Observability of Retrieval-Augmented Generation pipelines
- Latest Dynatrace
- Tutorial
- 12-min read
- Published Sep 19, 2024
Large Language Models (LLMs) are trained on vast volumes of data. However, they can present certain limitations.
- Training data is static and has a cut-off date on the knowledge.
- LLMs provide false information when they don't have the answer.
This use case illustrates a common approach to overcoming these limitations, which is to use a Retrieval-Augmented Generation (RAG) pipeline to provide the LLM with additional contextual information from an authoritative knowledge source, resulting in more accurate answers and more control over the generated output.
Try it yourself
Explore our sample dashboards on the Dynatrace Playground or get hands-on and deploy our GenAI demo app using GitHub Codespace.
What will you learn
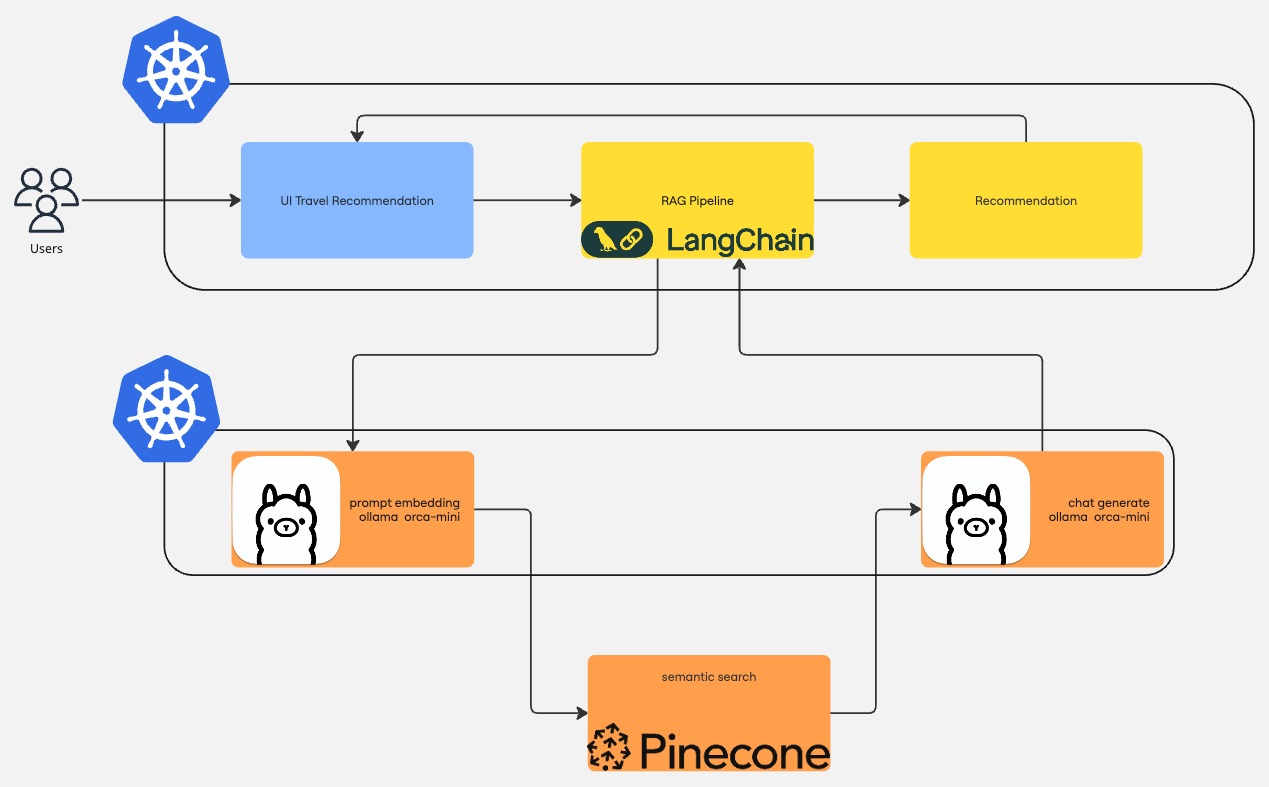
In this tutorial, we create a simple Python API that uses LangChain to implement a chatbot that suggests travel destinations for your next trip.
