Terms and concepts about AI Observability and GenAI in Dynatrace
- Latest Dynatrace
- Explanation
- 3-min read
Dynatrace supports GenAI Observability by troubleshooting conversation issues, performance, costs, and correlating data throughout the product for effectively resolving issues in Large Language Models (LLMs) or traditional Machine Learning (ML).
This page provides definitions and explanations of the key terms used in our documentation.
Retrieval-Augmented Generation (RAG)
RAG is an AI technique that enhances the performance of LLMs by retrieving relevant documents or information from external sources. The retrieved data is used to enhance the input to the LLM during text generation.
Unlike traditional LLMs that rely solely on internal training data, RAG leverages real-time information to deliver more accurate, up-to-date, and contextually relevant responses.
Agents
In the context of AI and language models, an agent is an autonomous or semi-autonomous entity designed to perform specific tasks or solve problems.
Agents perform actions on behalf of users, professionals, or other systems, often based on received inputs or objectives. These agents can operate with varying levels of independence and intelligence, making them suitable for complex decision-making tasks, often powered by a language model.
Agentic
An agentic system utilizes intelligent agents that manage or request specific RAG tasks in real-time, enhancing control over the retrieval process.
In an agentic system, several agents work together to address complex queries. These agents assess the relevance of information dynamically, prioritize it, and modify the generation process based on evolving contexts.
Guardrails
Guardrails are runtime controls that help keep AI and Agentic applications safe, compliant, and predictable by detecting and handling unsafe or disallowed behavior (for example, policy-violating content, sensitive data/PII exposure, or abuse patterns). For AI observability, guardrails are critical because they explain why a model interaction was blocked, modified (redacted/truncated), or allowed. This turns a “the model failed” error into an actionable, policy-driven root cause that you can investigate and tune.
We recommend enabling provider-native guardrails as close to the model as possible (for example, Amazon Bedrock guardrails, Azure OpenAI safety filters, and OpenAI safety mechanisms) and emitting their outcomes via OpenTelemetry. OpenLLMetry captures guardrail data on the relevant GenAI spans using the OpenTelemetry GenAI semantic conventions (for example, outcome, category/reason, action taken, and provider/system), and Dynatrace consumes these exposed attributes/metrics through OpenTelemetry ingestion so you can filter and correlate guardrail-triggered requests with latency, token usage, and cost, and build dashboards/alerts on trends like rising blocks or redactions.
