Predict and autoscale Kubernetes workloads
The Davis CoPilot features mentioned below are still a Preview release. These will be made available to customers through the Preview in coming weeks.
Are you struggling to keep up with the demands of dynamic Kubernetes environments? Manual scaling is not only time-consuming and reactive, but also prone to errors.
You can harness the power of Dynatrace Automation and Davis AI to predict resource bottlenecks and automatically open pull requests to scale applications. This proactive approach minimizes downtime, helps optimize resource utilization, and ensures your applications perform at their best.
You achieve this by combining predictive AI to forecast resource limitations with generative AI to suggest modifying your Kubernetes manifests on Git (GitHub and GitLab) by creating pull requests for scaling adjustments.
The following animation shows the end-to-end workflow. As an engineer, you can enable a deployment for predictive scaling recommendations through annotations. Workflows will then predict resource consumption for those enabled deployments and create a pull request to support the engineer in making the proper adjustments. Using a combination of Davis AI and Workflows is true AI-assisted predictive scaling, as code integrates well into the Git workflow.

What will you learn
The goal of this tutorial is to teach you how to annotate your deployments and build two interconnecting workflows that will identify Kubernetes workloads that should be scaled. It will also create pull requests, including the suggested new limits, as a self-service for the engineering teams.
In this tutorial, you'll learn how to
- Annotate your Kubernetes Deployments
- Create two Dynatrace workflows: one for prediction, one for opening a pull request
Alternatively, follow our Observability Lab: Predictive Auto-Scaling for Kubernetes workloads. This lab has a GitHub Codespaces configuration that allows you to fully automate this use case.
Before you begin
Prerequisites
- Installed AI in Workflows - Predictive Maintenance of Cloud Disks.
- Set up Kubernetes Automation.
- Access to your GitHub account, a GitHub Repository, and a GitHub Personal Access Token (PAT).
- Access to your Kubernetes environment that is monitored with Dynatrace.
- A Kubernetes Deployment that you can annotate to enable predictive scaling pull requests.
- A Dynatrace Platform API token to execute Davis CoPilot.
- Set up GitHub for Workflows
Annotate your Kubernetes Deployments
The workflows that provide the predictive scaling suggestions will only operate on Kubernetes Deployments annotated with use-case–specific metadata. You need to add the following annotations to your Deployment.
Annotation
Value
Comment
predictive-kubernetes-scaling.observability-labs.dynatrace.com/enabled
true or false
true to enable for this workload.
predictive-kubernetes-scaling.observability-labs.dynatrace.com/managed-by-repo:
yourgithub/yourreponame
Reference to the target repo.
predictive-kubernetes-scaling.observability-labs.dynatrace.com/uuid
For example, 4bc1299a-58ae-4c19-9533-b19c1b8ca57f
Any unique GUID in your repo.
predictive-kubernetes-scaling.observability-labs.dynatrace.com/target-utilization
For example, 80-90.
Target utilization.
predictive-kubernetes-scaling.observability-labs.dynatrace.com/target-cpu-utilization
For example, 80-90.
Target CPU utilization.
predictive-kubernetes-scaling.observability-labs.dynatrace.com/target-memory-utilization
For example, 80-90.
Target memory utilization.
predictive-kubernetes-scaling.observability-labs.dynatrace.com/scale-down
true
true will also scale down and not just up.
For a complete example, see the horizontal scaling and vertical scaling deployment example from the Observability Lab GitHub Tutorial.
Steps
You're going to create two workflows.
- The first workflow uses Davis AI to predict which Kubernetes workloads need scaling based on predicated memory and CPU utilization.
- The second workflow uses Davis AI CoPilot to create a pull request using the predicted values suggested by Davis AI CoPilot to update the manifest files.
While we leverage Davis AI capabilities for prediction and updating manifest, you, as the user, decide whether to commit the suggested changes as part of the pull request.
 Predict Kubernetes resources usage workflow
Predict Kubernetes resources usage workflow
-
On the Workflows overview page, select
 Workflow.
Workflow. -
Select the default title Untitled Workflow, and copy and paste the workflow title Predict Resource Usage.
-
In the Select trigger section, select the trigger type On demand.
We recommend using a Time interval trigger in a real-life scenario.
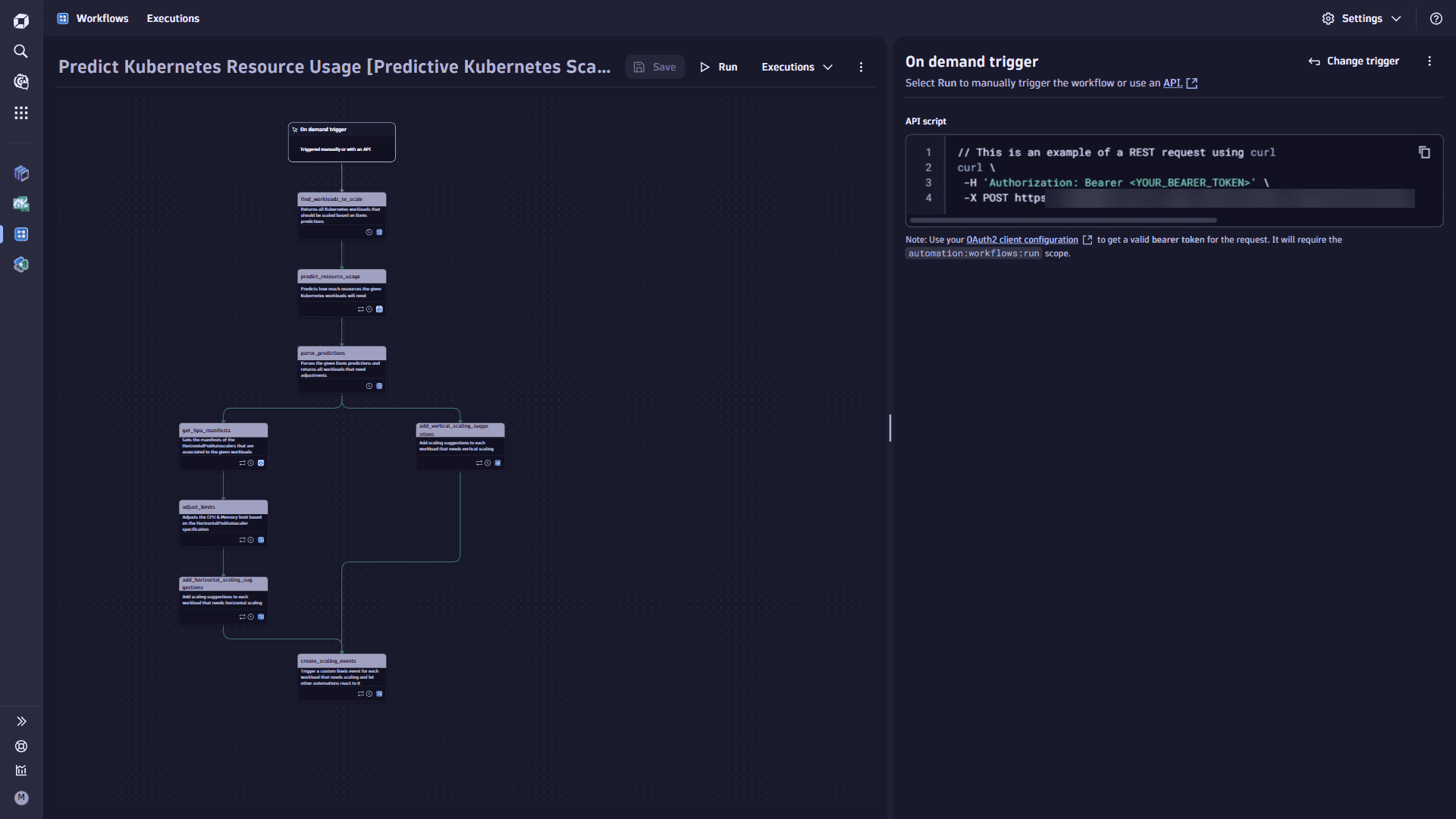
In the first workflow task, you identify the Kubernetes workloads your automation workflow will manage for scaling. While theoretically, you could include all workloads, that might lead to lengthy workflow execution times. Instead, you focus on Kubernetes workloads where the annotation
predictive-kubernetes-scaling.observability-labs.dynatrace.com/enabledis set totrue. This annotation is a good best practice, allowing developers to opt-in for predictive scaling recommendations. -
Add the
find_workloads_to_scaletask.-
Select
Add task on the trigger node. This task adjusts the CPU and Memory limit based on the HorizontalPodAutoscalerspecification. -
In the Choose action section, select the Execute DQL query action type. The task details pane on the right shows the task inputs.
-
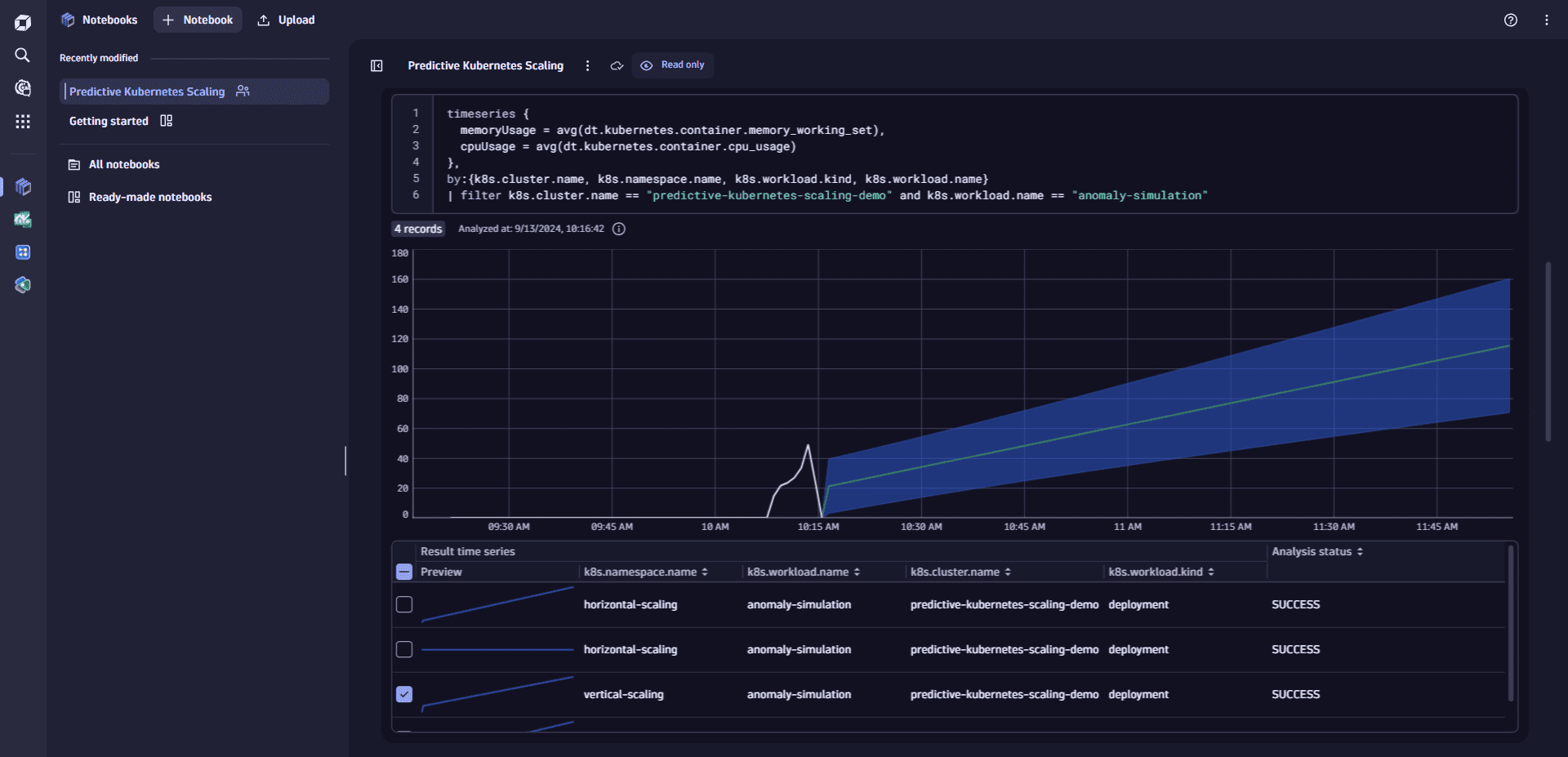
In the Input tab, copy the following DQL query and paste it into the DQL query box.
