Dynatrace Pattern Language
- Latest Dynatrace
- Explanation
Dynatrace Pattern Language (DPL) is a pattern language that allows you to describe patterns using matchers, where a matcher is a mini-pattern that matches a certain type of data. For example, INTEGER (or INT) matches integer numbers, and IPADDR matches IPv4 or IPv6 addresses. There are matchers available to handle all kinds of data types.
Usage
Use DPL to:
- Parse a record field into multiple output fields with the DQL parse command.
- Reshape incoming data for better understanding, analysis, or further processing in Log processing.
For instant feedback on the effectiveness and coverage of your patterns for your specific use case, use DPL Architect.
Pattern Structure
A written pattern is interpreted from left to right, ignoring extra whitespaces, line breaks, and comments in between. You can write the pattern describing an integer followed by a single space, IP address, and line break as the following one-liner:
INT ' ' IPADDR:ip EOL
Or you can write the same pattern in a more explanatory way:
/* this pattern expects an integer number and an IP addressseparated by single space in each line */INT //an integer' ' //followed by single spaceIPADDR:ip //followed by IPv4 or IPv6 address, extracted as a new field, `ip`EOL //line is terminated with line feed character
With DPL Architect, you can use preset patterns for the most popular technologies.
Matching vs Parsing
You don't necessarily need all data elements in the input data for analysis. For instance, field separators or end-of-record markers in a log line are useful only for parsing, but we don't need them when we run the queries. All matchers in a defined pattern must match, but only a subset of them may also extract (parse) data.
A matcher will extract data only when it has been assigned an export name - this is an arbitrary name of your choice, which becomes the name of the field you use in query statements.
In the following example, the pattern has:
- 11 matchers in total
- 4 matchers that are extracting data
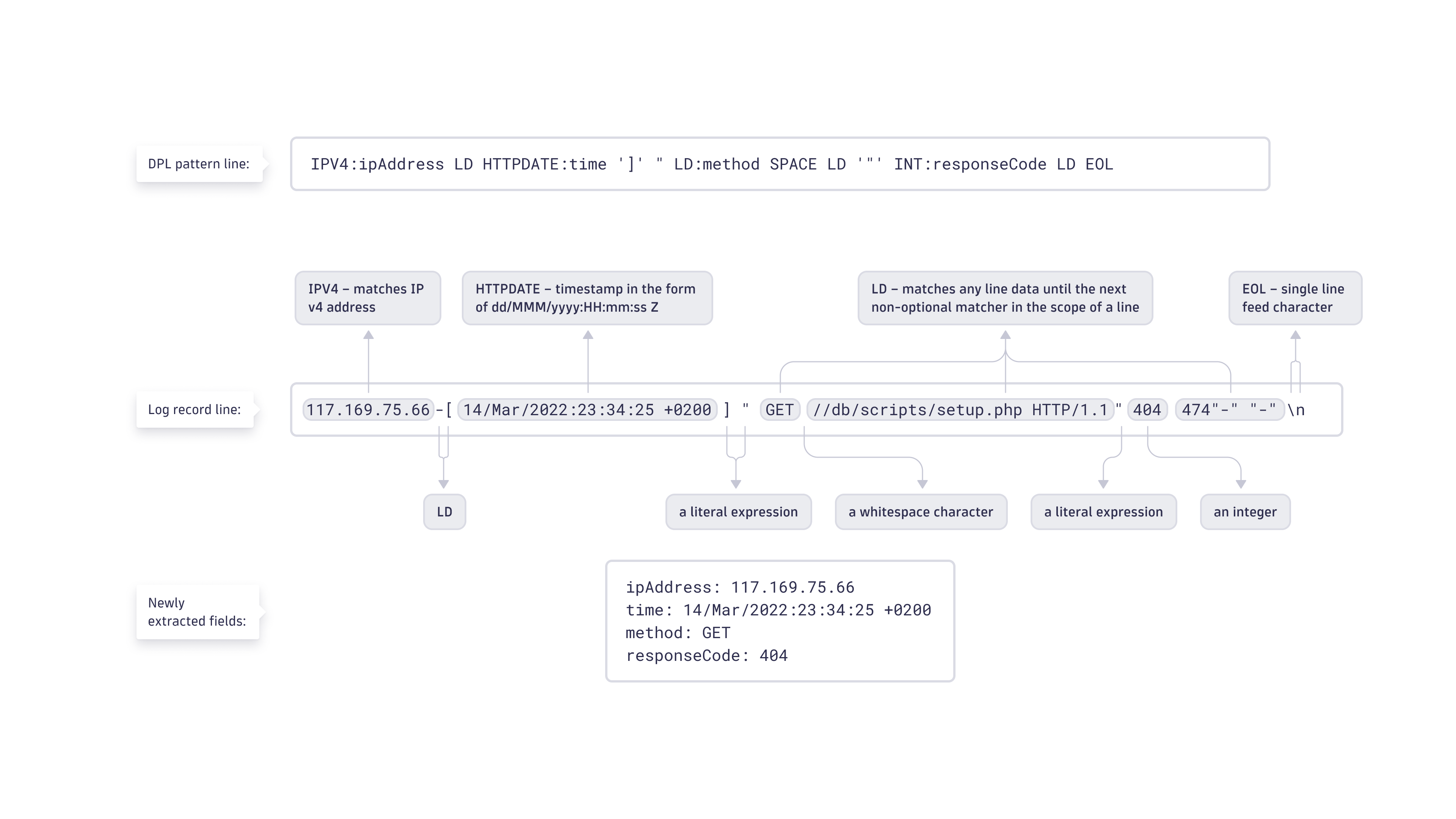
Matcher structure
A DPL pattern consists of one or more matcher expressions. They can be separated by whitespace or commas or newlines. For a handy reference guide to all matchers, see the DPL Grammar page.