Dynatrace does not enforce runtime guardrails. Providers expose these signals, which Dynatrace captures and visualizes.
Configure guardrails at the provider level for lowest latency and complexity.
Instrumentation
Instrumentation is the process of adding observability code to an application.
Dynatrace uses OpenLLMetry, an instrumentation library based on OpenTelemetry. OpenLLMetry automatically registers an OpenTelemetry SDK and a list of instruments for popular GenAI frameworks, models, and vector databases.
To learn how to configure OpenLLMetry in your application, see the Get started page.
Traces
A trace describes a user request and all the operations performed to satisfy it. We can analyze the steps relevant to observing AI/ML workloads.
Traces help bring visibility into complex workflows, providing information about costs, performance, and insights into the quality of the generated output in the context of AI/ML workloads.
It's common to have LLM applications with complex and autonomous logic in which a model makes the decision. We can leverage traces to understand how requests propagate across RAG or agentic pipelines and see the details of each step that was executed.
Each action performed in a trace is stored as a span. The span attributes contain information relevant to AI/ML workloads (such as token costs for the operation, and input and output prompts). OpenLLMetry follows the OpenTelemetry Semantic Conventions for GenAI, so it's easy to find the relevant attribute keys.
The Distributed traces concepts page explains the trace concept in more detail.
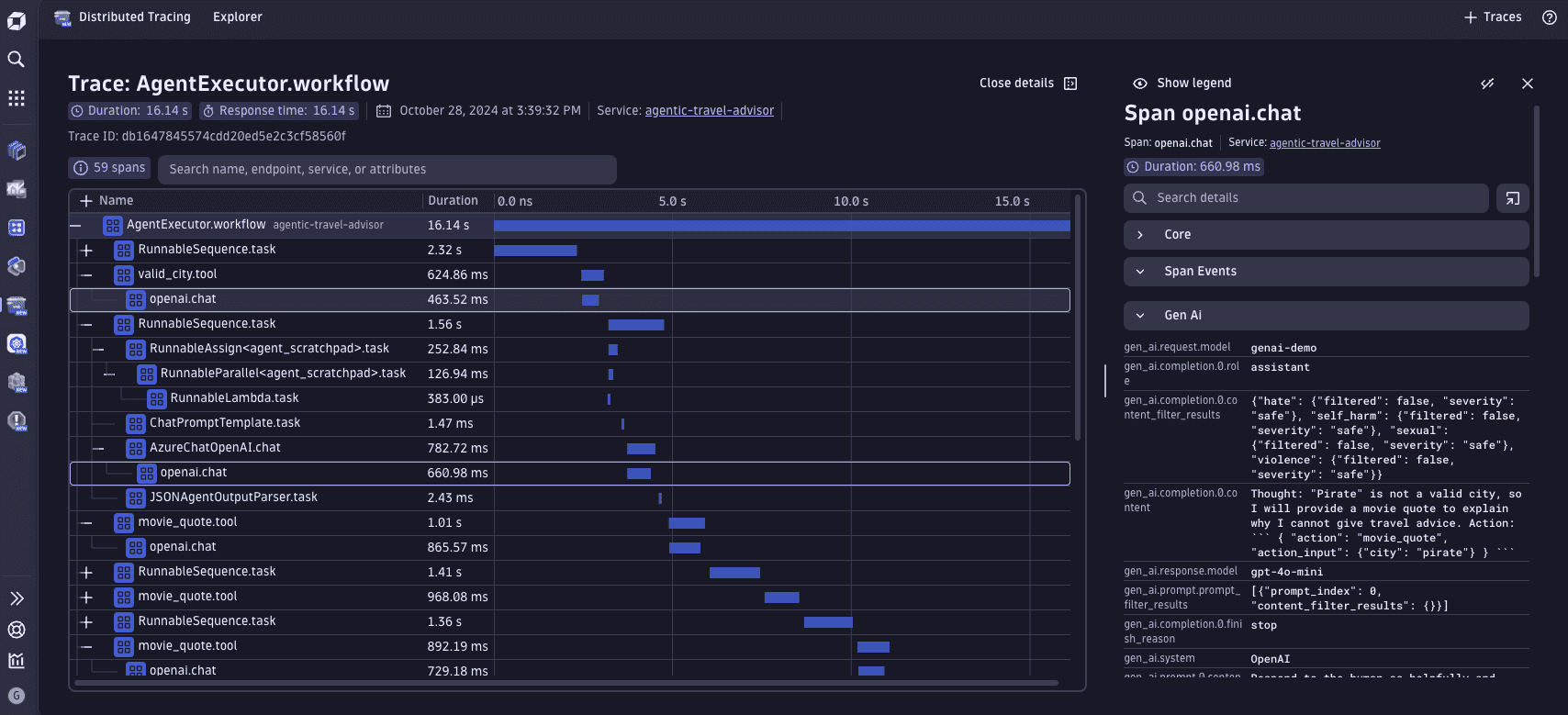
Agentic trace screenshot
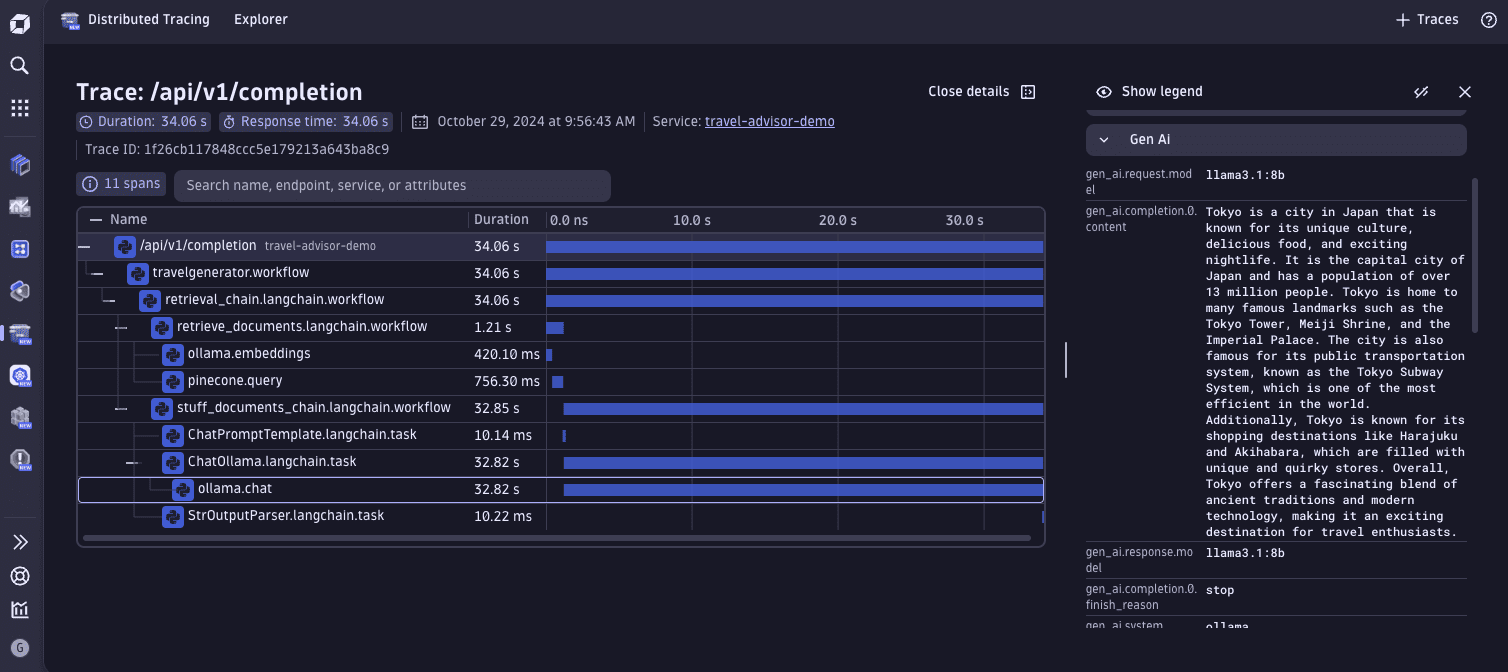
RAG trace screenshot
Traceloop span kind
Traceloop marks spans that belong to an LLM framework with a particular attribute, traceloop.span.kind. This attribute helps to organize and understand the structure of your application's traces, making it easier to analyze and debug complex LLM-based systems.
The traceloop.span.kind attribute can have one of four possible values:
workflows: Represents a high-level process or chain of operations.task: Denotes a specific operation or step within a workflow.agent: Indicates an autonomous component that can make decisions or perform actions.tool: Represents a utility or function used within the application.
OpenTelemetry GenAI semantic conventions
The OpenTelemetry GenAI semantic conventions standardize the attributes and metrics captured for generative AI operations, so data from different providers stays comparable.
For the full, current list of GenAI metrics, span attributes, agent, and provider-specific attributes, and which of them  AI Observability visualizes today, see the AI Observability metrics reference.
AI Observability visualizes today, see the AI Observability metrics reference.