Alert on common Kubernetes/OpenShift issues
- Dynatrace Classic
- 18-min read
Dynatrace version 1.254+
ActiveGate version 1.253+
To alert on common Kubernetes platform issues, follow the instructions below.
Configure
There are three ways to configure alerts for common Kubernetes/OpenShift issues.
Configuring an alert on a different level is only intended to simplify the configuration of multiple entities at once. It does not change the behavior of an alert.
For example, enabling a workload CPU usage saturation alert will still evaluate and raise problems for each Kubernetes workload separately, even if it has been configured on the Kubernetes cluster level.
For further details on the settings hierarchy, see Settings documentation.
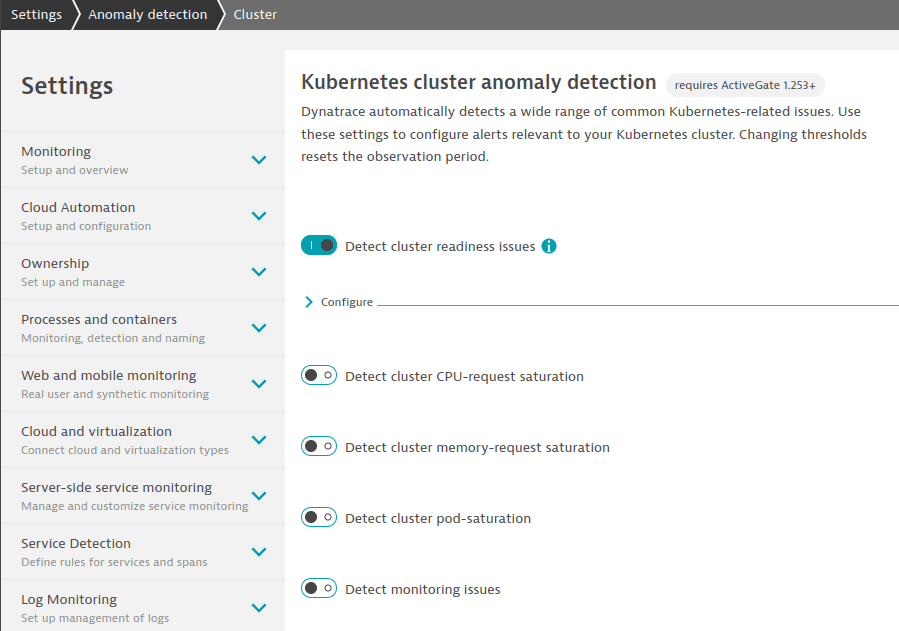
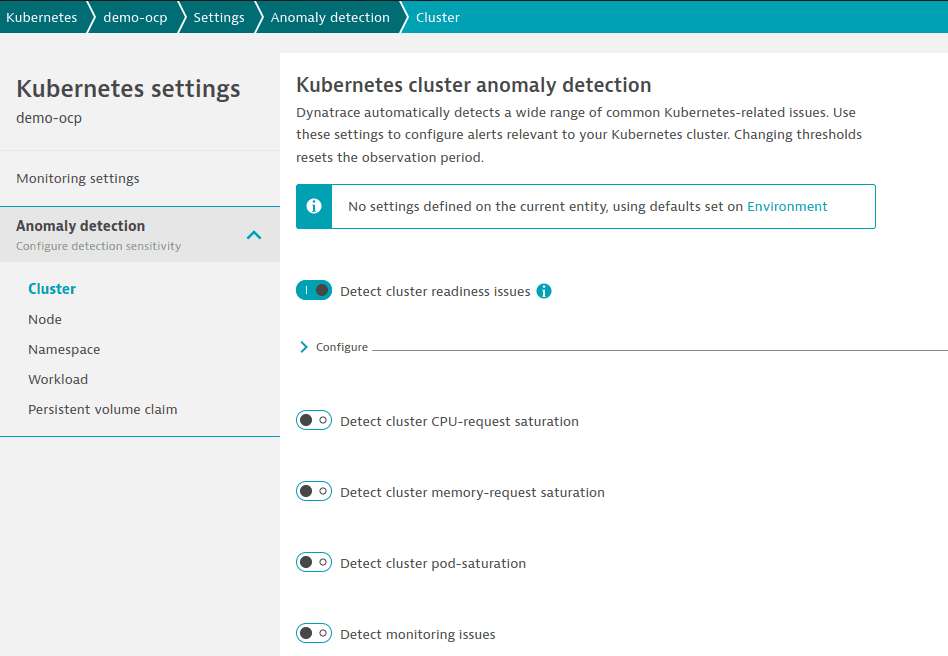
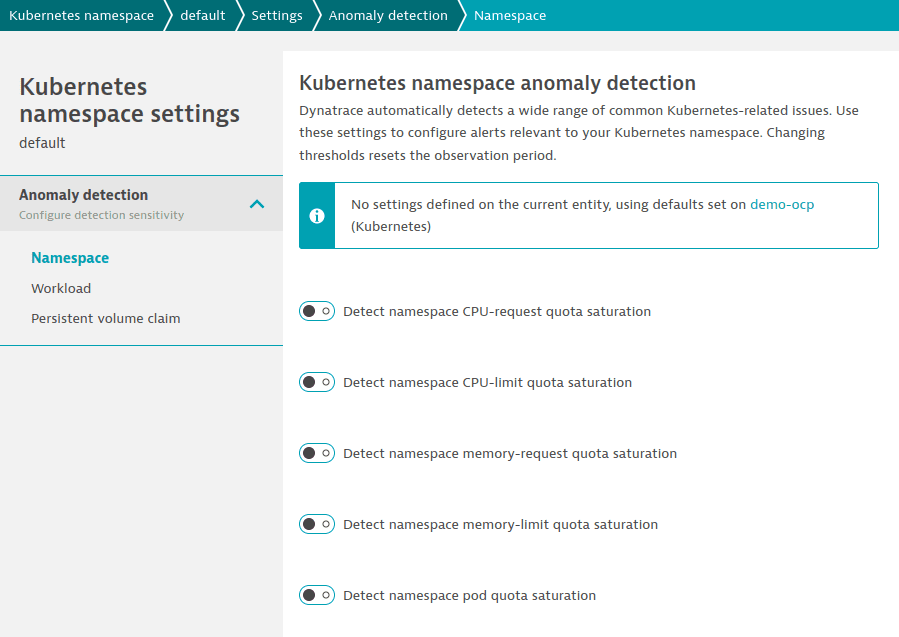
- Settings apply to all clusters, nodes, namespaces, or workloads in the Kubernetes/OpenShift tenant.
- To configure settings, go to Settings > Anomaly detection and select any page under the Kubernetes section.
Example:
View alerts
Manually closed problems will show up again after 60 days if their root cause remains unresolved.
You can view alerts
-
On the Problems page.
Example problem:
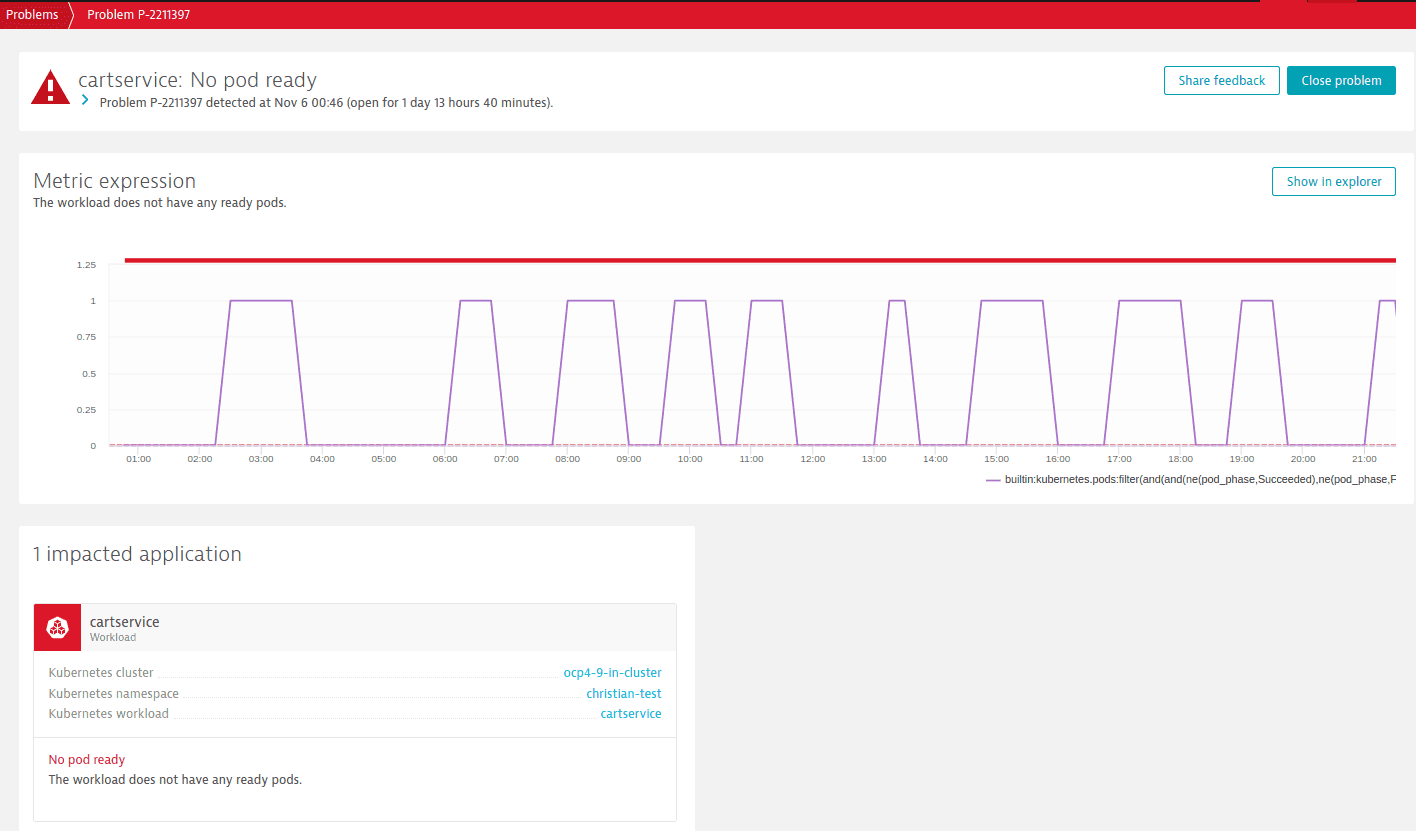 k8s-alert-view-in-problems
k8s-alert-view-in-problems -
In the Events section of a cluster details page.
Example event:
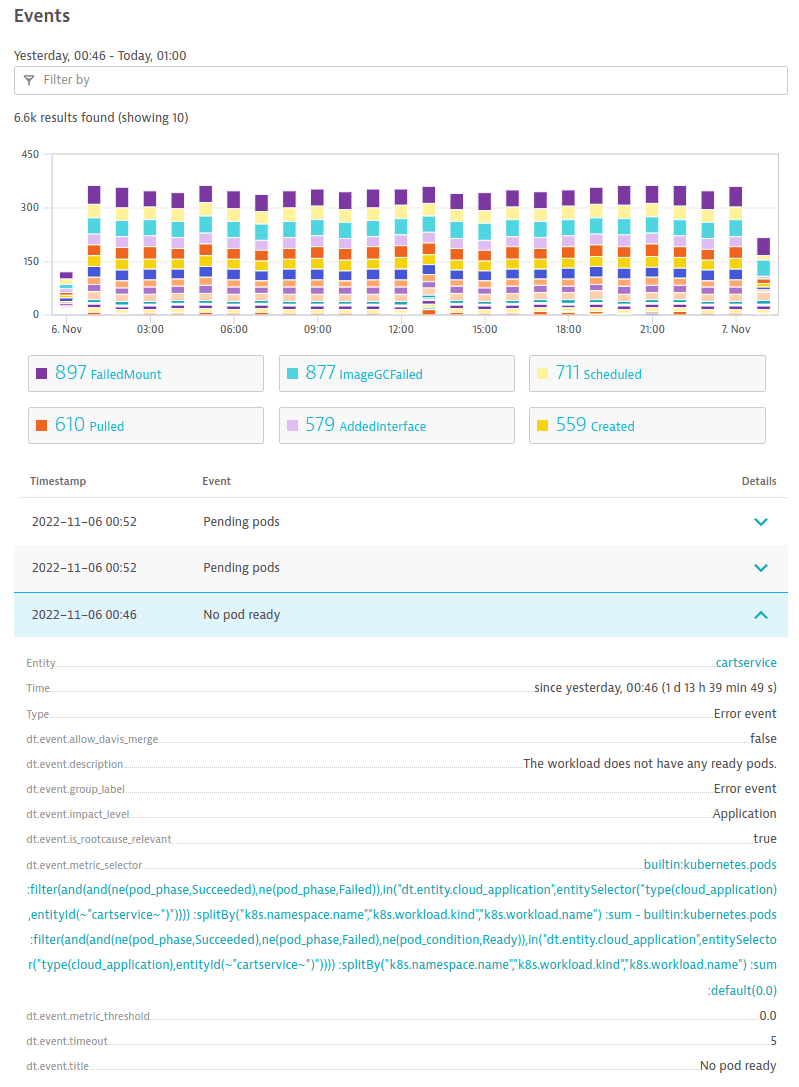 k8s-alert-view-in-events
k8s-alert-view-in-eventsSelect the event to navigate to Data Explorer for more information about the metric that generated the event.
Available alerts
See below for a list of available alerts.
The following alerts are not reclassified as warning signals when the updated classification is enabled.
- Detect cluster readiness issues
- Detect stuck deployments
- Detect workloads without ready pods
- Detect pod backoff events
Cluster alerts
| Alert name | Dynatrace version | Problem type | Problem title | Problem description | De-alerts after | Calculation | Supported in |
|---|---|---|---|---|---|---|---|
1.254 | Resource | CPU-request saturation on cluster | CPU-request saturation exceeds the specified threshold. | 10 minutes | Node CPU requests / Node CPU allocatable | Kubernetes Classic, Kubernetes app | |