Before you begin
Prerequisites
- Access to your Kubernetes environment
- Pinecone (free) account
Steps
The general steps are as follows:
- Create API keys to connect to Pinecone and Dynatrace.
- Deploy our application on a Kubernetes cluster.
- Visualize important application signals to observe costs and the quality of the responses.
See below for the details of each step.
 Prepare API keys
Prepare API keys
In this step, we create create two API keys and store the keys as Kubernetes secrets. The API keys will be used to connect to Dynatrace and Pinecone.
Create Dynatrace token
To create a Dynatrace token
- In Dynatrace, go to Access Tokens.
To find Access Tokens, press CTRL+K to search for and select Access Tokens. - In Access Tokens, select Generate new token.
- Enter a Token name for your new token.
- Give your new token the following permissions:
- Search for and select all of the following scopes.
- Ingest metrics (
metrics.ingest) - Ingest logs (
logs.ingest) - Ingest events (
events.ingest) - Ingest OpenTelemetry traces (
openTelemetryTrace.ingest) - Read metrics (
metrics.read) - Write settings (
settings.write)
- Ingest metrics (
- Select Generate token.
- Copy the generated token to the clipboard. Store the token in a password manager for future use.
You can only access your token once upon creation. You can't reveal it afterward.
Store API key as Kubernetes secret
Now that you have a token with the necessary permissions, you can use the following command to store the Dynatrace API key as a Kubernetes secret. Our Python application will use it to send observability data to your tenant.
kubectl create secret generic dynatrace --from-literal token=<your-api-key> -n travel-advisor
If the command returns an error because the namespace is missing, you can create it by running kubectl create namespace travel-advisor
Connect to Pinecone
To connect to Pinecone
-
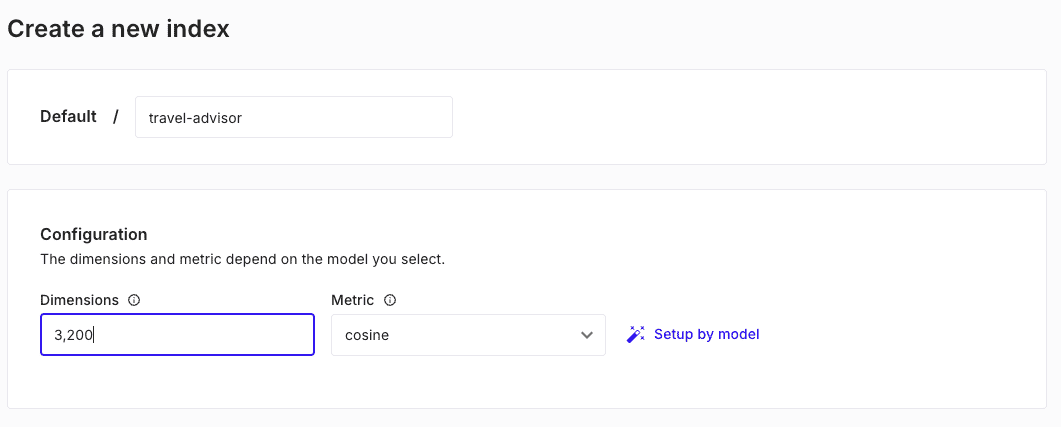
Create a new index called
travel-advisorwith the dimensions of 3200 and acosinemetric.The index will store our knowledge source, which the RAG pipeline will use to augment the LLM's output of the travel recommendation. The reasoning behind the selected dimensions is discussed later, in the deployment section.
-
After creating and running the index, we can create an API key to connect.
Follow the Pinecone documentation on authentication to get the API key to connect to your Pinecone index and store it as Kubernetes secrets with the following command:
kubectl create secret generic pinecone --from-literal api-key=<your-api-key> -n travel-advisor
 Create and deploy RAG pipeline
Create and deploy RAG pipeline
For our demo application, we use Ollama to generate the answer.
