the Cisco Catalyst Center.
This extension assumes that you:
- Use Dynatrace for infrastructure monitoring.
- Run Cisco Catalyst Center in their environment.
- Look to extend Dynatrace insights into the Cisco Catalyst platform.
The Cisco Catalyst Center extension uses the Cisco Catalyst API to collect information about networks that are managed by Cisco Catalyst Center.
Use cases
- Integrate operational monitoring of the infrastructure, including Cisco Catalyst and leveraging additional organization, network and device metadata.
- Get root cause analysis of network issues, in the light of the entire application and infrastructure landscape observed by Dynatrace.
- Collect network infrastructure data without having to poll individual devices.
Requirements
-
Network access from a Dynatrace ActiveGate to the Cisco Catalyst Center.
-
You have configured the Cisco Catalyst Center.
-
Optional You have created a
read-onlyrole specific for API access. A specific role is not required, but is necessary for privilege management. If not used, the pre-defined role is used by default.To create a role:
- Go to System > Users & Roles > Role Based Access Control > Create a New Role.
- Define the name (for example,
API-READONLY-ROLE) and an optional description. - For all privileges, select READ.
-
You have created a user for API integration. To create a user:
- Go to System > Users & Roles > User Management > Add User.
- Select a role, whether the read-only role or the pre-defined role.
-
Optional Check access control.