1.254 | Resource | Memory-request saturation on cluster | Memory-request saturation exceeds the specified threshold. | 10 minutes | Node memory requests / Node memory allocatable | Kubernetes Classic, Kubernetes app | |
1.258 | Resource | Pod saturation on cluster | Cluster pod-saturation exceeds the specified threshold. | 10 minutes | Sum of ready pods / Sum of allocatable pods | Kubernetes Classic, Kubernetes app | |
1.254 | Availability | Cluster not ready | Readyz endpoint indicates that this cluster is not ready. | 10 minutes | Cluster readyz metric | Kubernetes Classic, Kubernetes app | |
1.258 | Availability | Monitoring not available | Dynatrace API monitoring is not available. | 10 minutes | Kubernetes Classic, Kubernetes app |
Cluster metric and DQL expressions
Detect cluster CPU-request saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect cluster memory-request saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect cluster pod-saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect cluster readiness issues
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect monitoring issues
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Default alerts for new tenants
| Alert | Setting | Value |
|---|---|---|
Readiness Issues | sample period in minutes | 3 |
Readiness Issues | observation period in minutes | 5 |
Monitoring Issues | sample period in minutes | 15 |
Monitoring Issues | observation period in minutes | 30 |
Namespace alerts
| Alert name | Dynatrace version | Problem type | Problem title | Problem description | De-alerts after | Calculation | Supported in |
|---|---|---|---|---|---|---|---|
1.254 | Resource | CPU-limit quota saturation | CPU-limit quota saturation exceeds the specified threshold. | 10 minutes | Sum of resource quota CPU used / Sum of resource quota CPU limits | Kubernetes Classic, Kubernetes app | |
1.254 | Resource | CPU-request quota saturation | CPU-request quota saturation exceeds the specified threshold. | 10 minutes | Sum of resource quota CPU used / Sum of resource quota CPU requests | Kubernetes Classic, Kubernetes app | |
1.254 | Resource | Memory-limit quota saturation | Memory-limit quota saturation exceeds the specified threshold. | 10 minutes | Sum of resource quota memory used / Sum of resource quota memory limits | Kubernetes Classic, Kubernetes app | |