We also use Ollama for embedding, which is the process of converting a text into vectors that capture the semantic meaning of the text. Embedding allows us to convert our knowledge source into mathematical objects stored inside our Pinecone index. We can do the same with the user input and look for similar vectors in the Pinecone index to provide additional information to the LLM to generate the end response.
-
Create a new Kubernetes namespace called
ollama.apiVersion: v1kind: Namespacemetadata:name: ollamalabels:name: ollama -
Deploy the latest version of Ollama running on port 11434.
The Ollama container, by default, doesn't have any model. We need to tell the container which model to download explicitly and make it available through its APIs. To do this, we tell Kubernetes to run
ollama run orca-mini:3bafter the container is up and running, which tells Ollama to download the orca-mini:3b LLM.apiVersion: apps/v1kind: Deploymentmetadata:name: ollamanamespace: ollamaspec:selector:matchLabels:name: ollamatemplate:metadata:labels:name: ollamaspec:containers:- name: ollamaimage: ollama/ollama:latestports:- name: httpcontainerPort: 11434protocol: TCPlifecycle:postStart:exec:command: [ "/bin/sh", "-c", "ollama run orca-mini:3b" ] -
Tell Kubernetes to expose these APIs to other containers via a service over
http://ollama.ollama.apiVersion: v1kind: Servicemetadata:name: ollamanamespace: ollamaspec:type: ClusterIPselector:name: ollamaports:- port: 80name: httptargetPort: 11434protocol: TCP -
Now that Ollama is running, we can create our LangChain RAG pipeline with some Python code.
Create the object that will be used to contact Ollama to perform the embedding step. Ollama
orca-mini:3bfor an input returns vectors with a fixed size of 3200. This is why we configured the dimensions property of our Pinecone index to be 3200.from langchain_community.embeddings import OllamaEmbeddingsembeddings = OllamaEmbeddings(model="orca-mini:3b", base_url="http://ollama.ollama") -
Load our documents from our local file system.
In this example, we have several HTML pages of suggestions of what to visit in these cities.
# Retrieve the source datadocs_list = []for item in os.listdir(path="destinations"):if item.endswith(".html"):item_docs_list = BSHTMLLoader(file_path=f"destinations/{item}").load()for item in item_docs_list:docs_list.append(item) -
Split our documents into chunks.
Splitting the text into chunks is important because LLMs have a known limitation called a context window, which defines the boundaries within the model that can process and understand the text. Splitting documents into chunks allows the LLM model to proficiently understand its content and use it to generate the answer.
# Split Document into tokenstext_splitter = RecursiveCharacterTextSplitter()documents = text_splitter.split_documents(docs_list)logger.info("Loading documents from PineCone...")vector = PineconeVectorStore.from_documents(documents,index_name="travel-advisor", # PineCone index to useembedding=embeddings # we're telling LangChain to use Ollama for the embedding step)retriever = vector.as_retriever() -
Initialize the LLM model and wrap the user input into a prompt that locks down the answer expected from the model.
We use a template with two variables:
input: this is filled with the user input textcontext: this is filled with relevant information retrieved from the Pinecone index.
llm = ChatOllama(model="orca-mini:3b", base_url="http://ollama.ollama")prompt = ChatPromptTemplate.from_template("""1. Use the following pieces of context to answer the question as travel advise at the end.2. Keep the answer crisp and limited to 3,4 sentences.Context: {context}Question: {input}Helpful Answer:""")document_prompt = PromptTemplate(input_variables=["page_content", "source"],template="content:{page_content}\nsource:{source}",) -
Piece everything together and create our RAG pipeline.
The pipeline process performs the following steps:
-
Contact Ollama to create an embedding vector for the user input
-
Contact Pinecone to find relevant documents based on the embedding vector
-
Contact Ollama to generate a traveling advisor answer with a prompt that contains context relevant to the user input
document_chain = create_stuff_documents_chain(llm=llm,prompt=prompt,document_prompt=document_prompt,)chain = create_retrieval_chain(retriever, document_chain)response = chain.invoke({"input": prompt}) -
Expand to see a full code example
from langchain_core.prompts import ChatPromptTemplate, PromptTemplatefrom langchain_community.document_loaders import BSHTMLLoaderfrom langchain_community.chat_models import ChatOllamafrom langchain_community.embeddings import OllamaEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom langchain.chains.combine_documents import create_stuff_documents_chainfrom langchain.chains import create_retrieval_chainfrom langchain_pinecone import PineconeVectorStoreimport loggingimport osfrom fastapi import FastAPIfrom fastapi.staticfiles import StaticFilesimport uvicornfrom opentelemetry import tracefrom opentelemetry.sdk.trace import TracerProviderfrom opentelemetry.sdk.resources import Resourcefrom opentelemetry.sdk.trace.export import BatchSpanProcessorfrom opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporterfrom traceloop.sdk import Traceloopfrom traceloop.sdk.decorators import workflowfrom telemetry.token_count import TokenUsageCallbackHandlerfrom telemetry.langchain import LangchainInstrumentor# Read secrets from the mounted volumedef read_token():return read_secret('token')def read_pinecone_key():return read_secret('api-key')def read_secret(secret: str):try:with open(f"/etc/secrets/{secret}", "r") as f:return f.read().rstrip()except Exception as e:print("No token was provided")print(e)return ""# Expose the PineCone key as env var for initialization by LangChainos.environ['PINECONE_API_KEY'] = read_pinecone_key()OTEL_ENDPOINT = os.environ.get("OTEL_ENDPOINT", "http://localhost:4317")OLLAMA_ENDPOINT = os.environ.get("OLLAMA_ENDPOINT", "http://localhost:11434")# GLOBALSAI_MODEL = os.environ.get("AI_MODEL", "orca-mini:3b")AI_SYSTEM = "ollama"AI_EMBEDDING_MODEL = os.environ.get("AI_EMBEDDING_MODEL", "orca-mini:3b")MAX_PROMPT_LENGTH = 50retrieval_chain = None# Initialise the loggerlogging.basicConfig(level=logging.INFO, filename="run.log")logger = logging.getLogger(__name__)# ################# # CONFIGURE OPENTELEMETRYresource = Resource.create({"service.name": "travel-advisor","service.version": "0.1.0"})TOKEN = read_token()headers = {"Authorization": f"Api-Token {TOKEN}"}provider = TracerProvider(resource=resource)processor = BatchSpanProcessor(OTLPSpanExporter(endpoint=f"{OTEL_ENDPOINT}", headers=headers))provider.add_span_processor(processor)trace.set_tracer_provider(provider)otel_tracer = trace.get_tracer("travel-advisor")Traceloop.init(app_name="travel-advisor", api_endpoint=OTEL_ENDPOINT, disable_batch=True, headers=headers)def prep_system():# Create the embeddingembeddings = OllamaEmbeddings(model=AI_EMBEDDING_MODEL, base_url=OLLAMA_ENDPOINT)# Retrieve the source datadocs_list = []for item in os.listdir(path="destinations"):if item.endswith(".html"):item_docs_list = BSHTMLLoader(file_path=f"destinations/{item}").load()for item in item_docs_list:docs_list.append(item)# Split Document into tokenstext_splitter = RecursiveCharacterTextSplitter()documents = text_splitter.split_documents(docs_list)logger.info("Loading documents from PineCone...")vector = PineconeVectorStore.from_documents(documents,index_name="travel-advisor",embedding=embeddings)retriever = vector.as_retriever()logger.info("Initialising Llama LLM...")llm = ChatOllama(model=AI_MODEL, base_url=OLLAMA_ENDPOINT)prompt = ChatPromptTemplate.from_template("""1. Use the following pieces of context