- Go to System > Trust & Privacy > IP Access Control
- If access control filtering is enabled, add the IP address of your Dynatrace system.
Compatibility information
- Cisco Catalyst Center (DNA) version 2.3.7.6+ (For more information on API compatibility, see FAQ.)
Activation and setup
To enable the extension, find Cisco Catalyst Center (DNA Center) in the Dynatrace Hub.
Details
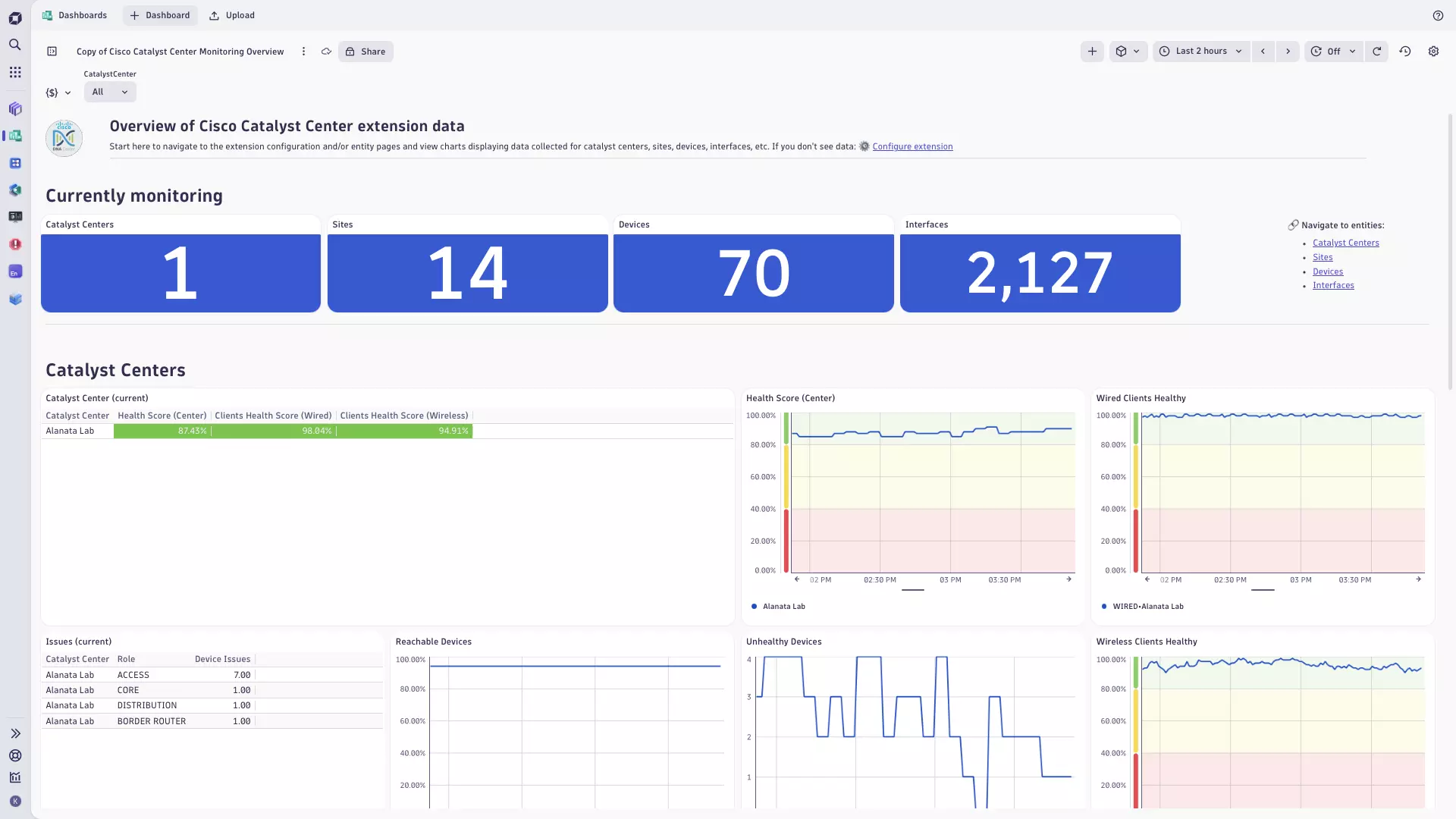
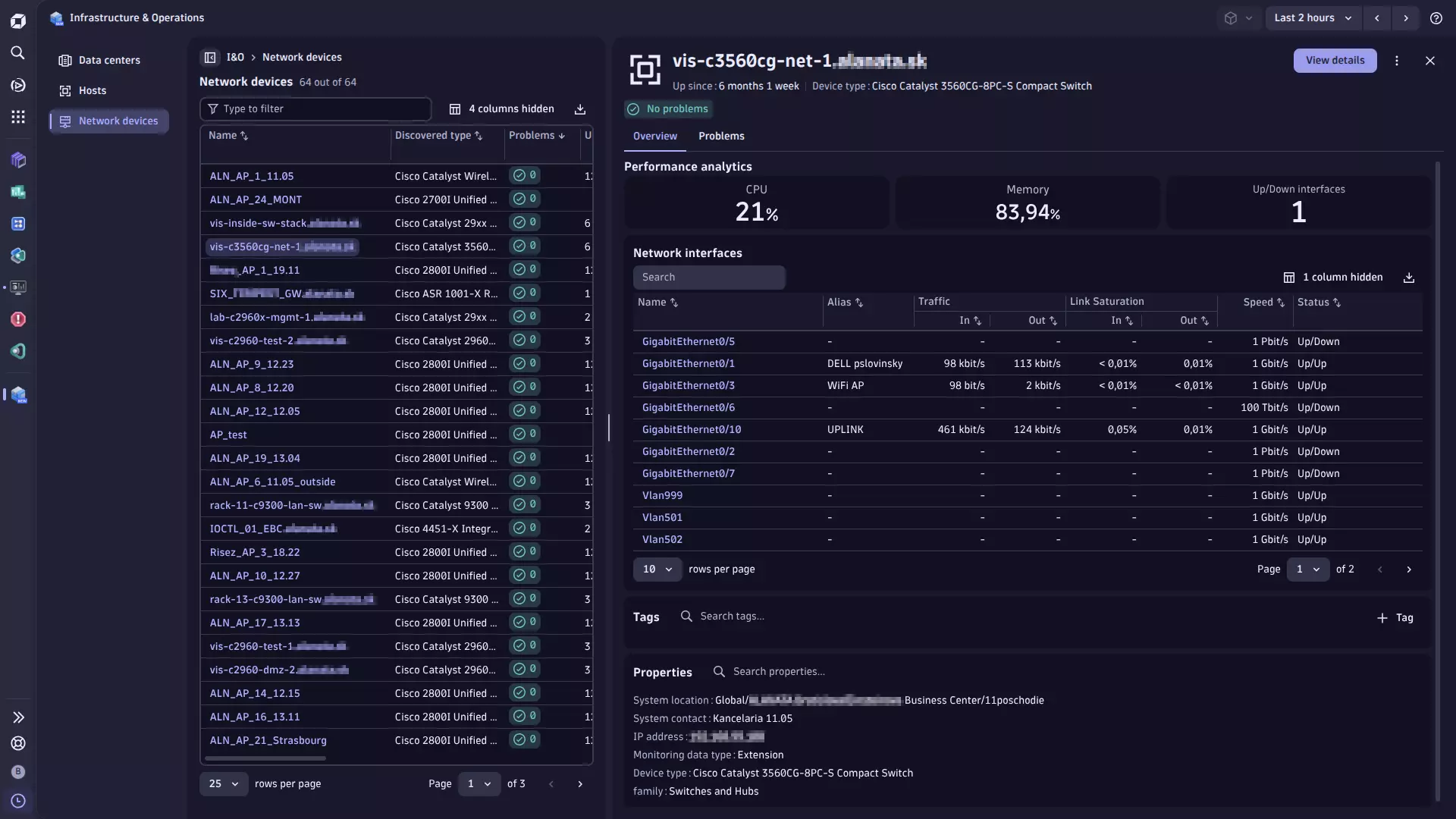
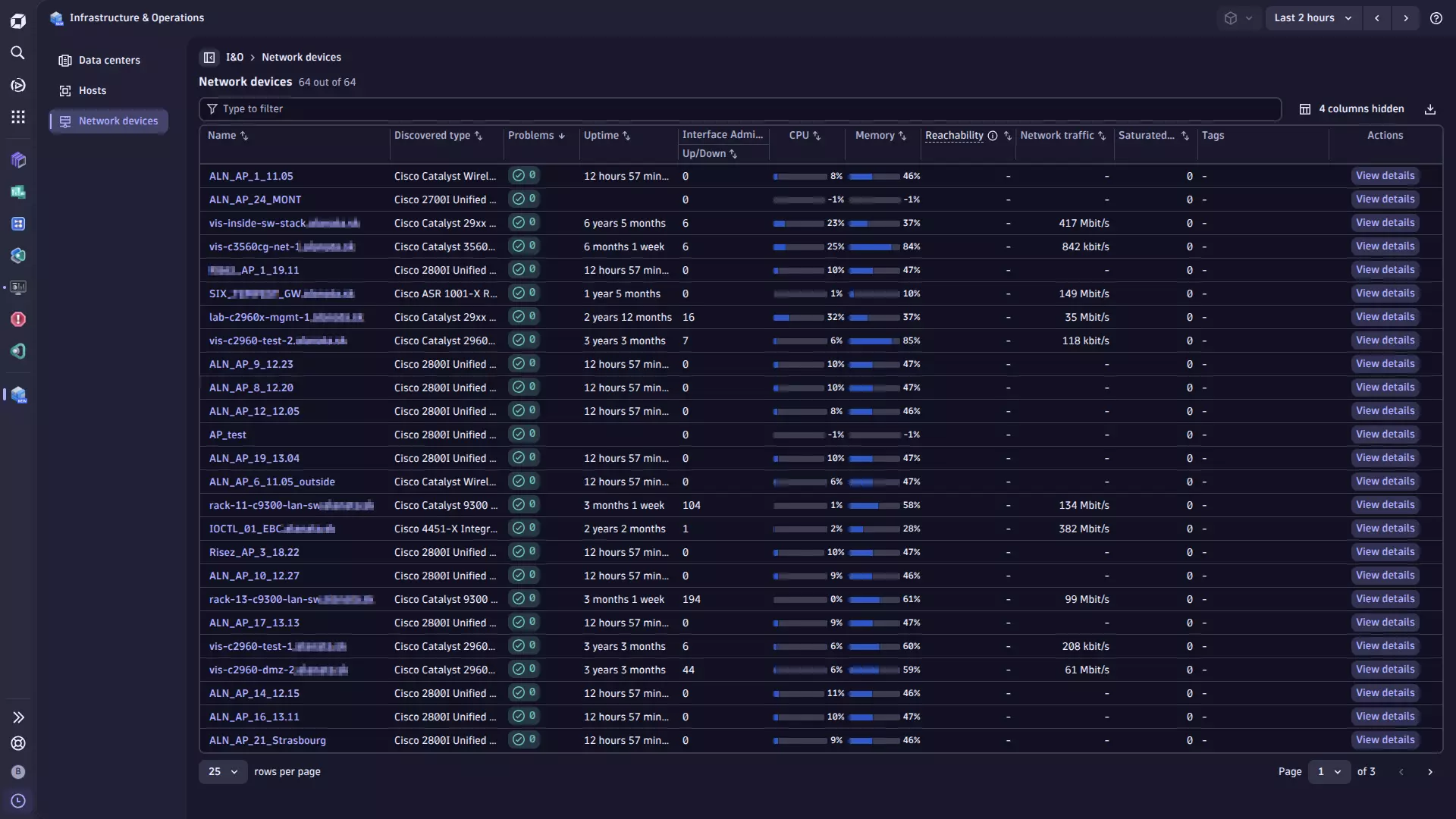
This extension can monitor the following entities:
- Catalyst Center
- Catalyst Site
- Catalyst Device
- Catalyst Interface
The extension offers the following features:
- Insights into the configuration, locations, and health status of devices and their interfaces.
- Analysis screens present data hierarchically, helping to quickly diagnose issues by site, role or by device platform.
- Performance and health metrics as well as Cisco Catalyst issues/events. Basic statistics of client devices are also available.
- Extension code (Python) that connects to the Cisco Catalyst API endpoints and scrapes the metrics.
- A dashboard offering high-level Cisco Catalyst platform overview.
- Unified Analysis pages for Cisco Catalyst Center, devices, sites and interfaces.
- Analysis screens integrated with
 Infrastructure & Operations.
Infrastructure & Operations.
- Optional issue reporting and event generation based on Catalyst Center issues, configurable to fit your environment.
- Optional tag-based metric reporting frequency control using Catalyst device tags.
