Rack aware conversion using replication
This method is useful for small Dynatrace Managed clusters where one node can contain a full replica. If your current metric storage (Cassandra database) per node is more than 1 TB, use the cluster restore method. You can use existing nodes to progressively (one after another) reinstall them with the rack aware parameter. Optionally, you can use additional hardware as new nodes and remove one node while installing a new node with the rack aware parameter.
The advantage of this approach is that it does not affect cluster availability however, in order to maintain the cluster availability you must allow Managed cluster to use its native replication methods to ensure data preservation. You should consider that, removing and adding a node to the cluster takes time. This time depends on the size of your metric storage and the speed of your disk or network. Some cluster operations may take even one or two days. Managed cluster will prevent all other cluster operations during that time (adding and removing nodes, upgrading and backup). If you choose to perform reinstallation on the existing host, wait 72 hours before reattaching that host to the cluster.
Preparation
-
Prepare the Cassandra database to spread replicas around your cluster (Python 2.7 is required).
On one of the existing nodes, alter the keyspace to change the snitch settings using Cassandra CQL:
sudo <managed-installation-dir>/cassandra/bin/cqlsh <node_IP>Where
<managed-installation-dir>is a directory of Dynatrace Managed binaries and<node-IP>is the current node's IP (Node that you are currently using).As a result, you'll enter CQL shell:
Connected to 00aa0a0a-1ab1-11a1-aaa1-0a0a0aa1a1aa at xx.xxx.xx.xxx:9042.[cqlsh 5.0.1 | Cassandra 3.0.23 | CQL spec 3.4.0 | Native protocol v4]Use HELP for help.cqlsh>Then execute:
ALTER KEYSPACE ruxitdb WITH REPLICATION = {'class': 'NetworkTopologyStrategy', 'datacenter1':3};When finished, type:
exit -
Prepare the cluster for adding nodes in different racks.
On each of existing nodes, edit
/etc/dynatrace.confand adjust the following settings:CASSANDRA_NODE_RACK = rack1CASSANDRA_NODE_RACK_DC = datacenter1ELASTICSEARCH_NODE_RACK = rack1Execute
sudo /opt/dynatrace-managed/installer/reconfigure.shto apply configuration changes for the cluster node.Execute sequentiallyExecute the
reconfigure.shscript sequentially because it triggers process restarts and there is a risk of Cassandra database downtime if it is executed on multiple nodes in parallel. -
Prepare new node(s).
Make sure the disk partition allocated for Cassandra storage on the new node is sufficient to contain the entire Cassandra database (with margin for compaction and new data). The disk size should be at least double of the combined Cassandra storage of all existing cluster nodes. It is a good practice to have Cassandra data on a separate volume in order to avoid disk space issues related to various types of data.
-
Make sure that rack settings map correctly to physical racks and data centers. Ideally, there should be an equal number of nodes in each rack at the end of the whole conversion.
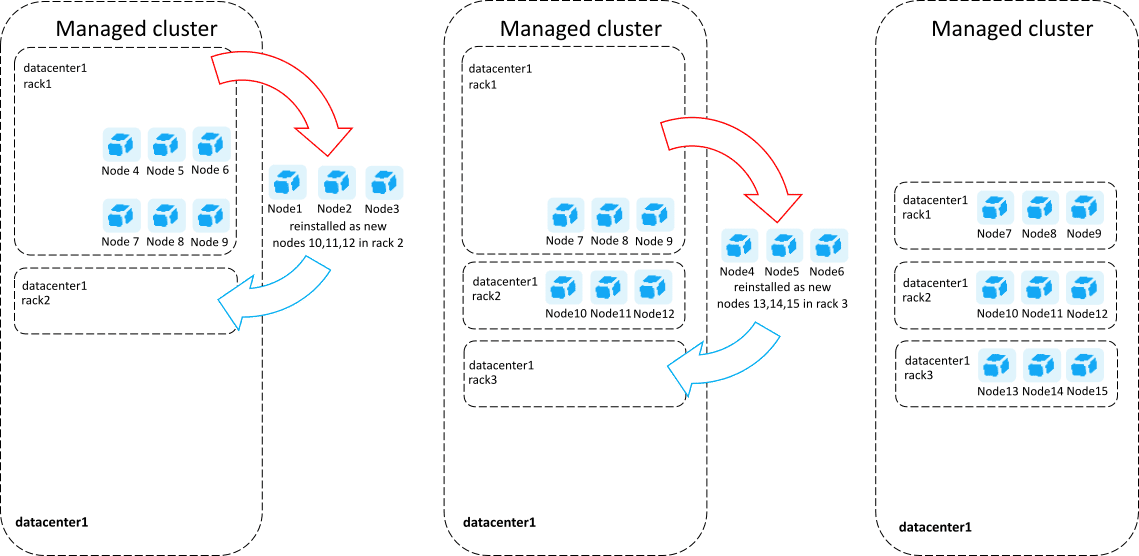
Extending the cluster into new racks
During the initial Dynatrace Managed deployment, all cluster nodes by default are grouped in a single default rack placed in a default data center. Even if your deployment is not rack aware, all of the nodes already are in datacenter1 rack1. To avoid adding a new node to the default rack, don't use the rack1 as a --rack-name parameter value for the new rack.