1.254 | Resource | Memory-request quota saturation | Memory-request quota saturation exceeds the specified threshold. | 10 minutes | Sum of resource quota memory used / Sum of resource quota memory requests | Kubernetes Classic, Kubernetes app | |
1.254 | Resource | Pod quota saturation | Pod quota saturation exceeds the specified threshold. | 10 minutes | Sum of resource quota pods used / Sum of resource quota pods limit | Kubernetes Classic, Kubernetes app |
Namespace metric and DQL expressions
Detect namespace CPU-limit quota saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect namespace CPU-request quota saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect namespace memory-limit quota saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect namespace memory-request quota saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect namespace pod quota saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Node alerts
| Alert name | Dynatrace version | Problem type | Problem title | Problem description | De-alerts after | Calculation | Supported in |
|---|---|---|---|---|---|---|---|
1.254 | Resource | CPU-request saturation on node | CPU-request saturation exceeds the specified threshold. | 10 minutes | Sum of node CPU requests / Sum of node CPU allocatable | Kubernetes Classic, Kubernetes app | |
1.254 | Resource | Memory-request saturation on node | Memory-request saturation exceeds the specified threshold. | 10 minutes | Sum of node memory requests / Sum of node memory allocatable | Kubernetes Classic, Kubernetes app | |
1.254 | Resource | Pod saturation on node | Pod saturation exceeds the specified threshold. | 10 minutes | Sum of running pods on node / Node pod limit | Kubernetes Classic, Kubernetes app | |
1.254 | Availability | Node not ready | Node is not ready. | 10 minutes | Node condition metric filtered by 'not ready' | Kubernetes Classic, Kubernetes app | |
1.264 | Error | Problematic node condition | Node has one or more problematic conditions out of the following: | 10 minutes | Nodes condition metric | Kubernetes Classic, Kubernetes app |
Node metric and DQL expressions
Detect node CPU-request saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect node memory-request saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect node pod-saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect node readiness issues
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect problematic node conditions
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Default alerts for new tenants
| Alert | Setting | Value |
|---|---|---|
Readiness Issues | Readiness Issues | sample period in minutes |
3 | observation period in minutes | 5 |
Node Problematic Condition | Node Problematic Condition | sample period in minutes |
3 | observation period in minutes | 5 |
Persistent volume claims alerts
| Alert name | Dynatrace version | Problem type | Problem title | Problem description | De-alerts after | Calculation | Supported in |
|---|---|---|---|---|---|---|---|
1.262 | Resource | Kubernetes PVC: Low disk space % | Available disk space for a persistent volume claim is below the threshold. | 10 minutes | Volume stats available bytes / Volume stats capacity bytes | Kubernetes Classic, Kubernetes app | |
1.262 | Resource | Kubernetes PVC: Low disk space | Available disk space for a persistent volume claim is below the threshold. | 10 minutes | Kubelet volume stats available bytes metric | Kubernetes Classic, Kubernetes app |
Persistent volume claims metric and DQL expressions
Detect low disk space (%)
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect low disk space (MiB)
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Workload alerts
| Alert name | Dynatrace version | Problem type | Problem title | Problem description | De-alerts after | Calculation | Supported in |
|---|---|---|---|---|---|---|---|
1.264 | Resource | CPU usage close to limits | The CPU usage exceeds the threshold in terms of the defined CPU limit. | 10 minutes | Sum of workload CPU usage / Sum of workload CPU limits | Kubernetes Classic, Kubernetes app | |
1.254 | Error | Container restarts | Observed container restarts exceed the specified threshold. | 15 minutes | Container restarts metric | Kubernetes Classic, Kubernetes app | |
1.264 | Resource | High CPU throttling | The CPU throttling to limits ratio exceeds the specified threshold. | 10 minutes | Sum of workload CPU throttled / Sum of workload CPU limits | Kubernetes Classic, Kubernetes app | |