Issue reporting and Dynatrace event integration
The extension includes support for ingesting issues from Catalyst Center.
Issues are either reported as log messages or raised as Dynatrace events.
-
Issues can be reported as log messages. You can configure filtering by issue priority to report only the relevant ones.
-
Issues can be raised as Dynatrace events. This enables the following advanced capabilities:
- Custom event type mapping: Map issue priorities or device families to specific Dynatrace event types (e.g.,
ERROR_EVENT,CUSTOM_ALERT,CUSTOM_INFO). - Default and conditional event overrides: Use a default event type (
ERROR_EVENT) with support for condition-based overrides. - Event Suppression: Optionally suppress certain events entirely using a special suppression value.
Event generation applies only to issues that are already enabled for log message reporting.
- Custom event type mapping: Map issue priorities or device families to specific Dynatrace event types (e.g.,
Catalyst Center events reporting and Dynatrace events ingest integration
The extension supports ingesting events and notifications from Cisco Catalyst Center. Catalyst Center events are reported as log messages, which are ingested by Dynatrace and can subsequently trigger Dynatrace events.
-
To report Catalyst Center events as log messages, configure Catalyst Center event queries by:
- Event ID (see the Cisco Catalyst Center Event Catalog),
- Type (
NETWORK,APP,SYSTEM,SECURITY,INTEGRATIONS), - Category (
INFO,WARN,ALERT,ERROR) to report only the relevant ones.