fetch dt.entity.cloud_application, from:now() - 5m, to:now()| filter kubernetesAnnotations[`predictive-kubernetes-scaling.observability-labs.dynatrace.com/enabled`] == "true"| fields clusterId = clustered_by[`dt.entity.kubernetes_cluster`], namespace = namespaceName, name = entity.name, type = arrayFirst(cloudApplicationDeploymentTypes), annotations = kubernetesAnnotations| join [ fetch dt.entity.kubernetes_cluster ],on: { left[clusterId] == right[id] },fields: { clusterName = entity.name }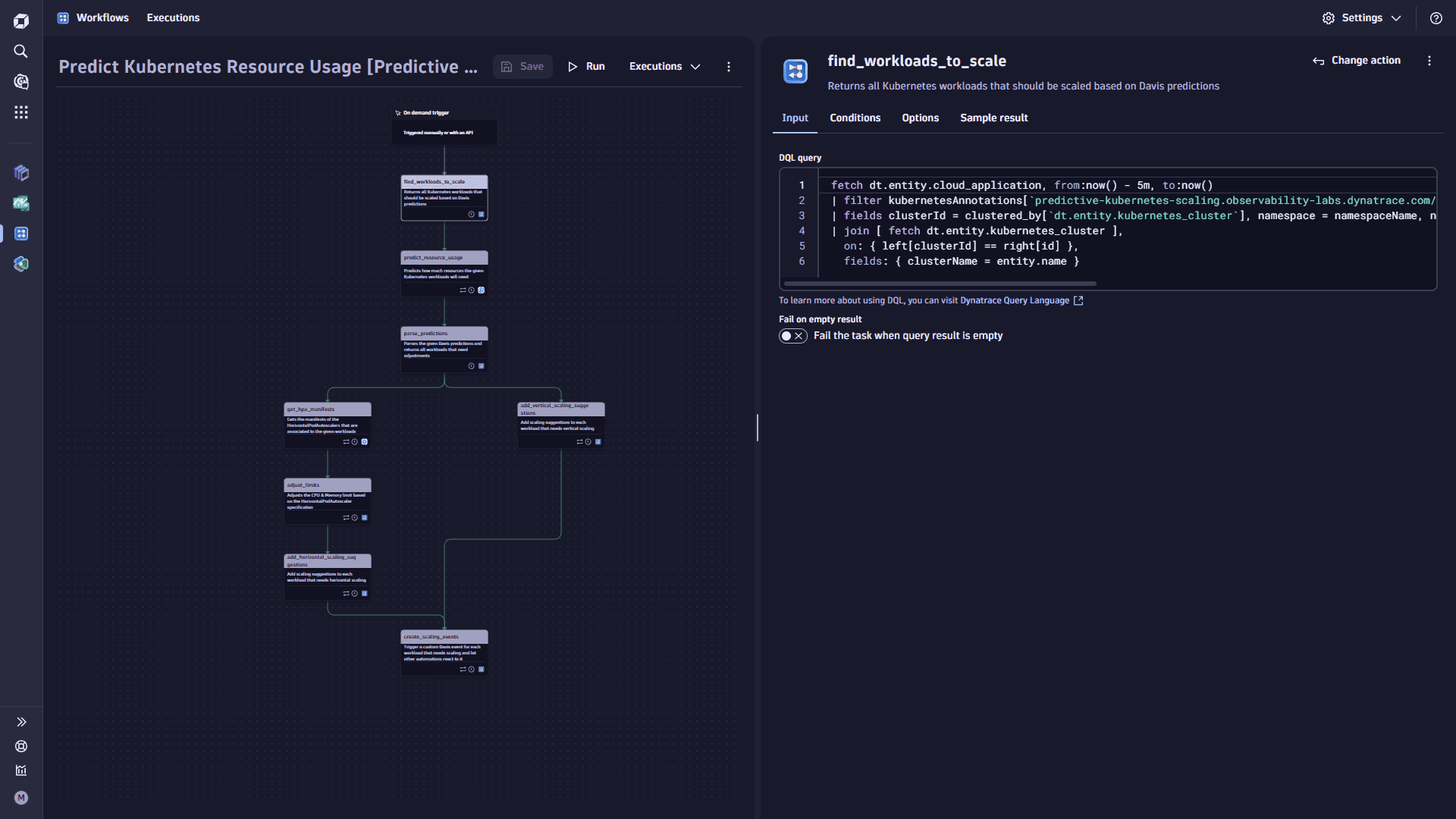
Once you identify your target workloads, you'll use Dynatrace Davis AI to forecast their CPU and memory consumption. This will help you determine whether they will likely exceed their defined Kubernetes resource limits.
-
-
Add the
predict_resource_usagetask.-
Select
Add task on the task node. This task loops over all workloads that the predict_resource_usagetask has found and uses Davis AI to predict how much of each resource a pod will need. -
In the Choose action section, select the Analyze with Davis action type.
-
In the Input tab, set the Analyzers to Generic forecast analysis.
- Set the Start time to now-1h. We recommend adjusting the time interval to your user environment in a real-life scenario.
- Set the End time to now.
- Leave Resolve data as it is.
-
Copy the following DQL query and paste it into the Time series data box.
timeseries {memoryUsage = avg(dt.kubernetes.container.memory_working_set),memoryLimits = max(dt.kubernetes.container.limits_memory),cpuUsage = avg(dt.kubernetes.container.cpu_usage),cpuLimits = max(dt.kubernetes.container.limits_cpu)},by:{k8s.cluster.name, k8s.namespace.name, k8s.workload.kind, k8s.workload.name}| filter k8s.cluster.name == "{{ _.workload.clusterName }}" and k8s.namespace.name == "{{ _.workload.namespace }}" and k8s.workload.name == "{{ _.workload.name }}"| fieldscluster = k8s.cluster.name,clusterId = "{{ _.workload.clusterId }}",namespace = k8s.namespace.name,kind = k8s.workload.kind,name = k8s.workload.name,annotations = "{{ _.workload.annotations }}",memoryLimit = arrayLast(memoryLimits),cpuLimit = arrayLast(cpuLimits),timeframe,interval,memoryUsage,cpuUsage -
On the Options tab for the Loop task, set the Item variable name to workload.
-
In the List box, copy the following:
{{ result("find_workloads_to_scale")["records"] }}
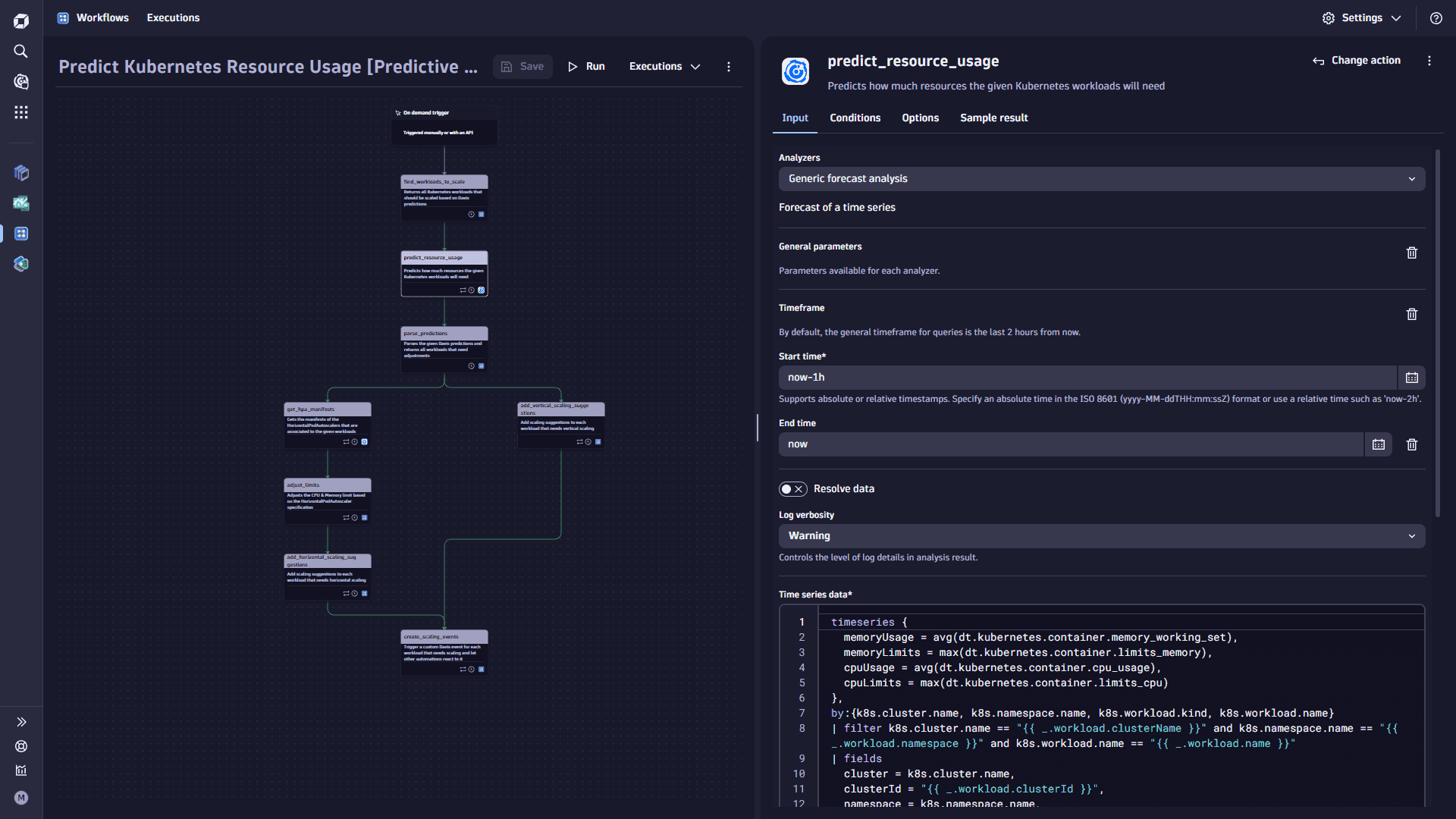
Now that you have the predicted CPU and memory utilization, limits, and time, you can parse and calculate the recommended changes for the workloads. This is done in its task, which iterates through all the predictions and considers whether the workloads are marked for horizontal or vertical scaling.
-
-
Add the
parse_predictionstask.-
Select
Add task on the task node. This task gets a list of all prediction results as input and then converts/parses those results into a list for the following workflow tasks. -
In the Choose action section, select the Run JavaScrip action type.