1.268 | Error | Job failure event | Events with reason 'BackoffLimitExceeded', 'DeadlineExceeded', or 'PodFailurePolicy' have been detected. | 60 minutes | Event metric filtered by reason and workload kind | Kubernetes Classic, Kubernetes app | |
1.264 | Resource | Memory usage close to limits | The memory usage (working set memory) exceeds the threshold in terms of the defined memory limit. | 10 minutes | Sum of workload working set memory / Sum of workload memory limits | Kubernetes Classic, Kubernetes app | |
1.268 | Error | Out-of-memory kills | Out-of-memory kills have been observed for pods of this workload. | 15 minutes | Out-of-memory kills metric | Kubernetes Classic, Kubernetes app | |
1.268 | Error | Backoff event | Events with reason 'BackOff' have been detected for pods of this workload. Check for pods with status 'ImagePullBackOff' or 'CrashLoopBackOff'. | 15 minutes | Event metric filtered by reason | Kubernetes Classic, Kubernetes app | |
1.268 | Error | Pod eviction event | Events with reason 'Evicted' have been detected for pods of this workload. | 60 minutes | Event metric filtered by reason | Kubernetes Classic, Kubernetes app | |
1.268 | Error | Preemption event | Events with reasons 'Preempted' or 'Preempting' have been detected for pods of this workload. | 60 minutes | Event metric filtered by reason | Kubernetes Classic, Kubernetes app | |
1.254 | Resource | Pods stuck in pending | Workload has pending pods. | 10 minutes | Pods metric filtered by phase 'Pending' | Kubernetes Classic, Kubernetes app | |
1.260 | Resource | Pods stuck in terminating | Workload has pods stuck in terminating. | 10 minutes | Pods metric filtered by status 'Terminating' | Kubernetes Classic, Kubernetes app | |
1.260 | Error | Deployment stuck | Deployment is stuck and therefore is no longer progressing. | 10 minutes | Workload condition metric filtered by 'not progressing' | Kubernetes Classic, Kubernetes app | |
1.258 | Error | Not all pods ready | Workload has pods that are not ready. | 10 minutes | Sum of all pending or running pods − Sum of ready pending or running pods. Pods of Jobs and CronJob are excluded. | Kubernetes Classic, Kubernetes app | |
1.254 | Error | No pod ready | Workload does not have any ready pods. | 10 minutes | Sum of all pending or running pods − Sum of non-ready pending or running pods. Pods of Jobs and CronJob are excluded. | Kubernetes Classic, Kubernetes app |