Report metrics based on Catalyst tags
Cisco Catalyst API version 2.3.7.6+
This feature lets you control how often metrics are reported for devices and interfaces, based on Catalyst tags. It does not affect how often data is polled from Cisco Catalyst Center; it only controls how often metrics are reported to Dynatrace.
Key capabilities:
- Tag-based frequency control: Set custom reporting intervals for metrics based on Catalyst device tags.
- Untagged device handling: Define how often to report metrics for devices without Catalyst tags.
- Flexible tag mapping: Configure multiple tag-to-frequency mappings.
- Selective suppression: Metric reporting for devices and their interfaces can be fully disabled based on specific Catalyst tags.
Extension metrics grouping via feature sets
Metrics collected by the Cisco Catalyst extension are categorized in the following feature sets:
- Default: Provides an overview of the overall health status in Cisco Catalyst Center.
Includes interface and device-specific metrics used in Infrastructure & Operations.
- Site: Contains metrics related to Catalyst Sites managed by Cisco Catalyst Center.
- Device: Covers metrics for Catalyst Devices managed by Cisco Catalyst Center.
- Interface: Captures metrics for Catalyst Interfaces on managed devices.
- Client: Overall statistics for clients as reported by the Catalyst Center.
- Self-monitoring: Optional Metrics for fine-tuning and diagnostics of the extension itself.
Discovery frequencies adjustment
If you reduce the metrics collection frequency (for example, when adapting to a large environment constraints), it is also recommended to adjust discovery-related configuration parameters accordingly. These parameters should be increased proportionally, since they track semi-static attributes that do not need to be refreshed as frequently. Entity attributes and metrics dimension values are then updated according to the defined discovery frequencies.
These discovery intervals determine how often relatively static attributes are queried from Cisco Catalyst Center. By increasing these values proportionally, you reduce unnecessary load without compromising data accuracy.
| Parameter | Recommended multiplier | Recommended frequency, based on a five-minute metric frequency |
|---|---|---|
Sites discovery frequency | 12 | 60 minutes |
Devices discovery frequency | 6 | 30 minutes |
Interfaces discovery frequency | 3 | 15 minutes |
Licensing and costs
There is no charge to use the extension. You are only charged for the data that the extension ingests.
The Cisco Catalyst Center (DNA Center) extension ingests custom metrics, which consume Davis Data Units (DDUs) (Dynatrace classic license) or Metrics powered by Grail (DPS), according to your license model.
Assuming all feature sets are enabled, the approximate number of metric data points per minute is:
( 29+ ( 7 * <Number of sites> )+ ( 14 * <Number of monitored devices> )+ ( 3 * <Number of monitored interfaces> )+ ( 11 * <Number of monitored interfaces with operational status `UP`> )) / <metrics collection interval>+ 2 * <Number of sites> / <sites discovery interval>+ 2 * <Number of monitored devices> / <devices discovery interval>+ 1 * <Number of monitored interfaces> / <interface discovery interval>+ 25 // optional - self-monitoring metrics+ 13 // optional - self-monitoring metrics (tracking communication errors with Catalyst Center - reported only if errors occur)
Dynatrace Platform Subscription
In the Dynatrace Platform Subscription, metric ingestion consumes Metrics powered by Grail according to the number of ingested metric data points.
To calculate the approximate yearly consumption, apply the following calculation: <metric data points per minute> * 60 minutes * 24 hours * 365 days.
Dynatrace classic license
In the classic licensing model, metric ingestion consumes Davis Data Units (DDUs) at the rate of .001 DDUs per metric data point. Multiply the above formula for annual data points by .001 to estimate annual DDU usage.
The DDU cost above does not include any possible log events or custom events that are triggered by the extension. For more information, see DDU events.
Feature sets
When activating your extension using a monitoring configuration, you can limit monitoring to one of the feature sets. To work properly, the extension has to collect at least one metric after the activation.
In highly segmented networks, feature sets can reflect the segments of your environment. Then, when you create a monitoring configuration, you can select a feature set and a corresponding ActiveGate group that can connect to this particular segment.
All metrics that aren't categorized into any feature set are considered to be the default and are always reported.
A metric inherits the feature set of a subgroup, which in turn inherits the feature set of a group. Also, the feature set defined on the metric level overrides the feature set defined on the subgroup level, which in turn overrides the feature set defined on the group level.