-
On the Input tab, copy the following code and paste it into the Source code box:
import {execution} from '@dynatrace-sdk/automation-utils';export default async function ({execution\_id}) {const ex = await execution(execution\_id);const predictions = await ex.result('predict\_resource\_usage');let workloads = \[];predictions.forEach(prediction => {prediction.result.output.filter(output => output.analysisStatus == 'OK' && output.forecastQualityAssessment == 'VALID').forEach(output => {const query = JSON.parse(output.analyzedTimeSeriesQuery.expression);const result = output.timeSeriesDataWithPredictions.records\[0];let resource = query.timeSeriesData.records\[0].cpuUsage ? 'cpu' : 'memory';const highestPrediction = getHighestPrediction(result.timeframe, result.interval, resource, result\['dt.davis.forecast:upper'])workloads = addOrUpdateWorkload(workloads, result, highestPrediction);})});return workloads;}const getHighestPrediction = (timeframe, interval, resource, values) => {const highestValue = Math.max(...values);const index = values.indexOf(highestValue);const startTime = new Date(timeframe.start).getTime();const intervalInMs = interval / 1000000;return {resource,value: highestValue,date: new Date(startTime + (index \* intervalInMs)),predictedUntil: new Date(timeframe.end)}}const addOrUpdateWorkload = (workloads, result, prediction) => {const existingWorkload = workloads.find(p =>p.cluster === result.cluster&& p.namespace === result.namespace&& p.kind === result.kind&& p.name === result.name);if (existingWorkload) {existingWorkload.predictions.push(prediction);return workloads;}const annotations = JSON.parse(result.annotations.replaceAll(`'`, `"`));const hpa = annotations\['predictive-kubernetes-scaling.observability-labs.dynatrace.com/managed-by-hpa'];workloads.push({cluster: result.cluster,clusterId: result.clusterId,namespace: result.namespace,kind: result.kind,name: result.name,repository: annotations\['predictive-kubernetes-scaling.observability-labs.dynatrace.com/managed-by-repo'],uuid: annotations\['predictive-kubernetes-scaling.observability-labs.dynatrace.com/uuid'],predictions: \[prediction],scalingConfig: {horizontalScaling: {enabled: hpa ? true : false,hpa: {name: hpa}},limits: {memory: result.memoryLimit,cpu: result.cpuLimit,},targetUtilization: getTargetUtilization(annotations),scaleDown: annotations\['predictive-kubernetes-scaling.observability-labs.dynatrace.com/scale-down'] ?? 'true' === 'true',}})return workloads;}const getTargetUtilization = (annotations) => {const defaultRange = annotations\['predictive-kubernetes-scaling.observability-labs.dynatrace.com/target-utilization'] ?? '80-90';const targetUtilization = {};const cpuRange = annotations\['predictive-kubernetes-scaling.observability-labs.dynatrace.com/target-cpu-utilization'] ?? defaultRange;targetUtilization.cpu = getTargetUtilizationFromRange(cpuRange);const memoryRange = annotations\['predictive-kubernetes-scaling.observability-labs.dynatrace.com/target-memory-utilization'] ?? defaultRange;targetUtilization.memory = getTargetUtilizationFromRange(memoryRange);return targetUtilization;}const getTargetUtilizationFromRange = (range) => {const \[min, max] = range.split('-').map(s => parseInt(s) / 100);const point = (min + max) / 2;return {min, max, point};}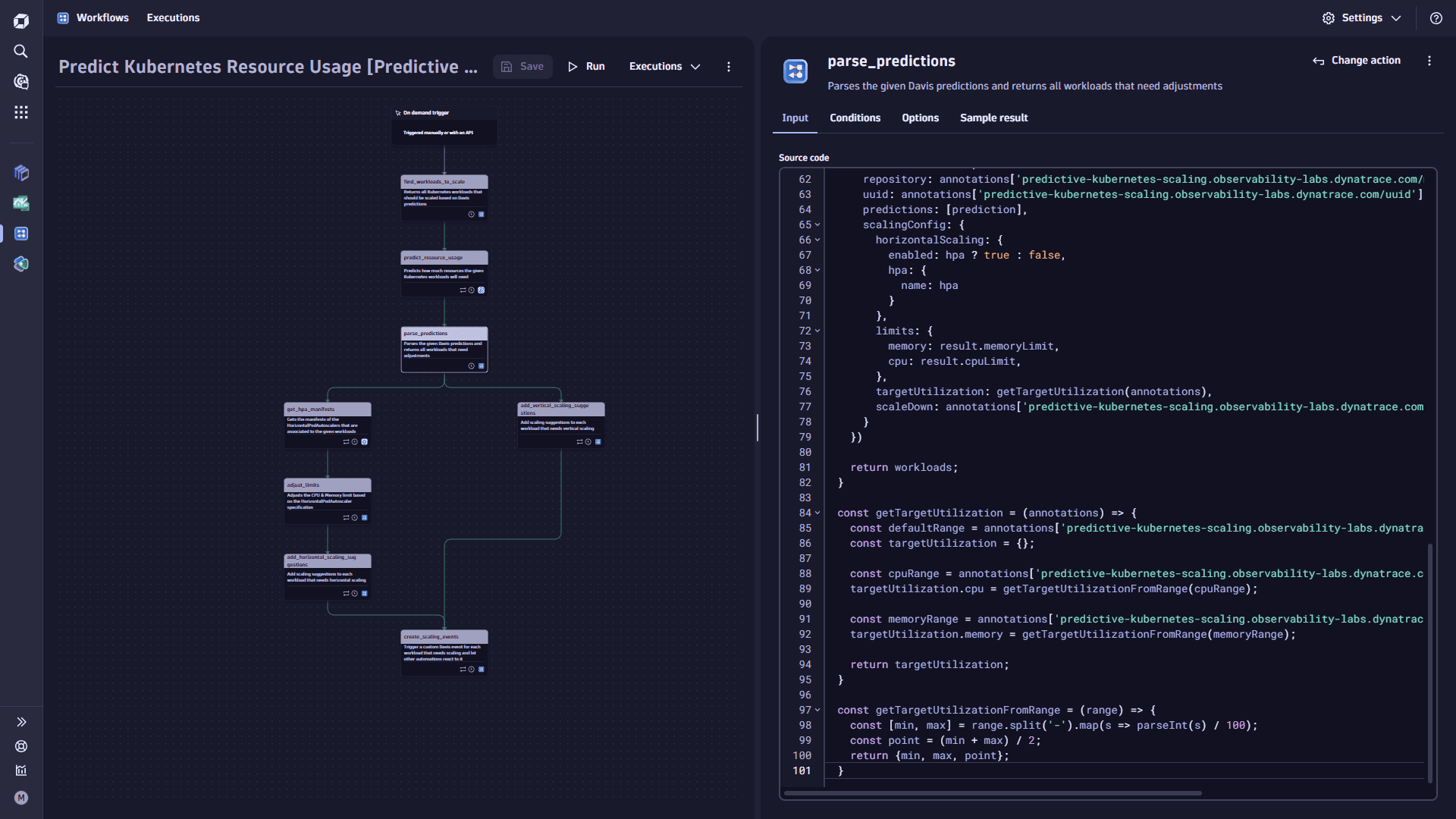
-
-
After running the Predict Kubernetes resource usage workflow, you have a list of workloads with forecasts in a format that's suitable as input for the following workflow. Next, you need to check if the highest predicted value of the resource usage exceeds or stays below (if downscaling is enabled) the configured CPU or Memory range. If yes, generate a Davis AI event that contains a prompt that can be used to adjust the manifest.
This workflow has two branches: vertical and horizontal scaling. In these branches, you evaluate whether scaling is necessary. If required, a Davis AI event is created for both branches.
First, you build the vertical scaling branch. It contains a task called
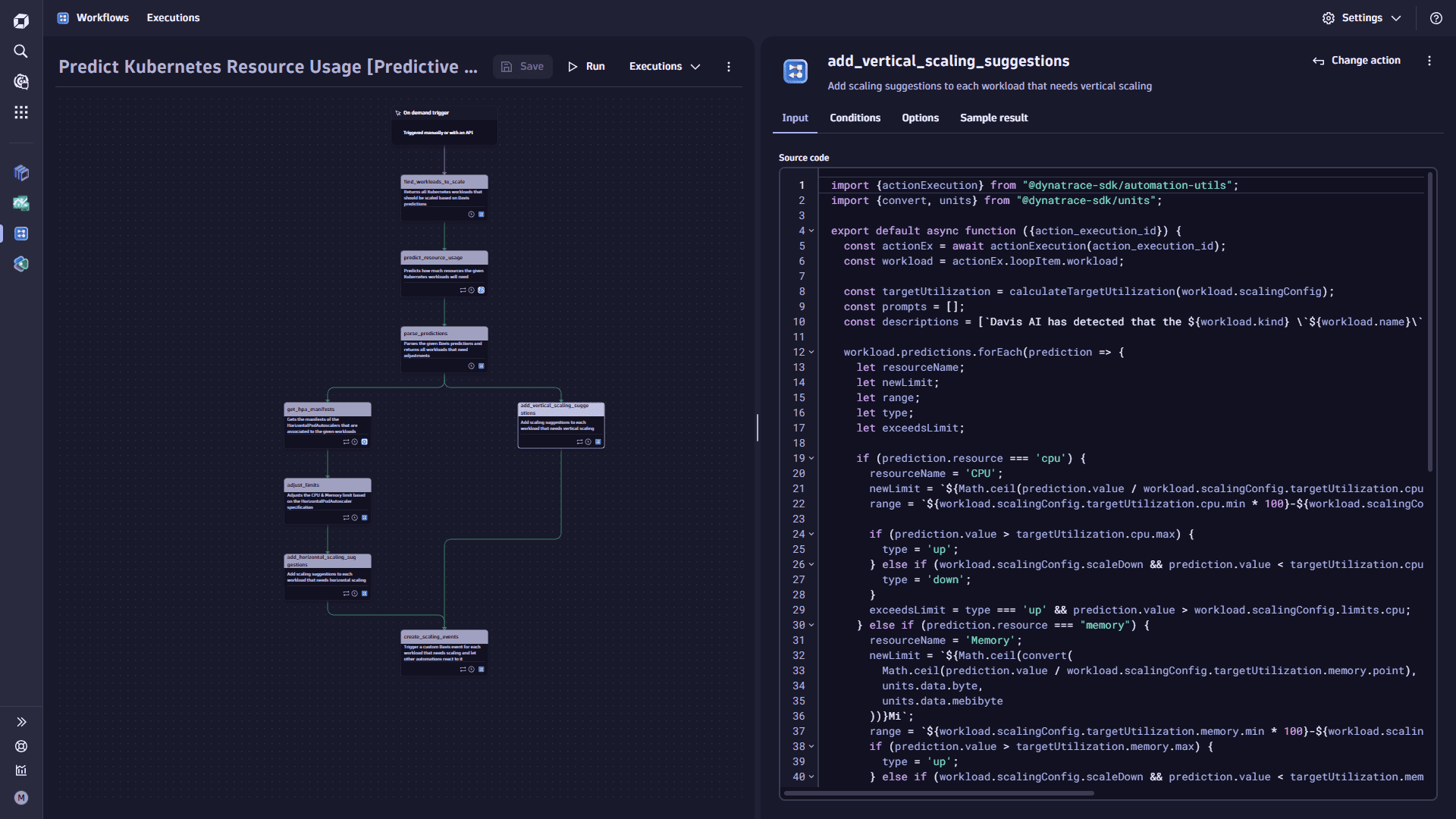
add_vertical_scaling_suggestions, where you compare the workload limits with the predicted values. Secondly, you build the horizontal scaling branch. This has three tasks,get_hpa_manifests,adjust_limits, andadd_horizontal_scaling_suggestions, because you need to get themaxReplicasproperty of theHorizontalPodAutoscalermanifest and multiply the pod limit with the maximum replicas to get the absolute upper limit.Let's build the vertical scaling branch of the workflow first.
-
To build the vertical scaling branch, you add the
add_vertical_scaling_suggestionstask. Select Add task on the trigger node. This task adds scaling suggestions to each workload that needs vertical scaling and parses the given Davis predictions and returns all Kubernetes workloads with their predictions. -
In the Choose action section, select the Run JavaScrip action type.
-
On the Input tab, copy the following code and paste it into the Source code box:
import {actionExecution} from "@dynatrace-sdk/automation-utils";import {convert, units} from "@dynatrace-sdk/units";export default async function ({action\_execution\_id}) {const actionEx = await actionExecution(action\_execution\_id);const workload = actionEx.loopItem.workload;const targetUtilization = calculateTargetUtilization(workload.scalingConfig);const prompts = \[];const descriptions = \[`Davis AI has detected that the ${workload.kind} \`${workload.name}\` can be scaled based on predictive AI analysis. Therefore, this PR applies the following actions:\n\`];workload.predictions.forEach(prediction => {let resourceName;let newLimit;let range;let type;let exceedsLimit;if (prediction.resource === 'cpu') {resourceName = 'CPU';newLimit = `${Math.ceil(prediction.value / workload.scalingConfig.targetUtilization.cpu.point)}m`;range = `${workload.scalingConfig.targetUtilization.cpu.min * 100}-${workload.scalingConfig.targetUtilization.cpu.max * 100}%`;if (prediction.value > targetUtilization.cpu.max) {type = 'up';} else if (workload.scalingConfig.scaleDown && prediction.value < targetUtilization.cpu.min) {type = 'down';}exceedsLimit = type === 'up' && prediction.value > workload.scalingConfig.limits.cpu;} else if (prediction.resource === "memory") {resourceName = 'Memory';newLimit = `${Math.ceil(convert(Math.ceil(prediction.value / workload.scalingConfig.targetUtilization.memory.point),units.data.byte,units.data.mebibyte))}Mi`;range = `${workload.scalingConfig.targetUtilization.memory.min * 100}-${workload.scalingConfig.targetUtilization.memory.max * 100}%`;if (prediction.value > targetUtilization.memory.max) {type = 'up';} else if (workload.scalingConfig.scaleDown && prediction.value < targetUtilization.memory.min) {type = 'down';}exceedsLimit = type === 'up' && prediction.value > workload.scalingConfig.limits.memory;}const prompt = `Scale the ${resourceName} request & limit of the ${workload.kind} named "${workload.name}" in this manifest to \`${newLimit}\`.\`;let description = type === 'up'? `- ⬆️ **${resourceName}**: Scale up to \`${newLimit}\` (predicted to exceed its target range of ${range} at \`${prediction.date.toString()}\`)`: `- ⬇️ **${resourceName}**: Scale down to \`${newLimit}\` (predicted to stay below its target range of ${range} until \`${prediction.predictedUntil.toString()}\`)`if (exceedsLimit) {description = `- ⚠️ **${resourceName}**: Scale up to \`${newLimit}\` (predicted to exceed its ${resourceName} limit at \`${prediction.date.toString()}\`)`}descriptions.push(description);prompts.push({type, prompt, predictions: [prediction]});});if (prompts.length > 0) {descriptions.push(`\n_This Pull Request was automatically created by Davis CoPilot._`)workload.scalingSuggestions = {description: descriptions.join('\n'),prompts};}return workload;}const calculateTargetUtilization = (scalingConfig) => {return {cpu: {max: scalingConfig.limits.cpu \* scalingConfig.targetUtilization.cpu.max,min: scalingConfig.limits.cpu \* scalingConfig.targetUtilization.cpu.min,point: scalingConfig.limits.cpu \* scalingConfig.targetUtilization.cpu.point},memory: {max: scalingConfig.limits.memory \* scalingConfig.targetUtilization.memory.max,min: scalingConfig.limits.memory \* scalingConfig.targetUtilization.memory.min,point: scalingConfig.limits.memory \* scalingConfig.targetUtilization.memory.point}};} -
On the Options tab for the Loop task, set the Item variable name to workload.
-
In the List box, copy and paste the following:
[{% for workload in result("parse_predictions") %}{% if workload.scalingConfig.horizontalScaling.enabled == false %}{{ workload }},{% endif %}{% endfor %}]It loops over all Kubernetes workloads and checks whether the limit will be exceeded. If yes, it adds a
scalingSuggestionproperty to the workload that includes the prompt and the description of what will happen.
-
-
Let's build the horizontal scaling branch of our workflow. It consists of three tasks:
get_hpa_manifests,adjust_limits, andadd_horizontal_scaling_suggestions.-
To add the
get_hpa_manifeststask, select Add task on the task node. This task adjusts the CPU and Memory limit based on the HorizontalPodAutoscalerspecification. -
In the Choose action section, select the Kubernetes Automations (Preview) Get resource action type.
-
On the Input tab
- Select the Connection you previously created.
- Set the Namespace to
{{ _.workload.namespace }}. - Set the Resource Type to
horizontalpodautoscalers.autoscaling. - Set the Name to
{{ _.workload.name }}.
-
On the Options tab
-
Toggle the Loop task. It loops over all workloads where horizontal scaling is enabled.
-
Set the Item variable name to
workload. -
In the List box, copy and paste the following:
[{% for workload in result("parse_predictions") %}{% if workload.scalingConfig.horizontalScaling.enabled %}{{ workload }},{% endif %}{% endfor %}]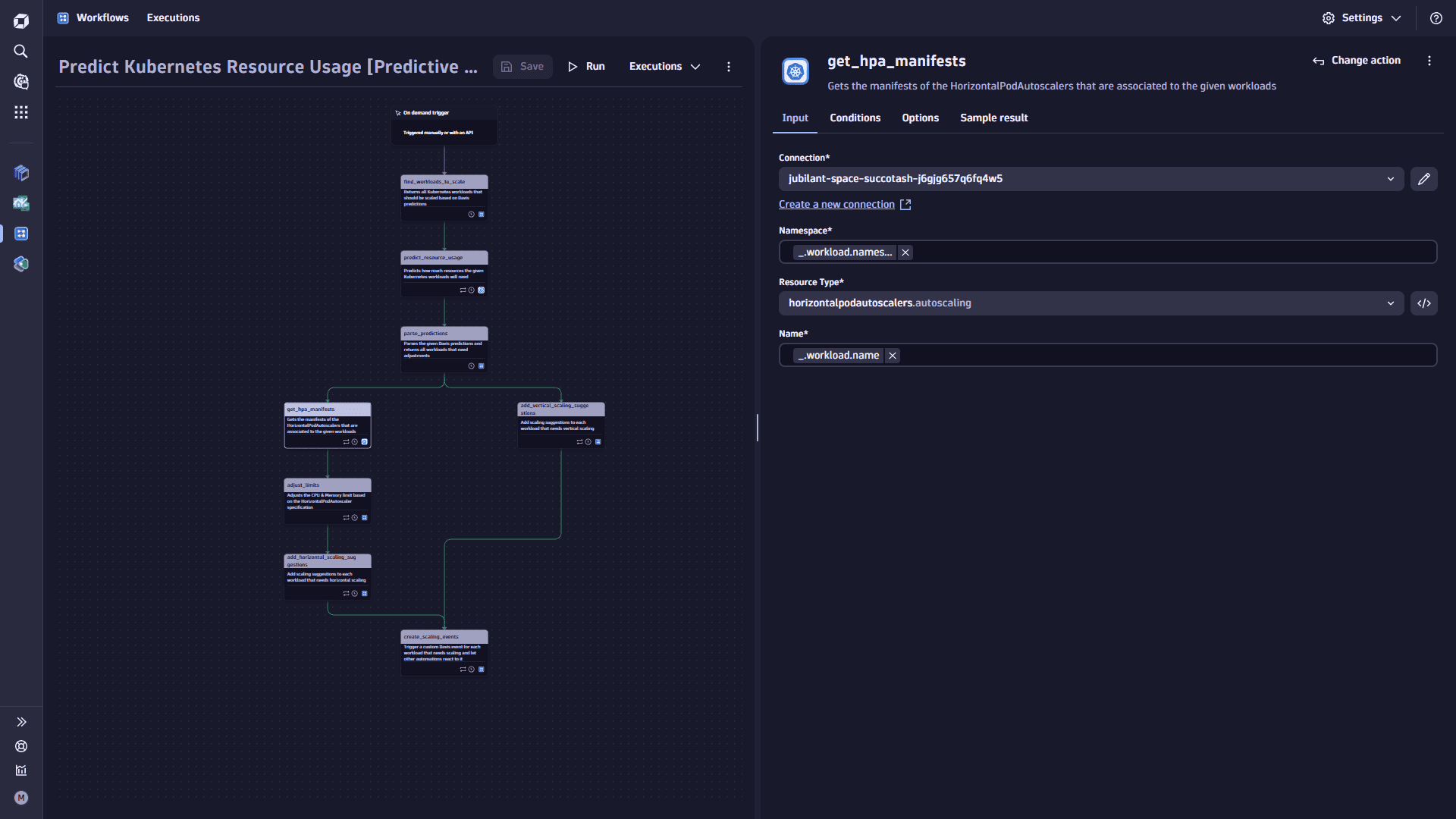
-
-
-
Add the
adjust_limitstask.-
Select
Add task on the task node. This task adjusts the CPU and Memory limit based on the HorizontalPodAutoscalerspecification. -
In the Choose action section, select the Run JavaScript action type.
-
In the Input tab, copy the following code and paste it into the Source code box:
import {execution, actionExecution} from "@dynatrace-sdk/automation-utils";export default async function ({execution\_id, action\_execution\_id}) {const actionEx = await actionExecution(action\_execution\_id);const workload = actionEx.loopItem.workload;// Get matching HPA manifestconst ex = await execution(execution\_id);const allHpaManifests = await ex.result('get\_hpa\_manifests');const hpaManifest = allHpaManifests.find(manifest =>manifest.metadata.name === workload.scalingConfig.horizontalScaling.hpa.name&& manifest.metadata.namespace === workload.namespace&& manifest.spec.scaleTargetRef.name === workload.name);// Adjust limitsconst maxReplicas = hpaManifest.spec.maxReplicas;workload.scalingConfig.horizontalScaling.hpa = {...workload.scalingConfig.horizontalScaling.hpa,maxReplicas,uuid: hpaManifest.metadata.annotations\['predictive-kubernetes-scaling.observability-labs.dynatrace.com/uuid'],limits: {cpu: maxReplicas \* workload.scalingConfig.limits.cpu,memory: maxReplicas \* workload.scalingConfig.limits.memory}};return workload;} -
On the Options tab for the Loop task, set the Item variable name to workload.
-
In the List box, copy and paste the following:
[{% for workload in result("parse_predictions") %}{% if workload.scalingConfig.horizontalScaling.enabled %}{{ workload }},{% endif %}{% endfor %}]It combines all workloads where horizontal scaling is enabled with the HPA (HorizontalPodAutoscaler) manifests from the previous step and then adjusts the limits by multiplying them by the HPA's
maxReplicas.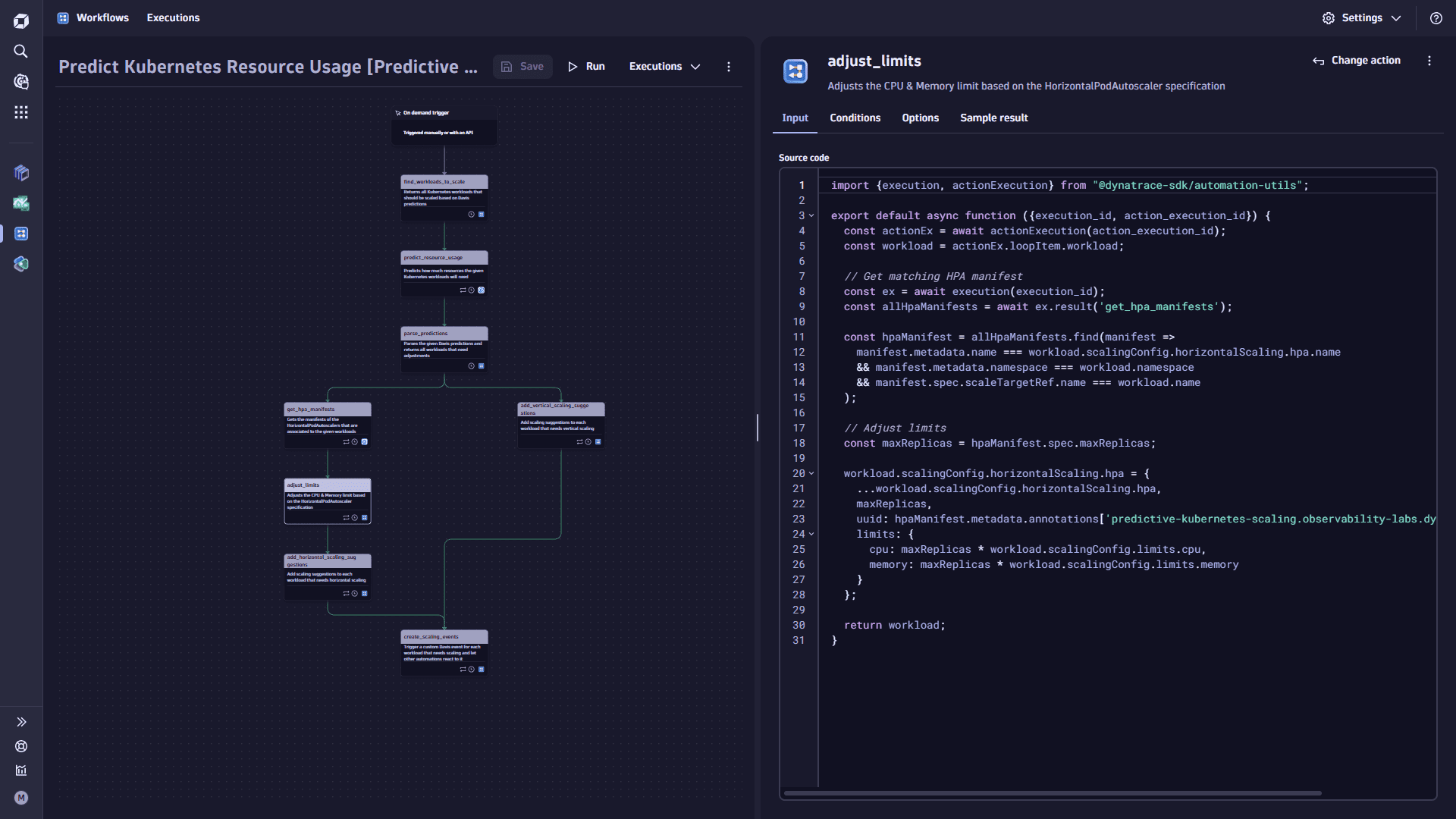
-
-
Add the
add_horizontal_scaling_suggestionstask.-
Select
Add task on the trigger node. This task adds scaling suggestions to each workload that needs horizontal scaling. -
In the Choose action section, select the Run JavaScrip action type.