to answer the question as travel advise at the end.2. Keep the answer crisp and limited to 3,4 sentences.Context: {context}Question: {input}Helpful Answer:""")document_prompt = PromptTemplate(input_variables=["page_content", "source"],template="content:{page_content}\nsource:{source}",)document_chain = create_stuff_documents_chain(llm=llm,prompt=prompt,document_prompt=document_prompt,)return create_retrieval_chain(retriever, document_chain)############# CONFIGURE ENDPOINTSapp = FastAPI()####################################@app.get("/api/v1/completion")def submit_completion(prompt: str):with otel_tracer.start_as_current_span(name="/api/v1/completion") as span:return submit_completion(prompt, span)@workflow(name="travelgenerator")def submit_completion(prompt: str, span):if prompt:logger.info(f"Calling RAG to get the answer to the question: {prompt}...")response = retrieval_chain.invoke({"input": prompt}, config={"callbacks": [TokenUsageCallbackHandler()],})# Log information for DQL to grablogger.info(f"Response: {response}. Using RAG. model={AI_MODEL}. prompt={prompt}")return {"message": response['answer']}else: # No, or invalid prompt givenspan.add_event(f"No prompt provided or prompt too long (over {MAX_PROMPT_LENGTH} chars)")return {"message": f"No prompt provided or prompt too long (over {MAX_PROMPT_LENGTH} chars)"}####################################@app.get("/api/v1/thumbsUp")@otel_tracer.start_as_current_span("/api/v1/thumbsUp")def thumbs_up(prompt: str):logger.info(f"Positive user feedback for search term: {prompt}")@app.get("/api/v1/thumbsDown")@otel_tracer.start_as_current_span("/api/v1/thumbsDown")def thumbs_down(prompt: str):logger.info(f"Negative user feedback for search term: {prompt}")if __name__ == "__main__":retrieval_chain = prep_system()# Mount static files at the rootapp.mount("/", StaticFiles(directory="./public", html=True), name="public")#app.mount("/destinations", StaticFiles(directory="destinations", html = True), name="destinations")# Run the app using uvicornuvicorn.run(app, host="0.0.0.0", port=8080)
Expand to see a Kubernetes Deployment manifest example
---apiVersion: v1kind: Namespacemetadata:name: travel-advisorlabels:name: travel-advisor---apiVersion: apps/v1kind: Deploymentmetadata:name: travel-advisornamespace: travel-advisorspec:selector:matchLabels:name: travel-advisortemplate:metadata:labels:name: travel-advisorspec:containers:- name: travel-advisorimage: travel-advisor:v0.1.3ports:- name: httpcontainerPort: 8080protocol: TCPenv:- name: OTEL_ENDPOINTvalue: "https://<YOUR_ENV>.live.dynatrace.com/api/v2/otlp"- name: OLLAMA_ENDPOINTvalue: "http://ollama.ollama"- name: TRACELOOP_TELEMETRYvalue: "false"imagePullPolicy: AlwaysvolumeMounts:- name: secretsreadOnly: truemountPath: "/etc/secrets"volumes:- name: secretsprojected:sources:- secret:name: dynatrace- secret:name: pinecone---apiVersion: v1kind: Servicemetadata:name: travel-advisornamespace: travel-advisorspec:type: LoadBalancerselector:name: travel-advisorports:- port: 80name: httptargetPort: 8080protocol: TCP
 Observe your RAG pipeline
Observe your RAG pipeline
We have presented a simple RAG pipeline for this example, but it already contains a lot of hidden communication with external services. Comprehensive observability is mandatory to control the performance, costs, and quality of the response provided by the LLM.
Luckily, we don't need to manually instrument our code base and collect essential signals. We can leverage OpenTelemetry to provide traces and metrics, particularly OpenLLMetry.
-
Add the following line to our code and we can harness the power of Dynatrace to monitor our AI workloads.
headers = { "Authorization": "Api-Token <YOUR_DT_API_TOKEN>" }Traceloop.init(app_name="travel-advisor",api_endpoint="https://<YOUR_ENV>.live.dynatrace.com/api/v2/otlp",disable_batch=True,headers=headers)And that's it!