default
| Metric name | Metric key | Description |
|---|---|---|
| — | com.dynatrace.extension.network_device.cpu_usage | — |
| — | com.dynatrace.extension.network_device.memory_usage | — |
| — | com.dynatrace.extension.network_device.sysuptime | — |
| — | com.dynatrace.extension.network_device.memory_total | — |
| — | com.dynatrace.extension.network_device.if.status | — |
| — | com.dynatrace.extension.network_device.if.bytes_in.count | — |
| — | com.dynatrace.extension.network_device.if.bytes_out.count | — |
interface
| Metric name | Metric key | Description |
|---|---|---|
| Interface Count | cisco.cc.device.total_interface_count.gauge | Total Number of Interfaces for Device |
| Admin Status | cisco.cc.interface.admin_status | Interface's Admin Status (1: UP | 0: DOWN) |
| Oper Status | cisco.cc.interface.oper_status | Interface's Status (1: UP | 0: DOWN) |
| Speed | cisco.cc.interface.speed | — |
| TX Rate | cisco.cc.interface.txRate | — |
| TX Utilization | cisco.cc.interface.txUtilization | — |
| TX Discards | cisco.cc.interface.txDiscards | — |
| TX Errors | cisco.cc.interface.txError | — |
| RX Rate | cisco.cc.interface.rxRate | — |
| RX Utilization | cisco.cc.interface.rxUtilization | — |
| RX Discards | cisco.cc.interface.rxDiscards | — |
| RX Errors | cisco.cc.interface.rxError | — |
device
| Metric name | Metric key | Description |
|---|---|---|
| Health | cisco.cc.device.health | Device's Health |
| CPU | cisco.cc.device.cpu | Device's CPU consumption |
| Memory | cisco.cc.device.memory | Device's Memory consumption |
| Average Temperature | cisco.cc.device.temperature | Device's Avg Temperature |
| Device Issues | cisco.cc.device.issue_count.gauge | Pending Device Issues |
| Reachability | cisco.cc.device.reachability | Device's Reachability (1: Reachable | 0: Not Reachable) |
| Uptime | cisco.cc.device.uptime.gauge | Device Uptime in Seconds |
| Issue Events | cisco.cc.device.issue_events.gauge | Issue events over selected timeframe |
center
| Metric name | Metric key | Description |
|---|---|---|
| Health score (Center) | cisco.cc.center.health_score | Cisco Catalyst Network topology - Overall health score |
| Healthy devices | cisco.cc.center.healthy_devices | Cisco Catalyst Network topology - Healthy devices |
| Unhealthy devices | cisco.cc.center.unhealthy_devices | Cisco Catalyst Network topology - Unhealthy devices |
| Clients health score | cisco.cc.client.health_score | Cisco Catalyst Client - Overall client health score |
| Clients Count | cisco.cc.client.client_count.gauge | Cisco Catalyst Client - Clients count |
| Unique Clients Count | cisco.cc.client.client_unique_count.gauge | Cisco Catalyst Client - Unique Clients Count |
| Clients health score count | cisco.cc.client.health_score_count.gauge | Cisco Catalyst Client - Clients health score by score type |
| Catalyst Center Notification Count | cisco.cc.center.notification_count.gauge | Number of Cisco Catalyst Center event notifications reported per collection interval |
site
| Metric name | Metric key | Description |
|---|---|---|
| Wired Clients Score | cisco.cc.site.client_health_wired | Site's Wired Clients Health Score |
| Wireless Clients Score | cisco.cc.site.client_health_wireless | Site's Wireless Clients Health Score |
| Clients | cisco.cc.site.client_count.gauge | Site's Clients Summary Count |
| Wired Clients | cisco.cc.site.wired_client_count.gauge | Site's Wired Clients Summary Count |
| Wireless Clients | cisco.cc.site.wireless_client_count.gauge | Site's Wireless Clients Summary Count |
| Healthy Clients | cisco.cc.site.client_good_health_percentage | Site's Healthy Clients Summary Percentage |
| Devices | cisco.cc.site.network_device_count.gauge | Site's Devices Summary Count |
| Healthy Devices | cisco.cc.site.network_device_good_health_percentage | Site's Healthy Devices Summary Percentage |
| Site Issues | cisco.cc.site.issue_count.gauge | Pending Site Issues |
self-monitoring
| Metric name | Metric key | Description |
|---|---|---|
| Device Count Query Duration | sfm.cisco.cc.get_devices_by_query_count.duration | Duration of the get_devices_by_query_count API call used to determine total device count before paginated collection. |
| Device Count Query Errors | sfm.cisco.cc.get_devices_by_query_count.error | Number of errors during get_devices_by_query_count API call. |
| Device Query Page Duration | sfm.cisco.cc.get_devices_by_query.duration | Duration of a single paginated get_devices_by_query API call used to collect device data. |
| Device Query Page Errors | sfm.cisco.cc.get_devices_by_query.error | Number of errors during a paginated get_devices_by_query API call. |
| Device Discovery Count Query Duration | sfm.cisco.cc.get_network_devices_count_by_params.duration | Duration of the get_network_devices_count_by_params API call used to determine device count during BASIC discovery. |
| Device Discovery Count Query Errors | sfm.cisco.cc.get_network_devices_count_by_params.error | Number of errors during get_network_devices_count_by_params API call. |
| Device Discovery Query Page Duration | sfm.cisco.cc.get_network_devices_by_params.duration | Duration of a single paginated get_network_devices_by_params API call used for BASIC device discovery. |
| Device Discovery Query Page Errors | sfm.cisco.cc.get_network_devices_by_params.error | Number of errors during a paginated get_network_devices_by_params API call. |
| Physical Topology Query Duration | sfm.cisco.cc.get_physical_topology.duration | Duration of the get_physical_topology API call used to collect physical network topology data. |
| Physical Topology Query Errors | sfm.cisco.cc.get_physical_topology.error | Number of errors during get_physical_topology API call. |
| Site Count Query Duration | sfm.cisco.cc.get_sites_count.duration | Duration of the get_sites_count API call used to determine total site count before paginated collection. |
| Site Count Query Errors | sfm.cisco.cc.get_sites_count.error | Number of errors during get_sites_count API call. |