Matcher types
In general, a matcher expression can be any of the following:
- Built-in matchers for many frequently used data types (numeric, time, network, and so on)
- literal expressions
- character groups, which are arbitrary set of characters to be matched (Regular Expression compatible)
- Reference to another pattern expression, to facilitate building complex patterns in a modular way
Matcher grouping
Matcher expressions can be grouped:
- sequence group—defines an ordered sequence of matchers
- alternatives group—defines a list of matchers to choose from
- array—to parse repeated data elements
- structure—to capture parsed data as composite type
- enum group—to match strings to numeric values
- JSON—to parse JSON structures
Matcher Expression Syntax
A matcher expression consists of the matcher itself and optional controlling elements (modifiers) arranged in the following order (from right to left, where square brackets indicate optional elements):
[lookaround] MATCHER_EXPR ['(' configuration ')'] [quantifier] [mod_optional] [':'export_name]
Note that whitespace characters and newlines are allowed between the elements. Placing elements in a different order (for instance, by placing mod_optional after the export_name) will cause a syntax error.
Matcher operators
Matcher expressions have operators:
-
Some matchers allow configuration specifying their behavior. For instance, a timestamp needs an expected format definition.
-
Most matchers and groupings can be added with a quantifier to tell the engine how many times it should try to match.
-
All matchers and groupings can be declared to be optional. If the element in the expected position is missing, the engine outputs NULL to the resultset and continues with the next matcher in the expression.
-
All matchers and groupings can be assigned an export name, which is the name of the field exposed to the query layer.
The sole purpose of pattern matching is to make data elements available for the query engine. However, not all matched elements are needed for queries (such as field separators in tabulated files), so an export name is a mechanism for the user to declare which data elements are exposed for queries (at the same time providing a name for the query fields). A matcher without an export name still does its job matching the pattern, but it's not visible in queries.
-
All matchers and groupings can "look around" (backward or forward), mainly to enable decision-making (conditional branching).
Example
The following is an example of step-by-step pattern matching.
Suppose we have a comma-separated record (terminated with the line feed character) with the following fields:
- order number - integer
- username - consisting of upper and lower case letters and numbers (but not a comma)
- ipv4 address of the user
1,alice,192.168.1.12,bob,10.6.24.183,mallory,192.168.1.3
This structure can be described by the following pattern expression:
INT:seq','LD:uname','IPADDR:user_ipEOL
where:
- line 1: integer matcher for the order number, visible in queries as 'seq' on line 2,4 constant string matcher for the field separator, not visible in queries
- line 3: line data matcher, visible in queries as 'uname'
- line 5: IP address matcher, visible in queries as 'user_ip'
- line 6: chargroup matcher for the line feed terminating the record
The pattern matching engine tries to apply the pattern by utilizing matchers in the order in which they were defined. The example above starts by trying to match INT:seq at the first byte of input data. This happens to be 1. As it is suitable for an integer type, it moves on to the next byte.
Next, the engine finds the byte to be a comma. This does not match with an integer, so the INT:seq matcher is completed by converting 1 to an integer and the next matcher in the pattern is selected: ','. The engine tries it for a current position of data and finds a match.
So the data pointer is moved on to the next byte (pointing to the first letter of bob). As the constant string matcher contained just one character, the matcher is considered complete and the engine takes the next one in the pattern: [a-zA-Z0-9]*:uname. The quantifier * forces [a-zA-Z0-9]*:uname to consume a variable number of bytes (zero or more), so it keeps matching until it finds a byte not matching its defined characters. This happens at the second comma (just after bob), where the engine considers the [a-zA-Z0-9]*:uname matcher complete and takes the next one: ','. Again, it tries to match it to the byte at the current position and succeeds.
The data pointer is moved to the next byte, pointing to the beginning of 192.168.1.1. As ',' is completed, the engine takes IPV4ADDR:user_ip. Trying it from the current position, a match is found and the data pointer is moved forward 11 bytes, now pointing to a newline character. The engine finds a match for it using the last matcher in the pattern: [\n].
Now the data pointer is advanced to the next byte, the pattern iterator is reset, and the cycle continues with trying the first matcher of the pattern against the currently pointed data. This continues until the end of the input data.
If the engine encounters data for which it is unable to find a match, it resets the pattern iterator, marks this byte as unmatched, and moves on to the next byte. This continues until a match is found or there is no more data. Eventually, the following structured data is the output:
| seq | uname | user_ip |
|---|---|---|
|
|
|
|
|
|
|
|
|