-
In the Input tab, copy the following code and paste it into the Source code box:
import {actionExecution} from "@dynatrace-sdk/automation-utils";import {convert, units} from "@dynatrace-sdk/units";export default async function ({action\_execution\_id}) {const actionEx = await actionExecution(action\_execution\_id);const workload = actionEx.loopItem.workload;const targetUtilization = calculateTargetUtilization(workload.scalingConfig);let newMaxReplicas = 0;const predictionsToApply = \[];const descriptions = \[];let exceedsLimits = false;workload.predictions.forEach(prediction => {let replicas = 0;if (prediction.resource === 'cpu' && prediction.value > targetUtilization.cpu.max) {predictionsToApply.push(prediction);// Calculate new max replicasconst newLimit = Math.ceil(prediction.value / workload.scalingConfig.targetUtilization.cpu.point);replicas = Math.ceil(newLimit / workload.scalingConfig.limits.cpu);// Get descriptionif (prediction.value > workload.scalingConfig.horizontalScaling.hpa.limits.cpu) {exceedsLimits = true;descriptions.push(` - ⚠️ **CPU**: Predicted to exceed its CPU limit of \`${workload.scalingConfig.horizontalScaling.hpa.limits.cpu}m\` (\`${workload.scalingConfig.limits.cpu}m \* ${workload.scalingConfig.horizontalScaling.hpa.maxReplicas}\`) at \`${prediction.date.toString()}\`)`)} else {const range = `${workload.scalingConfig.targetUtilization.cpu.min \* 100}-${workload.scalingConfig.targetUtilization.cpu.max \* 100}%`;descriptions.push(` - ⬆️ **CPU**: Predicted to exceed its target range of ${range} at \`${prediction.date.toString()}\`)\`)}} else if (prediction.resource === 'memory' && prediction.value > targetUtilization.memory.max) {predictionsToApply.push(prediction);// Calculate new max replicasconst newLimit = Math.ceil(prediction.value / workload.scalingConfig.targetUtilization.memory.point);replicas = Math.ceil(newLimit / workload.scalingConfig.limits.memory);// Get descriptionif (prediction.value > workload.scalingConfig.horizontalScaling.hpa.limits.memory) {exceedsLimits = true;const limit = `${convert(workload.scalingConfig.limits.memory,units.data.byte,units.data.mebibyte)}`;descriptions.push(` - ⚠️ **Memory**: Predicted to exceed its Memory limit of \`${limit \* workload.scalingConfig.horizontalScaling.hpa.maxReplicas}Mi\` (\`${limit}Mi \* ${workload.scalingConfig.horizontalScaling.hpa.maxReplicas}\`) at \`${prediction.date.toString()}\`)`)} else {const range = `${workload.scalingConfig.targetUtilization.memory.min \* 100}-${workload.scalingConfig.targetUtilization.memory.max \* 100}%`;descriptions.push(` - ⬆️ **Memory**: Predicted to exceed its target range of ${range} at \`${prediction.date.toString()}\`)\`)}}if (replicas > newMaxReplicas) {newMaxReplicas = replicas;}});if (newMaxReplicas > 0) {const fullDescription = \[`Davis AI has detected that the deployment anomaly-simulation can be scaled based on predictive AI analysis. Therefore, this PR applies the following actions:\n`,`- ${exceedsLimits ? '⚠️' : '⬆️'} **HorizontalPodAutoscaler**: Scale the maximum number of replicas to \`${newMaxReplicas}\`:`,...descriptions,`\n\_This Pull Request was automatically created by Davis CoPilot.\_` ];workload.scalingSuggestions = {description: fullDescription.join('\n'),prompts: [{type: 'up',prompt:`Scale the maxReplicas of the HorizontalPodAutoscaler named "${workload.scalingConfig.horizontalScaling.hpa.name}" in this manifest to ${newMaxReplicas}.\`,predictions: predictionsToApply}]};}return workload;}const calculateTargetUtilization = (scalingConfig) => {const limits = scalingConfig.horizontalScaling.hpa.limits;return {cpu: {max: limits.cpu \* scalingConfig.targetUtilization.cpu.max,min: limits.cpu \* scalingConfig.targetUtilization.cpu.min,point: limits.cpu \* scalingConfig.targetUtilization.cpu.point},memory: {max: limits.memory \* scalingConfig.targetUtilization.memory.max,min: limits.memory \* scalingConfig.targetUtilization.memory.min,point: limits.memory \* scalingConfig.targetUtilization.memory.point}};} -
On the Options tab for the Loop task, set the Item variable name to workload.
-
In the List box, copy and paste the following
{{ result("adjust_limits") }}. It loops over all workloads and checks if the limits will be exceeded. If yes, it adds ascalingSuggestionproperty to the workload including the prompt and the description of what will happen.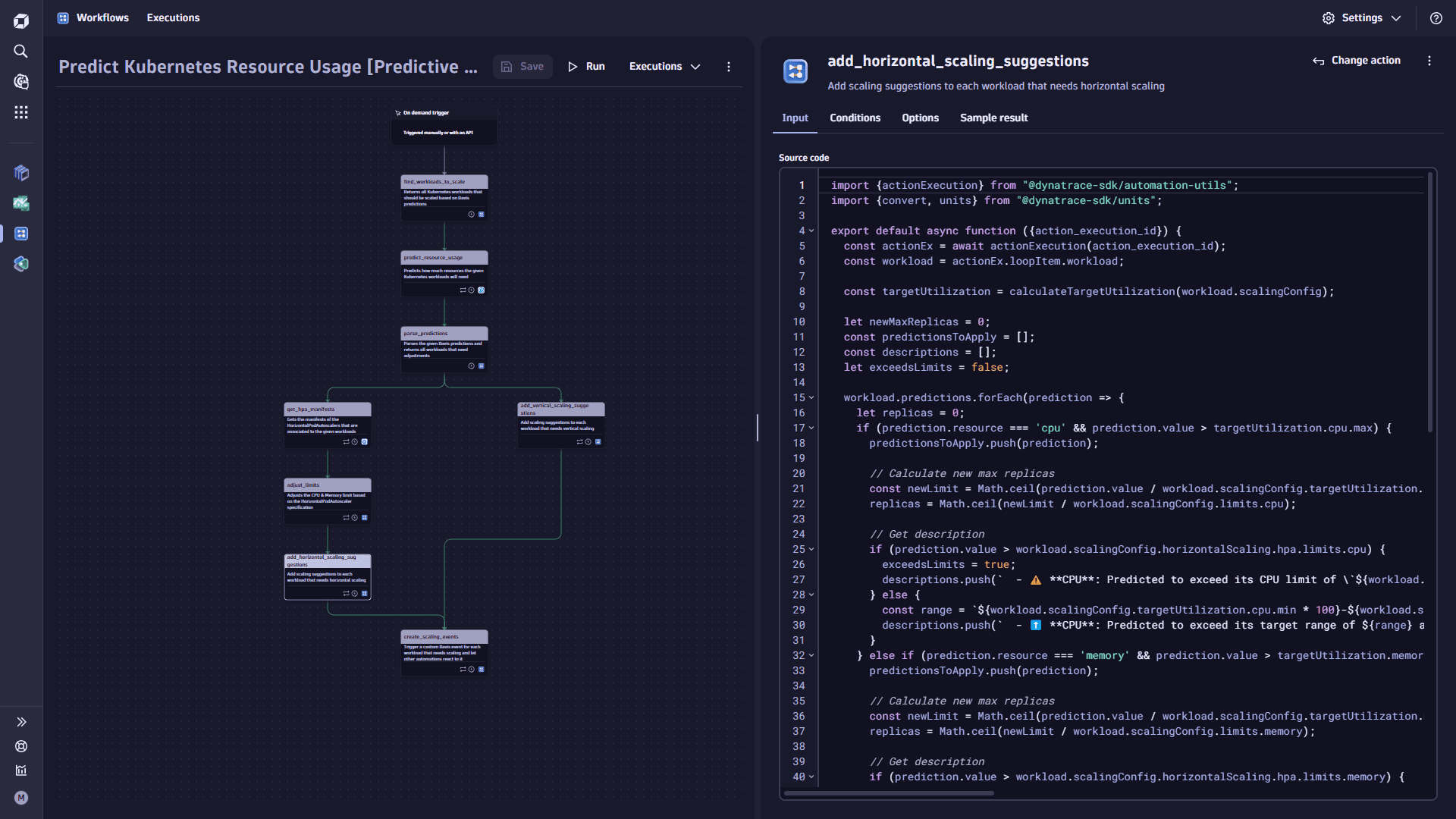
Now, you have a list of workloads with scaling suggestions from vertical and horizontal scaling. You need to get both lists and create events for the workloads that require scaling.
-
-
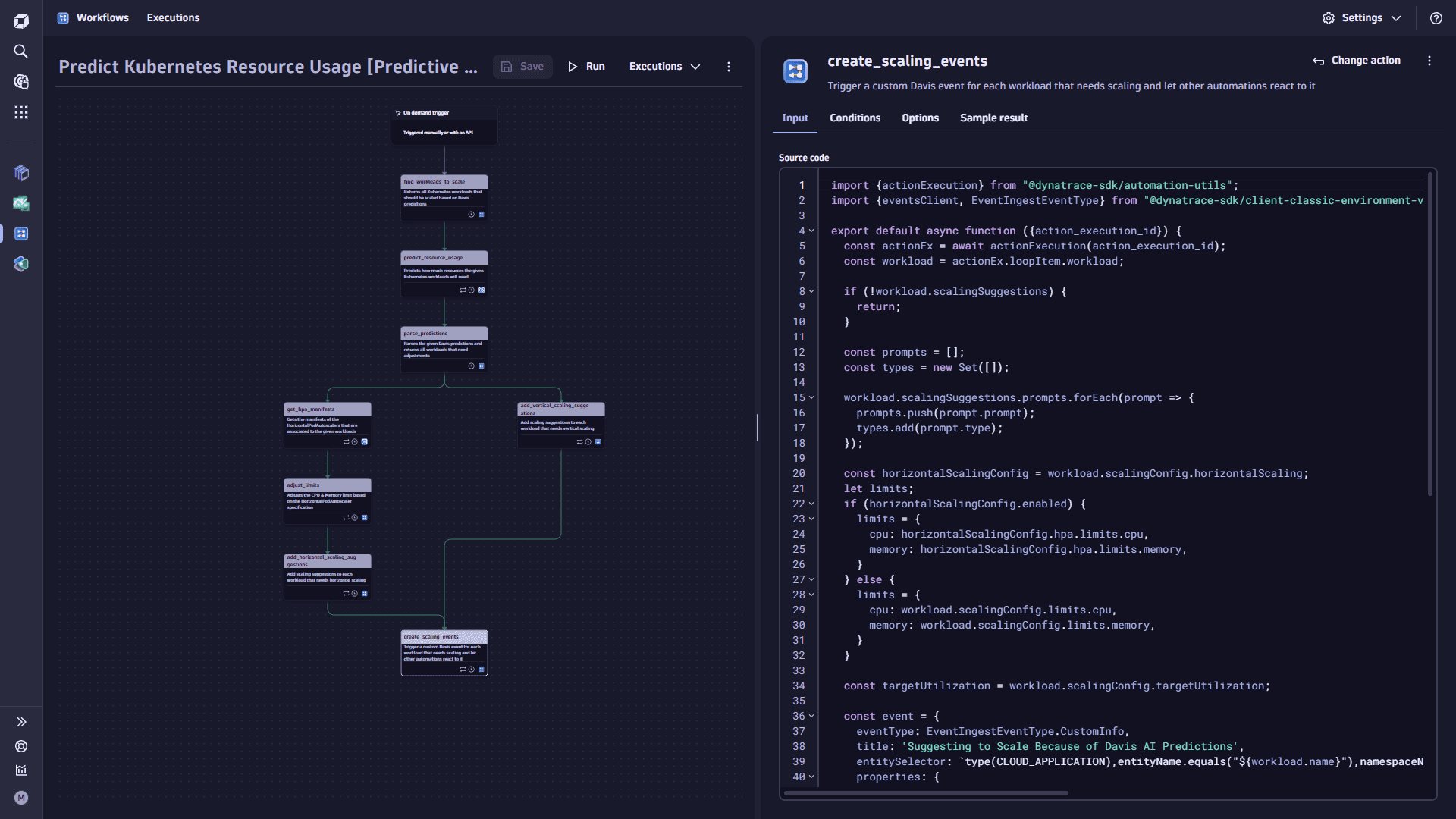
Add the
create_scaling_eventstask.-
Select
Add task on the trigger node. This task triggers a custom Davis event for each workload needing scaling and lets other automations react to it. -
In the Choose action section, select the Run JavaScrip action type.