Workload metric and DQL expressions
Detect CPU usage saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect container restarts
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect high CPU throttling
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect job failure events
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect memory usage saturation
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect out-of-memory kills
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect pod backoff events
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect pod eviction events
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect pod preemption events
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect pods stuck in pending
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect pods stuck in terminating
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect stuck deployments
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect workloads with non-ready pods
The following expression returns the number of pending and running pods in the non-ready condition. Pods of Jobs and CronJobs are excluded.
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Detect workloads without ready pods
The following expression returns the number of pending and running pods in the ready condition. Pods of Jobs and CronJobs are excluded.
| Type | Expression |
|---|---|
Metric expression |
|
DQL |
|
Default alerts for new tenants
| Alert | Setting | Value |
|---|---|---|
Container Restarts | threshold | 1 |
Container Restarts | sample period in minutes | 3 |
Container Restarts | observation period in minutes | 5 |
Deployment Stuck | sample period in minutes | 3 |
Deployment Stuck | observation period in minutes | 5 |
Pending Pods | threshold | 1 |
Pending Pods | sample period in minutes | 10 |
Pending Pods | observation period in minutes | 15 |
Pod Stuck In Terminating | sample period in minutes | 10 |
Pod Stuck In Terminating | observation period in minutes | 15 |
Workload Without Ready Pods | sample period in minutes | 10 |
Workload Without Ready Pods | observation period in minutes | 15 |
Oom Kills | alert | always |
Job Failure Events | alert | always |
Pod Backoff Events | alert | always |
Pod Eviction Events | alert | always |
Pod Preemption Events | alert | always |