| Site Query Page Duration | sfm.cisco.cc.get_sites.duration | Duration of a single paginated get_sites API call used to collect site data. |
| Site Query Page Errors | sfm.cisco.cc.get_sites.error | Number of errors during a paginated get_sites API call. |
| Site Topology Query Duration | sfm.cisco.cc.get_sites_topology.duration | Duration of the get_sites_topology API call used to collect site hierarchy topology. |
| Site Topology Query Errors | sfm.cisco.cc.get_sites_topology.error | Number of errors during get_sites_topology API call. |
| Interface Count Query Duration | sfm.cisco.cc.get_interfaces_by_query_count.duration | Duration of the get_interfaces_by_query_count API call used to determine total interface count before paginated collection. |
| Interface Count Query Errors | sfm.cisco.cc.get_interfaces_by_query_count.error | Number of errors during get_interfaces_by_query_count API call. |
| Interface Query Page Duration | sfm.cisco.cc.get_interfaces_by_query.duration | Duration of a single paginated get_interfaces_by_query API call used to collect interface data. |
| Interface Query Page Errors | sfm.cisco.cc.get_interfaces_by_query.error | Number of errors during a paginated get_interfaces_by_query API call. |
| Interface Discovery Count Query Duration | sfm.cisco.cc.get_intent_api_interfaces_count.duration | Duration of the get_intent_api_interfaces_count API call used to determine interface count during Intent API discovery. |
| Interface Discovery Count Query Errors | sfm.cisco.cc.get_intent_api_interfaces_count.error | Number of errors during get_intent_api_interfaces_count API call. |
| Interface Discovery Query Page Duration | sfm.cisco.cc.get_intent_api_interfaces.duration | Duration of a single paginated get_intent_api_interfaces API call used for Intent API interface discovery. |
| Interface Discovery Query Page Errors | sfm.cisco.cc.get_intent_api_interfaces.error | Number of errors during a paginated get_intent_api_interfaces API call. |
| Network Health Query Duration | sfm.cisco.cc.get_network_health.duration | Duration of the get_network_health API call used to collect overall network health scores. |
| Network Health Query Errors | sfm.cisco.cc.get_network_health.error | Number of errors during get_network_health API call. |
| Client Health Query Duration | sfm.cisco.cc.get_client_health.duration | Duration of the get_client_health API call used to collect client health scores. |
| Client Health Query Errors | sfm.cisco.cc.get_client_health.error | Number of errors during get_client_health API call. |
| Site Health Summaries Query Duration | sfm.cisco.cc.get_site_health_summaries.duration | Duration of the get_site_health_summaries API call used to collect site-level health summary data. |
| Site Health Summaries Query Errors | sfm.cisco.cc.get_site_health_summaries.error | Number of errors during get_site_health_summaries API call. |
| Issues Query Duration | sfm.cisco.cc.issues.duration | Duration of the issues API call used to collect Catalyst Center issues data. |
| Issues Query Errors | sfm.cisco.cc.issues.error | Number of errors during issues API call. |
| Event Notifications Query Duration | sfm.cisco.cc.events.duration | Duration of the events API call used to collect Catalyst Center event notifications data. |
| Event Notifications Query Errors | sfm.cisco.cc.events.error | Number of errors during events API call. |
| Group Records Fetched | sfm.cisco.cc.group.records_fetched.gauge | Total number of raw device or interface records fetched from the API for this reporting configuration group. |
| Group Entities Reported | sfm.cisco.cc.group.entities_reported.gauge | Number of entities (devices or interfaces) reported to Dynatrace for this reporting configuration group. |
| Group Overlap Devices | sfm.cisco.cc.group.overlap_devices.gauge | Number of devices matching this group filter that are reported by a different reporting configuration. Only emitted when OVERLAP strategy is active and overlap count is greater than zero. |
FAQ
How many devices/interfaces/sites can I monitor with this extension?
Practical tests reveal the following rule of thumb: 1000 devices per each one minute monitoring interval.
This means that with a five-minute monitoring interval, it should be achievable to monitor 5000 devices with a single ActiveGate.
Note that scaling estimates must be based on the real number of devices in the monitored system.
Filters configured in the extension are applied only after all device and interface data has already been polled, due to REST API limitations in the supported Catalyst Center versions.
These are estimates. Results in your environment may vary, depending on:
- The number of interfaces on each of the monitored devices.
- The number of sites that the Catalyst Center manages.
- Your Catalyst Center response time and network connection throughput between Catalyst Center and the ActiveGate.
The estimation assumes that
- You have six interfaces per device, or 30,000 interfaces per five-minute monitoring interval.
- You have 500 sites.
- Catalyst Center responds within the single seconds.
- The connection from Catalyst Center to ActiveGate is via a local area network.
- The Catalyst Center extension runs on an ActiveGate with the dedicated performance profile. See About Extensions for more details on performance profiles.
Should I split monitoring configuration into many instances to scale the extension out?
One monitoring configuration should track one Catalyst Center. Multiple monitoring configurations should be used to track multiple Catalyst Centers.
This is important to retain consistency in the Catalyst Center locations reporting. If you split a single Catalyst Center instance between more than one monitoring configuration, for example by using tag-based filters, you may end up with duplicate entities representing individual Catalyst Center locations. This results in double-counted metrics for these locations.
Can I increase monitoring intervals to five minutes, or 10 minutes, or 15 minutes?
We recommend a one-minute monitoring interval to retain high data fidelity for alerting and Dynatrace Intelligence reasoning. In very large environments, increasing monitoring interval may help with scalability; this however is always occupied with data fidelity loss. We don't recommend going beyond five.
Please note that data on entities that do not change often. This data is already collected less frequently and you can adjust it further. For more information, see Discovery frequencies adjustment.
Why are health, CPU, or memory values for some devices on the dashboard negative?
The Catalyst API returns negative values for non-reachable devices.
Do I need to enable all feature sets?
No, not all feature sets are required.
- The self-monitoring feature set is optional. It is only needed for fine-tuning and diagnostics of the extension itself.
- If you want to view platform screens (for generic network device and interface metrics) within Infrastructure & Operations, only the default feature set is needed.
- If you want to view both classic screens and all platform screens (for generic network device and interface metrics and for Cisco Catalyst device and interface metrics), enable all feature sets except self-monitoring.
Does the extension support other versions of Cisco Catalyst Center not listed in the Compatibility Information?
Yes, but with limitations. In the extension configuration, select the Cisco Catalyst Center Version that matches your installed version. If your exact version is not listed, choose the closest lower version available.
Please note that when connecting to versions of Cisco Catalyst Center other than those listed in Compatibility information, some metrics may be missing or unavailable.
Specifically, older API versions are not reliable as a source of the interface-related metrics, due to API scalability limitations. Therefore, when extension is connected to DNA Center 2.3.6.x or DNA Center 2.3.5.x or earlier, there will be no interface-level metrics available on chartsand in the Infrastructure & Operations.
Other metrics gaps may also exist.
We strongly recommend connecting to API versions listed in the Compatibility Information section.
I am getting a "SSL: CERTIFICATE_VERIFY_FAILED certificate verify failed" error (self-signed certificate in certificate chain error).
This indicates that the Catalyst endpoint uses a self-signed certificate. If you trust the endpoint, you can skip certification verification. To do this, in the connection settings, set Check SSL Certificate to false.
What if I need to configure separate proxy servers for different Catalyst endpoints?
If you need to use different HTTP proxy servers for different Catalyst endpoints, you should create a separate extension configuration for each proxy. The proxy defined in a configuration applies to all Catalyst endpoints within that configuration. To ensure that the correct proxy is used for each endpoint, define each proxy-endpoint pair in its own dedicated configuration.
Does the extension support monitoring of other entities, such as SSIDs or details on the access points?
Not yet.
We look forward to your feedback on the enhancements that would make this extension better fitted to your environment. Post your product idea in the Dynatrace community.
In the Python 3 log file, I see the error "Read timed out".
If you see RateLimitError messages, it means the extension is sending too many requests to the Catalyst Center, causing it to return RateLimitError and temporarily block connections from the extension.
This leads to timeouts.
To troubleshoot:
- Confirm that the network connection between the extension and the Catalyst Center is allowed.
- If
RateLimitError while calling client methodappears before theRead timed outerror, a potential solution is to increase theMetrics Collection Frequencyin the configuration, for example to 15 minutes. If increasing the value helps, fine-tune it as needed. Also check that the Page size in the configuration is set to the default values. The default values are the maximum allowed and reduce the number of requests. Smaller page sizes mean more requests. - If
RateLimitError while calling client methoddoes not appear before theRead timed outerror, open the Cisco Catalyst Extension Self-Monitoring dashboard and look at the Overall Metrics Data Collection Time graph. Based on the value in the graph, increase the Single Request Timeout setting in the extension configuration to a value higher than the one shown in the graph.
The Dynatrace gateway reports the error "Memory threshold exceeded" in the ruxitagent_extensionmodule log.
This issue can be resolved in several ways. In some cases, applying just one of the following steps is sufficient, while in others a combination may be needed:
-
Separate configurations for multiple endpoints. If a single extension configuration connects to multiple Catalyst Centers, all cached data from these endpoints is stored in one OS process. Create a dedicated configuration for each endpoint. Each configuration runs as a separate OS process, so the cached data from each endpoint is split across multiple processes.
-
Increase RAM on the ActiveGate server. Allocating more RAM to the ActiveGate machine can help prevent memory limit breaches.
-
Increase Extension Execution Controller limits. Adjust the limits in the
extensionsuser.conffile as described in the Dynatrace documentation, see Extension Execution Controller custom configuration. For example, you can add:# Memory settingsdslimit_python_mem=3000mem_soft_limit_percent=70.0mem_hard_limit_percent=80.0
On the Cisco Catalyst Center Monitoring Overview dashboard, I can see data for sites and devices, but there is no data at all for interfaces.
The Dynatrace entity instance limit for interfaces is 100,000.
If your Catalyst Center contains more than 100,000 interfaces, you may have reached the Dynatrace entity instance limit for Network Interface and Catalyst Interface entities.