-
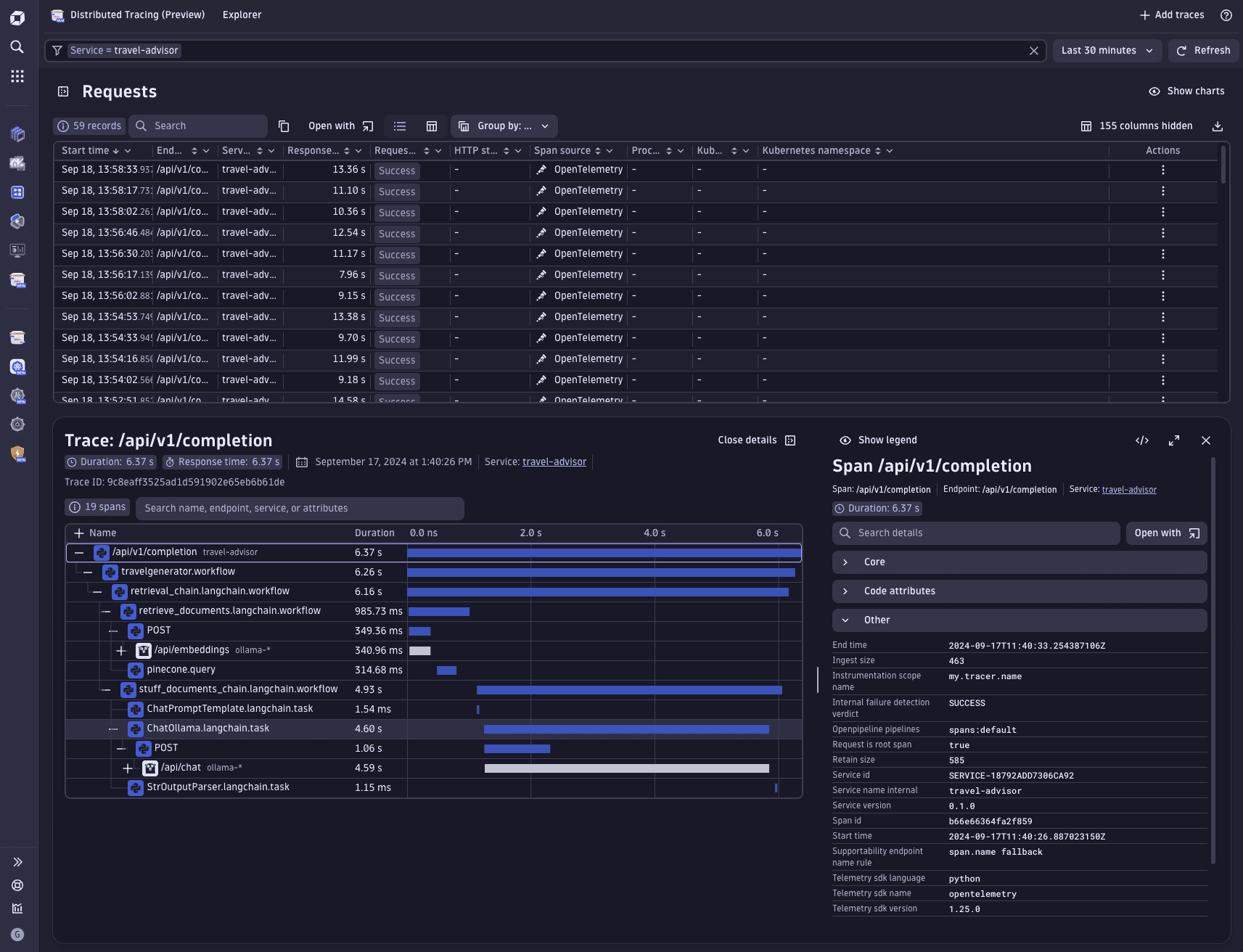
We can now see traces that describe each step taken by the LangChain RAG pipeline and identify bottlenecks, improvements, or monitor if a service is not reachable anymore.