If you are converting the cluster in the same data center, use the default datacenter1 parameter value.
To extend the cluster into new racks
-
Add the new node with rack parameters to the cluster.
Use the Add a new cluster node procedure and append the
--rack-nameand--rack-dcparameters to the installation command. For example:/bin/sh dynatrace-managed-installer.sh --seed-auth abcdefjhij1234567890 --rack-name rack2 --rack-dc datacenter1Wait until the node fully joins the cluster. Depending on your database size, Cassandra bootstrapping may take several days.
HintIf the node has difficulties maintaining the data load, you can temporarily stop the Dynatrace server process on that node and free more CPU cycles for Cassandra.
-
Add another node to the same rack, with the same rack parameters.
This time, the Cassandra bootstrapping is expected to be quicker. -
Continue adding new nodes to
rack2. Once you have a sufficient number of nodes inrack2(1/3 of the target cluster size), begin adding new nodes with rack parameters torack3minding the disk space requirements. -
Once you have sufficient number of nodes also in
rack3, begin removing the original nodes that were configured without rack awareness (located in the defaultrack1rack).
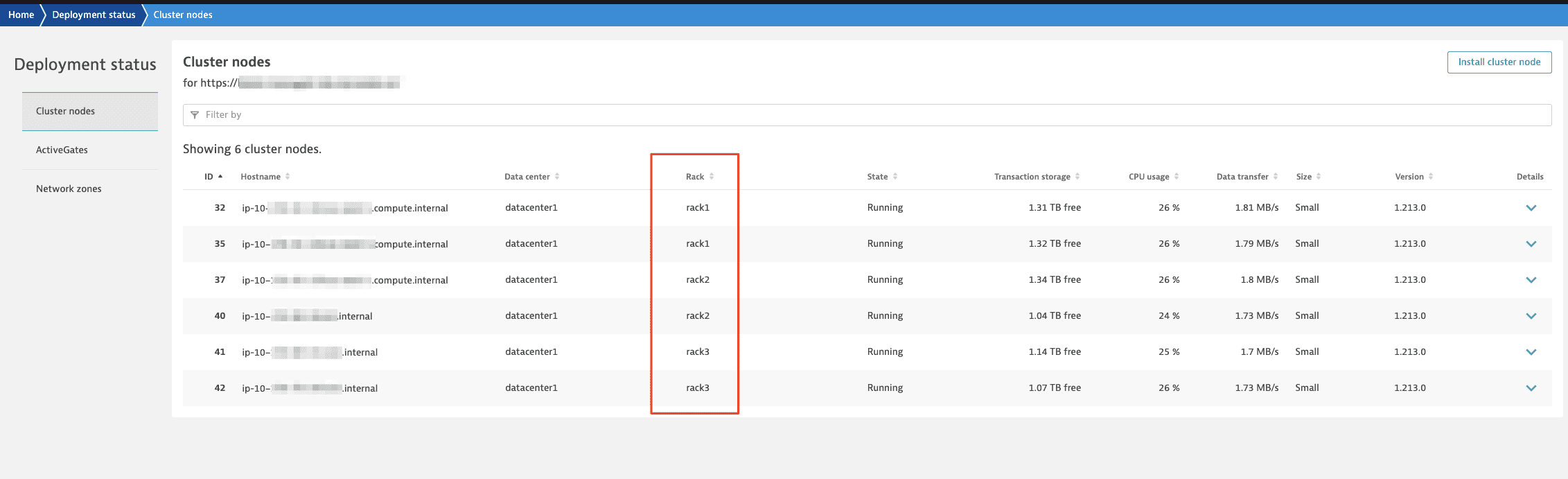
When the conversion is complete, you'll see racks in the Deployment status page in Cluster Management Console: