OpenAI
- Latest Dynatrace
- Explanation
- 1-min read
Monitoring your OpenAI requests via Dynatrace, you can get cost analysis and forecast estimation via Davis AI, prompt and completion recording, error tracking, performance metrics of your AI services, and more.
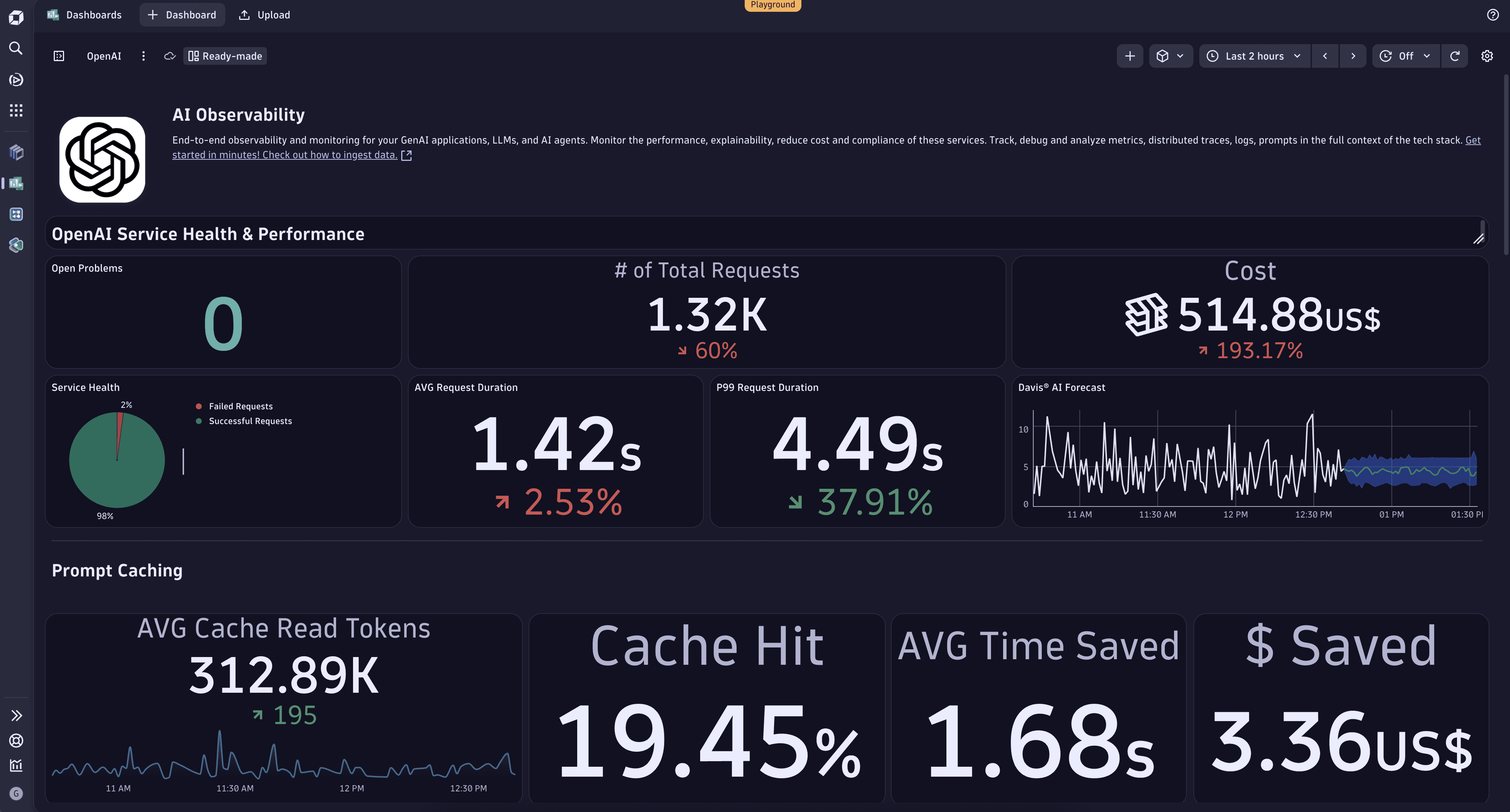
Explore the sample dashboard on the Dynatrace Playground.
Spans
The following attributes are available for GenAI Spans.
| Attribute | Type | Description |
|---|---|---|
gen_ai.completion.0.content | string | The full response received from the GenAI model. |
gen_ai.completion.0.content_filter_results | string | The filter results of the response received from the GenAI model. |
gen_ai.completion.0.finish_reason | string | The reason the GenAI model stopped producing tokens. |
gen_ai.completion.0.role | string | The role used by the GenAI model. |
gen_ai.openai.api_base | string | GenAI server address. |
gen_ai.openai.api_version | string | GenAI API version. |
gen_ai.openai.system_fingerprint | string | The fingerprint of the response generated by the GenAI model. |
gen_ai.prompt.0.content | string | The full prompt sent to the GenAI model. |
gen_ai.prompt.0.role | string | The role setting for the GenAI request. |
gen_ai.prompt.prompt_filter_results | string | The filter results of the prompt sent to the GenAI model. |
gen_ai.request.max_tokens | integer | The maximum number of tokens the model generates for a request. |
gen_ai.request.model | string | The name of the GenAI model a request is being made to. |
gen_ai.request.temperature | double | The temperature setting for the GenAI request. |
gen_ai.request.top_p | double | The top_p sampling setting for the GenAI request. |
gen_ai.response.model | string | The name of the model that generated the response. |
gen_ai.system | string | The GenAI product as identified by the client or server instrumentation. |
gen_ai.usage.completion_tokens | integer | The number of tokens used in the GenAI response (completion). |
gen_ai.usage.prompt_tokens | integer | The number of tokens used in the GenAI input (prompt). |
llm.request.type | string | The type of the operation being performed. |
Metrics
| Metric | Type | Unit | Description |
|---|---|---|---|
gen_ai.client.generation.choices | counter | none | The number of choices returned by chat completions call. |
gen_ai.client.operation.duration | histogram | s | The GenAI operation duration. |
gen_ai.client.token.usage | histogram | none | The number of input and output tokens used. |
llm.openai.embeddings.vector_size | counter | none | The size of returned vector. |
Related topics
Related tags
AI Observability