-
On the Input tab, copy the following code and paste it into the Source code box:
import {actionExecution} from "@dynatrace-sdk/automation-utils";import {eventsClient, EventIngestEventType} from "@dynatrace-sdk/client-classic-environment-v2";export default async function ({action_execution_id}) {const actionEx = await actionExecution(action_execution_id);const workload = actionEx.loopItem.workload;if (!workload.scalingSuggestions) {return;}const prompts = [];const types = new Set([]);workload.scalingSuggestions.prompts.forEach(prompt => {prompts.push(prompt.prompt);types.add(prompt.type);});const horizontalScalingConfig = workload.scalingConfig.horizontalScaling;let limits;if (horizontalScalingConfig.enabled) {limits = {cpu: horizontalScalingConfig.hpa.limits.cpu,memory: horizontalScalingConfig.hpa.limits.memory,}} else {limits = {cpu: workload.scalingConfig.limits.cpu,memory: workload.scalingConfig.limits.memory,}}const targetUtilization = workload.scalingConfig.targetUtilization;const event = {eventType: EventIngestEventType.CustomInfo,title: 'Suggesting to Scale Because of Davis AI Predictions',entitySelector: `type(CLOUD_APPLICATION),entityName.equals("${workload.name}"),namespaceName("${workload.namespace}"),toRelationships.isClusterOfCa(type(KUBERNETES_CLUSTER),entityId("${workload.clusterId}"))`,properties: {'kubernetes.predictivescaling.type': 'DETECT_SCALING',// Workload'kubernetes.predictivescaling.workload.cluster.name': workload.cluster,'kubernetes.predictivescaling.workload.cluster.id': workload.clusterId,'kubernetes.predictivescaling.workload.kind': workload.kind,'kubernetes.predictivescaling.workload.namespace': workload.namespace,'kubernetes.predictivescaling.workload.name': workload.name,'kubernetes.predictivescaling.workload.uuid': workload.uuid,'kubernetes.predictivescaling.workload.limits.cpu': limits.cpu,'kubernetes.predictivescaling.workload.limits.memory': limits.memory,// Prediction'kubernetes.predictivescaling.prediction.type': [...types].join(','),'kubernetes.predictivescaling.prediction.prompt': prompts.join(' '),'kubernetes.predictivescaling.prediction.description': workload.scalingSuggestions.description,'kubernetes.predictivescaling.prediction.suggestions': JSON.stringify(workload.scalingSuggestions),// Target Utilization'kubernetes.predictivescaling.targetutilization.cpu.min': targetUtilization.cpu.min,'kubernetes.predictivescaling.targetutilization.cpu.max': targetUtilization.cpu.max,'kubernetes.predictivescaling.targetutilization.cpu.point': targetUtilization.cpu.point,'kubernetes.predictivescaling.targetutilization.memory.min': targetUtilization.memory.min,'kubernetes.predictivescaling.targetutilization.memory.max': targetUtilization.memory.max,'kubernetes.predictivescaling.targetutilization.memory.point': targetUtilization.memory.point,// Target'kubernetes.predictivescaling.target.uuid': horizontalScalingConfig.enabled ? horizontalScalingConfig.hpa.uuid : workload.uuid,'kubernetes.predictivescaling.target.repository': workload.repository,},}await eventsClient.createEvent({body: event});return event;} -
On the Options tab for the Loop task, set the Item variable name to workload.
-
In the List box, copy and paste the following
{{ result("add_horizontal_scaling_suggestions") + result("add_vertical_scaling_suggestions") }}It loops over all workloads and checks if it has scaling suggestions. If yes, it creates an event with all vital information.
-
-
Select Save.
-
Select Run.
The result of the first workflow is an event that will trigger the Commit Davis Prediction workflow you're creating in our next step. Decoupling scaling detection and the actual scaling action is good practice.
If your workflow doesn't identify any workloads or predictions, double-check your annotations on your workloads. Give it smaller targets so that that prediction target is reached faster. Remember, this is a sample use case, and it's OK to change your settings to see how the workflow behaves.
 Commit Davis AI prediction workflow
Commit Davis AI prediction workflow
This workflow is triggered every time the first workflow detects a Kubernetes workload that should be scaled and emits a Davis AI event.
Prerequisite
In this workflow a task uses JavaScript to call the GitHub API to create the pull request. While some of the GitHub for Workflows actions use the connection you set up when you followed the Set up GitHub for Workflows, your custom steps need to use the same Personal Access Token (PAT) that you query from the credential vault. Another token you need is a Dynatrace Platform API token to interact with the Davis AI CoPilot API.
As a prerequisite, you need to create new credential vault entries in Dynatrace that store the GitHub PAT and the Dynatrace Platform API token. You'll need the credential vault IDs, and you should replace the placeholders in the code snippets with your credential vault ID.
To create the second workflow
-
On the Workflows overview page, select
Workflow. -
Select the default title Untitled Workflow, and copy and paste the workflow title Commit Davis Prediction.
-
In the Select trigger section
-
Select trigger type Event trigger.
-
In Filter query, copy and paste the following
kubernetes.predictivescaling.type == "DETECT_SCALING"
-
-
Add the
find_manifesttask.-
Select
Add task on the task node. This task searches for the workload manifest on GitHub.Replace the
CREDENTIALS_VAULT-ID_FOR_GITLAB_PAT_TOKENwith your credential vault ID as created in the pre-requisite of this step. -
In the Choose action section, select the Run JavaScript action type.
-
On the Input tab, copy the following code and paste it into the Source code box:
import {execution} from '@dynatrace-sdk/automation-utils';import {credentialVaultClient} from "@dynatrace-sdk/client-classic-environment-v2";export default async function ({execution_id}) {const ex = await execution(execution_id);const event = ex.params.event;const apiToken = await credentialVaultClient.getCredentialsDetails({id: "CREDENTIALS_VAULT-ID_FOR_GITLAB_PAT_TOKEN",}).then((credentials) => credentials.token);// Search for fileconst url = 'https://api.github.com/search/code?q=' +`"predictive-kubernetes-scaling.observability-labs.dynatrace.com/uuid:%20'${event['kubernetes.predictivescaling.target.uuid']}'"` +`+repo:${event['kubernetes.predictivescaling.target.repository']}` +`+language:YAML`const response = await fetch(url, {method: 'GET',headers: {'Authorization': `Bearer ${apiToken}`}}).then(response => response.json());const searchResult = response.items[0];// Get default branchconst repository = await fetch(searchResult.repository.url, {method: 'GET',headers: {'Authorization': `Bearer ${apiToken}`}}).then(response => response.json());return {owner: searchResult.repository.owner.login,repository: searchResult.repository.name,filePath: searchResult.path,defaultBranch: repository.default_branch}}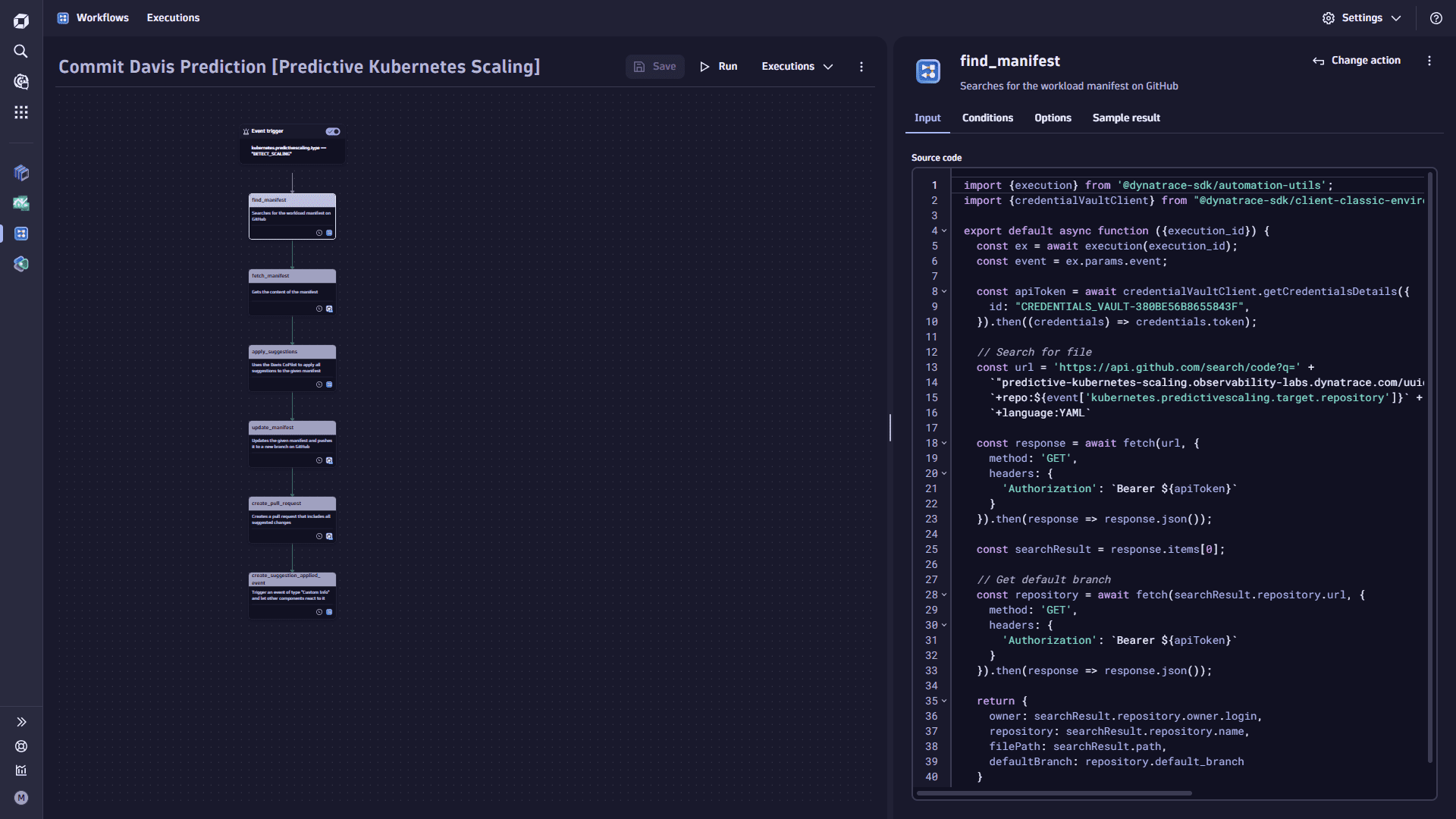
-
-
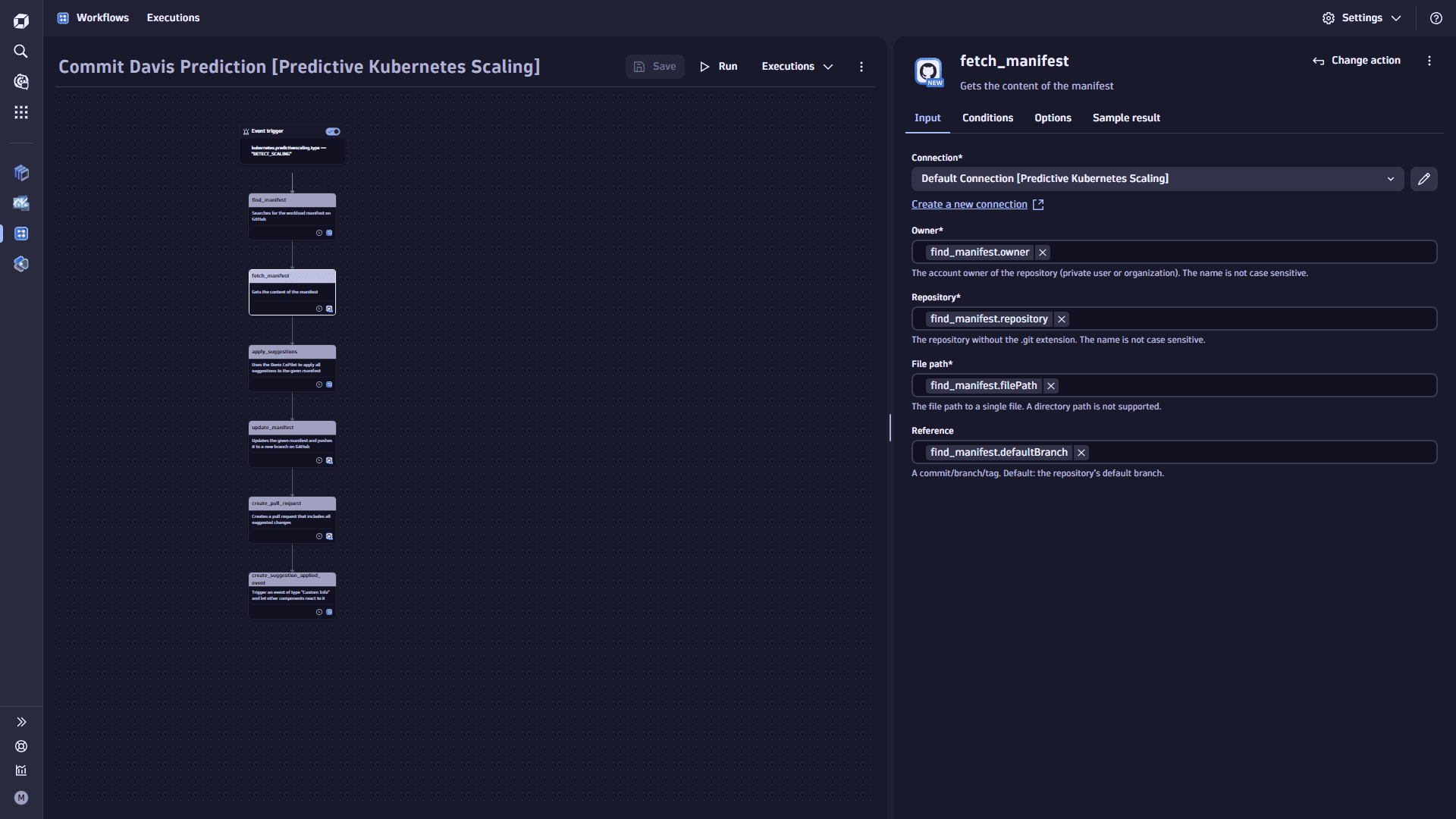
Add the
fetch_manifesttask.-
Select
Add task on the task node. This task gets the content of the manifest. -
In the Choose action section, select the GitHub Get content action type.