Dynatrace screenshot
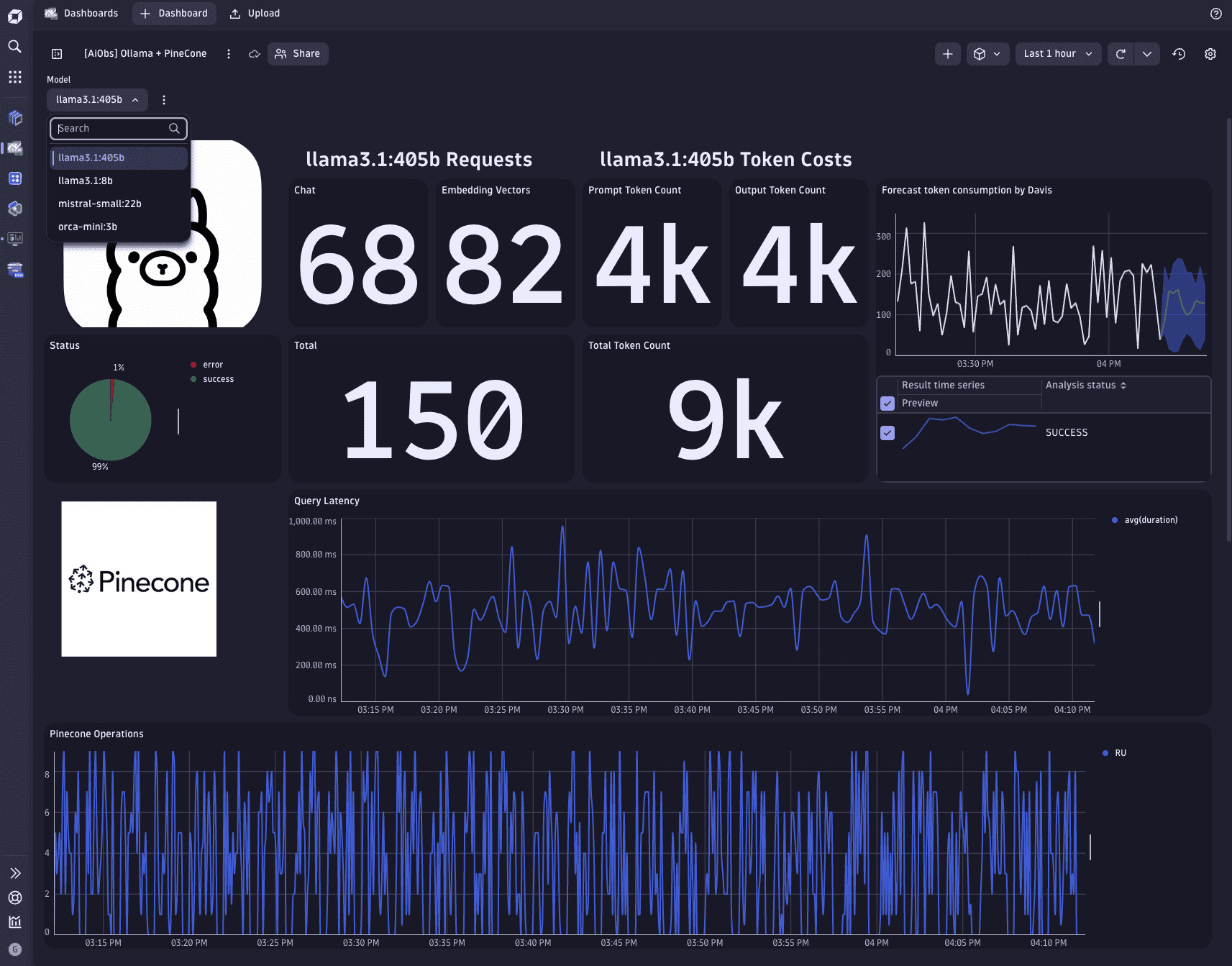
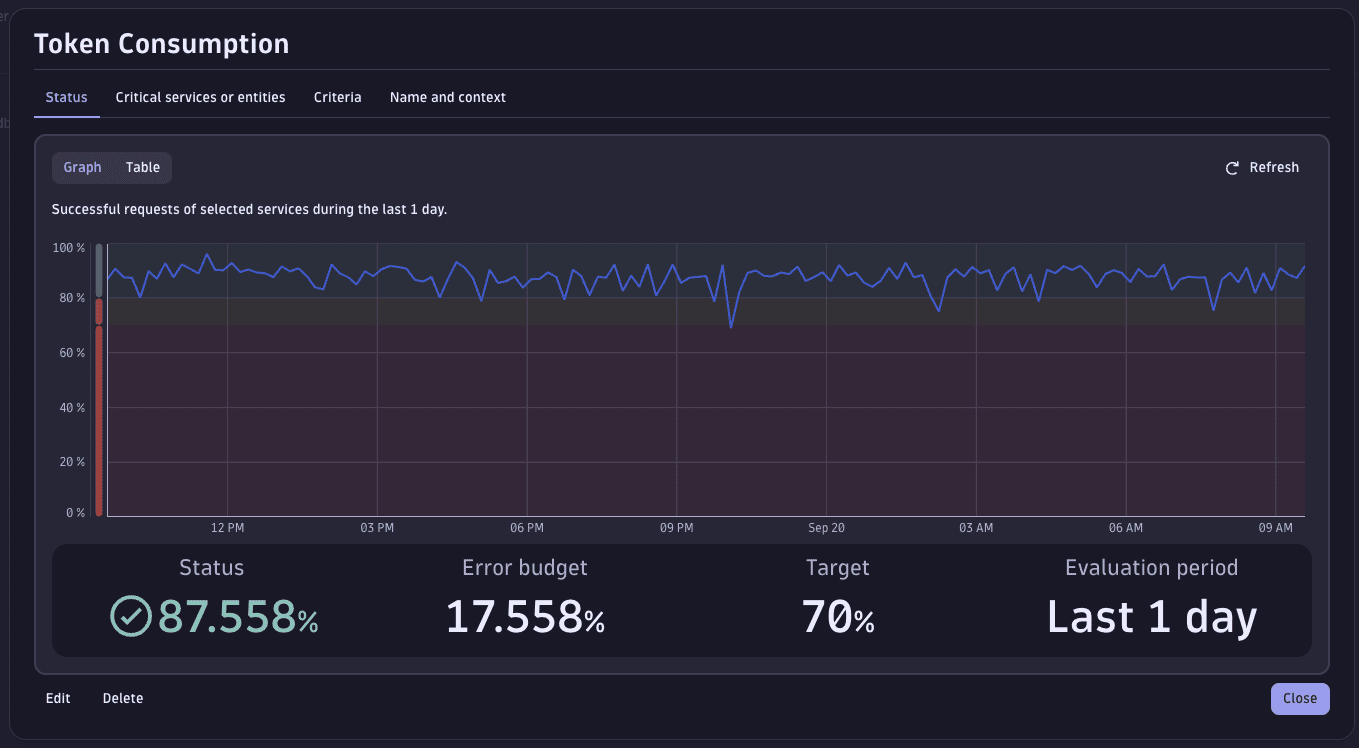
However, just a trace is not enough to assess the health status of our AI workloads. To this end, we can configure dashboards that display important metrics of our services. For example, we can monitor the amount of input/output tokens or the latency of our services, or configure SLOs for when token consumption reaches a threshold.
OpenTelemetry offers a GenAI Semantic Convention that can be used to write DQL queries to chart important signals of our AI workloads. The relevant attributes for this domain start with the gen_ai prefix.
For example, we can list the names of the models used.
fetch spans| summarize models = collectDistinct(gen_ai.request.model)| expand models| sort models
Example of SLO alerting based on token consumption
fetch spans| filter gen_ai.response.model == "orca-mini:3b"| makeTimeseries total = max(gen_ai.usage.output_tokens + gen_ai.usage.input_tokens), baseline = avg(gen_ai.usage.output_tokens + gen_ai.usage.input_tokens)| fieldsAdd sli = (baseline[]/total[])*100| fieldsRemove baseline, total
Example of charting response time for different LLM invocation types
fetch spans| filter gen_ai.request.model == "orca-mini:3b" and llm.request.type != ""| fieldsKeep duration, gen_ai.request.model, llm.request.type, end_time| makeTimeseries avg(duration), time: end_time, by: {llm.request.type}| append [fetch spans| filter gen_ai.request.model == "orca-mini:3b" and llm.request.type != ""| makeTimeseries requests=count()]
Example of confronting input and response prompt
fetch spans| filter gen_ai.request.model == "orca-mini:3b" and llm.request.type == "chat"| fieldsAdd prompt = gen_ai.prompt.0.content| fieldsAdd response = gen_ai.completion.0.content| fields prompt, response
The following example dashboard visualizes important health metrics of the travel-advisor application.