To verify this, run the following DQL query:
timeseries entity_count_per_entity_type =sum(dt.sfm.server.monitored_entities.entity_count_per_entity_type,filter: in(dt.me_type_name, array("network:interface", "cisco_cc:interface"))),by: { dt.me_type_name }| fieldsAdd entity_count_per_entity_type.single_value = arrayLast(entity_count_per_entity_type)| fields `entity type`=dt.me_type_name, `entity count`=entity_count_per_entity_type.single_value
If the value is greater than 100,000, contact Dynatrace Support and request an increase of the entity limit for network interfaces (network:interface) and Catalyst interfaces (cisco_cc:interface) to 2.4 million for your tenant.
I have a high number of queries from the extension to the Catalyst Center. How can I reduce them?
Query consumption can be reduced in several ways:
-
Increase the value of
Metrics Collection Frequencyin the extension configuration. This interval has the most significant impact on query usage for this extension. -
Increase the intervals for Sites Discovery Frequency, Devices Discovery Frequency, and Interfaces Discovery Frequency in the configuration.
-
Disable certain feature sets in the extension configuration. This will reduce the amount of data collected, which in turn lowers query usage.
Disabling feature sets will result in missing data on Classic Analytic and Platform screens.
We have high DDU consumption for the Catalyst Extension. How can I reduce consumption?
Query consumption can be reduced in several ways:
-
Increase the value of
Metrics Collection Frequencyin the extension configuration. This interval has the most significant impact on query usage for this extension. -
Increase the intervals for Sites Discovery Frequency, Devices Discovery Frequency, and Interfaces Discovery Frequency in the configuration.
-
Disable certain feature sets in the extension configuration. This will reduce the amount of data collected, which in turn lowers query usage.
Disabling feature sets will result in missing data on Classic Analytic and Platform screens.
After upgrading Cisco Catalyst to the next version, metrics data are no longer reported. In the Python 3 log file, I see the error: "error: BAPI not found with technicalName <url path> and restMethod GET".
This issue typically occurs because the Cisco DNA Center REST API bundle was not automatically upgraded, even though the platform itself was.
To resolve this issue, disable and then re-enable the Cisco DNA Center REST API bundle. This forces a refresh and restores access to the affected endpoints.
- Log in to your Cisco Catalyst (DNA) Center system menu, go to Platform > Manage (or the equivalent path for your version).
- In the Bundles tab, locate the Catalyst Center REST API bundle.
- Disable the bundle, wait a few seconds, and then re-enable it.
- Restart the extension. Disable and then re-enable its configuration.
To troubleshoot the Catalyst endpoint itself and validate the REST API bundle:
- In the Cisco Catalyst (DNA) Center system menu, go to Platform > Developer Toolkit.
- In the APIs tab, locate the
<url path>API endpoint in question by searching in the URL column. Ensure that GET is specified in the Method column. - Select Try at the end of the line in the Actions column.
- Execute the query. Typically, deselect all query parameters and select Run.
In the log I see Error: Callback Method=monitor took x seconds ... longer than the interval of 60.0s
By default, the extension polls data from the Catalyst Center every 60 seconds, as configured in Polling > Metrics Collection Frequency. The polling process is implemented in the monitor method, which is also executed every 60 seconds. Therefore, when the polling process takes longer than 60 seconds, two scheduled executions of the monitor method overlap, which is undesirable.
To analyze this further, you can use the Cisco Catalyst Extension Self-Monitoring dashboard (provided that you've activated the self-monitoring feature set). This dashboard provides insights into data collection durations and even individual paged queries with the page offset as a dimension.
Recommended actions:
- Increase the Metrics Collection Frequency to 120 seconds or more.
- Deactivate some feature sets if you require high data fidelity but can exclude specific metrics.
After making the adjustment, recheck the data collection times to ensure the issue is resolved.
What is the expected performance impact of running API calls against the controller(s)? We are seeing some performance constraints in our DNAC GUI.
The extension uses API endpoints that provide internally pre-calculated or aggregated data. It employs paginated queries to retrieve data in chunks, minimizing the total number of API calls.
Precise estimation of the performance impact of these API calls on the controller is not feasible as this depends on the internal implementation of the controller itself.
By default, Cisco Catalyst Center APIs have a rate limit of 100 API calls per minute. (Some endpoints may allow 20, 50, 100, or even 500 calls per minute, depending on their type.) The Catalyst Center API rate limit is defined per API, so these limits can be adjusted for individual endpoints. When the limit is reached, the system returns an HTTP 429 (Too Many Requests) response.
In the expert configuration of the extension, there is an option that determines how the extension should handle such responses. The default setting is "fail fast," which means the extension does not retry the request. However, you can change this behavior so that the extension waits and retries the query later.
When data collection runs (for example, every 5 minutes), the extension sends multiple paged queries as quickly as possible to capture data for that specific timestamp. These queries are not spread evenly across the 5-minute interval, which can naturally create a peak load on the controller at the start of each collection cycle. If this peak load is the cause of the issues observed in the DNAC UI, you may try to reduce these peaks and distribute the load more evenly across the interval. Consider:
- Limiting (reducing) the number of queries for specific APIs. You can review the actual endpoints called by the library at Catalyst Center > Platform > Runtime Dashboard.
- Enabling rate-limit handling in the extension’s expert configuration.
- Increasing the client timeout.
With this approach, the controller will automatically pace its data delivery, while the extension will wait and retry to obtain the data later. However, it is important to configure the specific API limits carefully to ensure that all queries from one data collection period complete before the next data collection cycle begins (for example, within 5 minutes).