-
On the Input tab
- Set the Connection.
- Set the Owner to
find.manifest.owner. - Set the Repository
find.manifest.repository. - Set the File path
find.manifest.filePath. - Set the Reference
find.manifest.defaultBranch.
-
On the Options tab, toggle the Adapt timeout and set Timeout this task (seconds) to
900.
-
-
Add the
apply_suggestionstask.-
Select
Add task on the task node. This task uses the Davis CoPilot to apply all suggestions to the manifest.Replace the
CREDENTIALS_VAULT-ID_FOR_DYNATRACE_COPILOT_TOKENwith your credential vault ID as created in the pre-requisite of this step. -
In the Choose action section, select the Run JavaScript action type.
-
In the Input tab, copy the following code and paste it into the Source code box:
import {execution} from '@dynatrace-sdk/automation-utils';import {credentialVaultClient} from '@dynatrace-sdk/client-classic-environment-v2';import {getEnvironmentUrl} from '@dynatrace-sdk/app-environment'export default async function ({execution_id}) {const ex = await execution(execution_id);var manifest = (await ex.result('fetch_manifest')).content;const event = ex.params.event;const apiToken = await credentialVaultClient.getCredentialsDetails({id: "CREDENTIALS_VAULT-ID_FOR_DYNATRACE_COPILOT_TOKEN",}).then((credentials) => credentials.token);const url = `${getEnvironmentUrl()}/platform/davis/copilot/v0.2/skills/conversations:message`;const response = await fetch(url, {method: 'POST',headers: {'Authorization': `Bearer ${apiToken}`,'Content-Type': 'application/json'},body: JSON.stringify({text: `${event['kubernetes.predictivescaling.prediction.prompt']}\n\n${manifest}`})}).then(response => response.json());return {manifest: response.text.match(/(?<=^```(yaml|yml).*\n)([^`])*(?=^```$)/gm)[0],time: new Date(event.timestamp).getTime(),description: event['kubernetes.predictivescaling.prediction.description']};}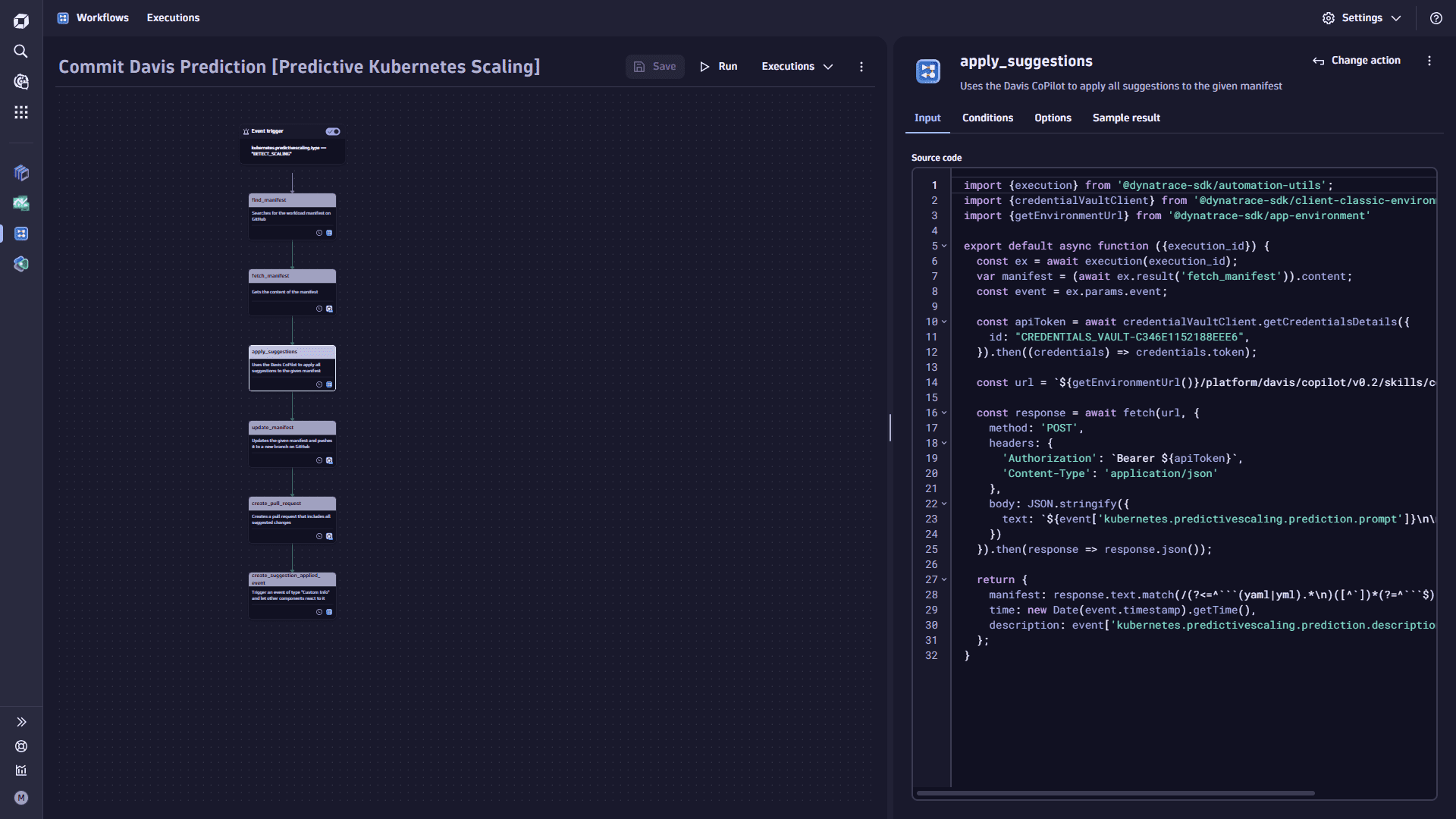
-
-
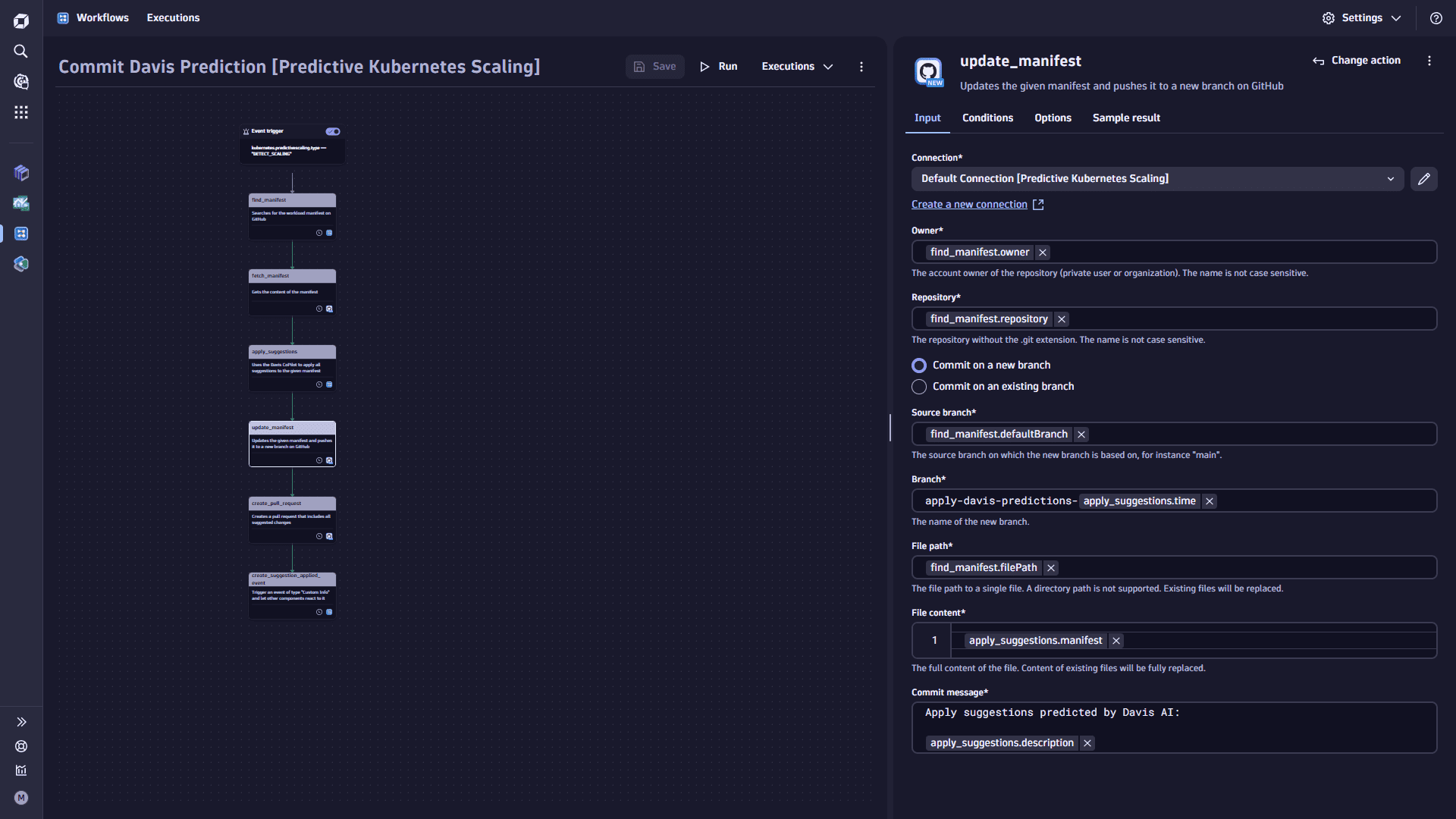
Add the
update_manifesttask.-
Select
Add task on the task node. This task updates the manifest and pushes it to a new branch on GitHub. -
In the Choose action section, select the GitHub Create or replace file action type.
-
In the Input tab
- Set the Connection.
- Set the Owner to
find.manifest.owner. - Set the Repository
find.manifest.repository. - Set the Source branch to
apply-davis-predictions-{{result("apply_suggestions").time}}. - Set the Target branch to
find_manifest.defaultBranch. - Set the Pull request title to
Apply suggestions predicted by Dynatrace Davis AI. - Set the Pull request description to
apply_suggestions.description.
-
-
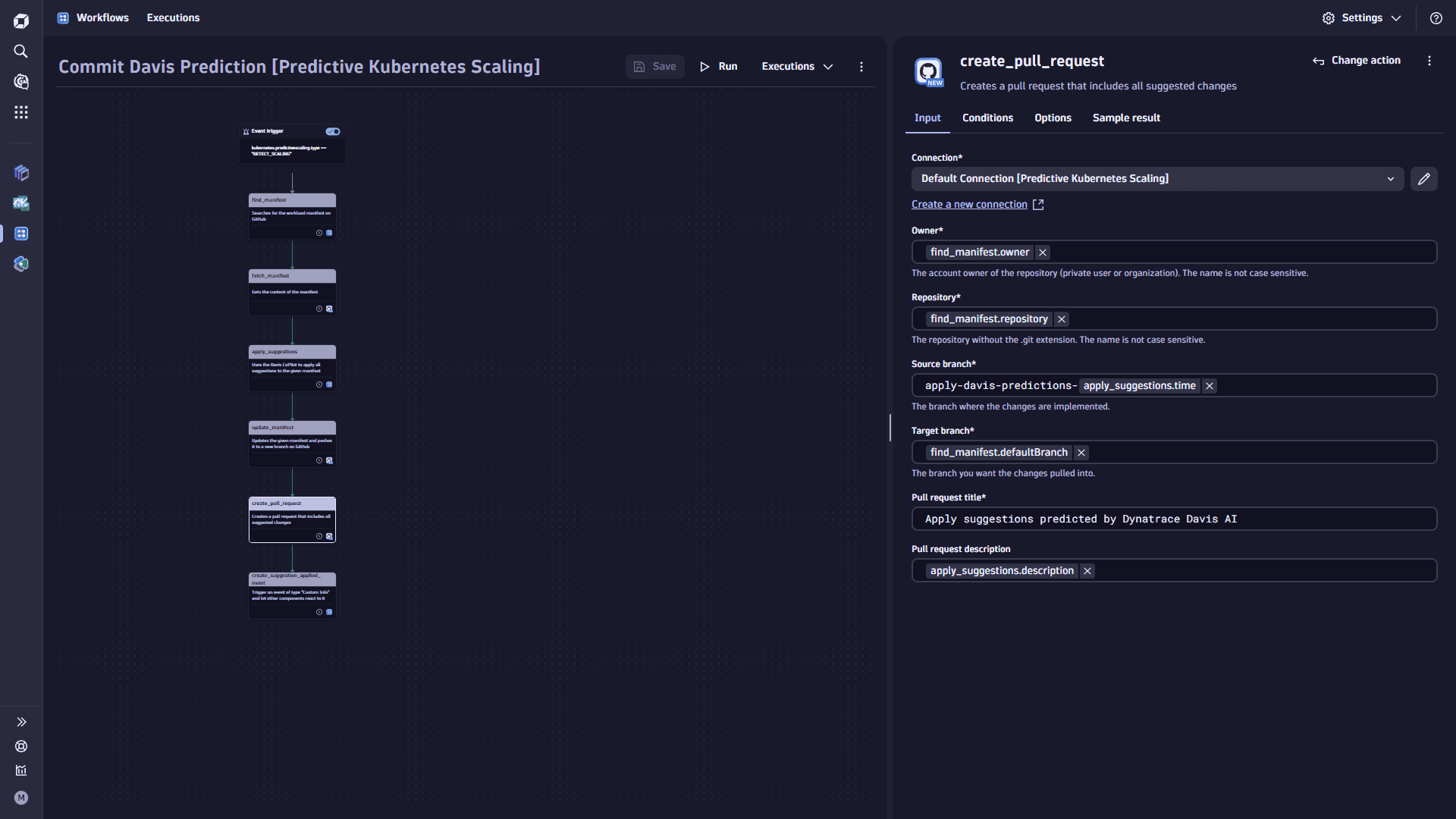
Add the
create_pull_requesttask.-
Select
Add task on the task node. This task creates a pull request (PR) that includes all suggested changes. -
In the Choose action section, select the GitHub Create pull request action type.
-
In the Input tab, set the Connection.
- Set the Owner to
find.manifest.owner. - Toggle Commit on a new branch.
- Set the Source branch to
find.manifest.defaultBranch. - Set the Branch to
apply-davis-predictions-{{result("apply_suggestions").time}}. - Set the File path
find_manifest.filePath. - Set the File content
apply_suggestions.manifest. - Set the Commit message to
Apply suggestions predicted by Davis AI: {{ result("apply_suggestions").description }}.
- Set the Owner to
-
In the Options tab, toggle the Adapt timeout and set Timeout this task (seconds) to
900.
-
-
Add the
create_suggestion_applied_eventtask.-
Select
Add task on the task node. This task triggers an event of type Custom Infoand lets other components react to it. -
In the Choose action section, select the Run JavaScrip action type.
-
In the Input tab, copy the following code and paste it into the Source code box:
import {execution} from '@dynatrace-sdk/automation-utils';import {eventsClient, EventIngestEventType} from "@dynatrace-sdk/client-classic-environment-v2";export default async function ({execution_id}) {const ex = await execution(execution_id);const pullRequest = (await ex.result('create_pull_request')).pullRequest;const event = ex.params.event;const eventBody = {eventType: EventIngestEventType.CustomInfo,title: 'Applied Scaling Suggestion Because of Davis AI Prediction',entitySelector: `type(CLOUD_APPLICATION),entityName.equals("${event['kubernetes.predictivescaling.workload.name']}"),namespaceName("${event['kubernetes.predictivescaling.workload.namespace']}"),toRelationships.isClusterOfCa(type(KUBERNETES_CLUSTER),entityId("${event['kubernetes.predictivescaling.workload.cluster.id']}"))`,properties: {'kubernetes.predictivescaling.type': 'SUGGEST_SCALING',// Workload'kubernetes.predictivescaling.workload.cluster.name': event['kubernetes.predictivescaling.workload.cluster.name'],'kubernetes.predictivescaling.workload.cluster.id': event['kubernetes.predictivescaling.workload.cluster.id'],'kubernetes.predictivescaling.workload.kind': event['kubernetes.predictivescaling.workload.kind'],'kubernetes.predictivescaling.workload.namespace': event['kubernetes.predictivescaling.workload.namespace'],'kubernetes.predictivescaling.workload.name': event['kubernetes.predictivescaling.workload.name'],'kubernetes.predictivescaling.workload.uuid': event['kubernetes.predictivescaling.workload.uuid'],'kubernetes.predictivescaling.workload.limits.cpu': event['kubernetes.predictivescaling.workload.limits.cpu'],'kubernetes.predictivescaling.workload.limits.memory': event['kubernetes.predictivescaling.workload.limits.memory'],// Prediction'kubernetes.predictivescaling.prediction.type': event['kubernetes.predictivescaling.prediction.type'],'kubernetes.predictivescaling.prediction.prompt': event['kubernetes.predictivescaling.prediction.prompt'],'kubernetes.predictivescaling.prediction.description': event['kubernetes.predictivescaling.prediction.description'],'kubernetes.predictivescaling.prediction.suggestions': event['kubernetes.predictivescaling.prediction.suggestions'],// Target Utilization'kubernetes.predictivescaling.targetutilization.cpu.min': event['kubernetes.predictivescaling.targetutilization.cpu.min'],'kubernetes.predictivescaling.targetutilization.cpu.max': event['kubernetes.predictivescaling.targetutilization.cpu.max'],'kubernetes.predictivescaling.targetutilization.cpu.point': event['kubernetes.predictivescaling.targetutilization.cpu.point'],'kubernetes.predictivescaling.targetutilization.memory.min': event['kubernetes.predictivescaling.targetutilization.memory.min'],'kubernetes.predictivescaling.targetutilization.memory.max': event['kubernetes.predictivescaling.targetutilization.memory.max'],'kubernetes.predictivescaling.targetutilization.memory.point': event['kubernetes.predictivescaling.targetutilization.memory.point'],// Target'kubernetes.predictivescaling.target.uuid': event['kubernetes.predictivescaling.target.uuid'],'kubernetes.predictivescaling.target.repository': event['kubernetes.predictivescaling.target.repository'],// Pull Request'kubernetes.predictivescaling.pullrequest.id': `${pullRequest.id}`,'kubernetes.predictivescaling.pullrequest.url': pullRequest.url,},};await eventsClient.createEvent({body: eventBody});return eventBody;}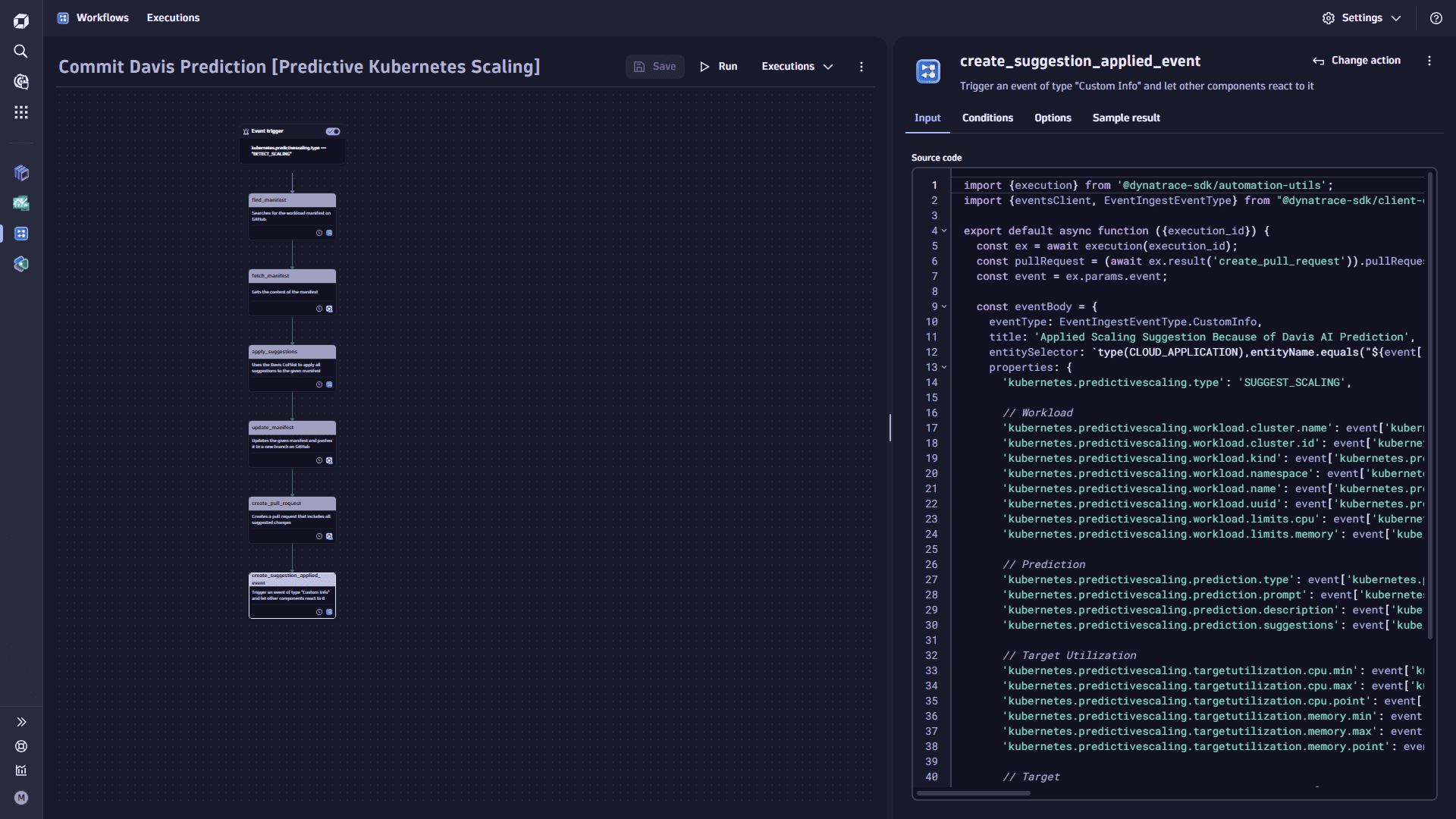
-
Summary
Now, you have two Dynatrace workflows that will provide AI-assisted predictive scaling as code. All you need to do is annotate your Kubernetes Deployments and wait for Dynatrace to open pull requests using Davis AI CoPilot to apply the forecasted memory and CPU limits to your manifests.